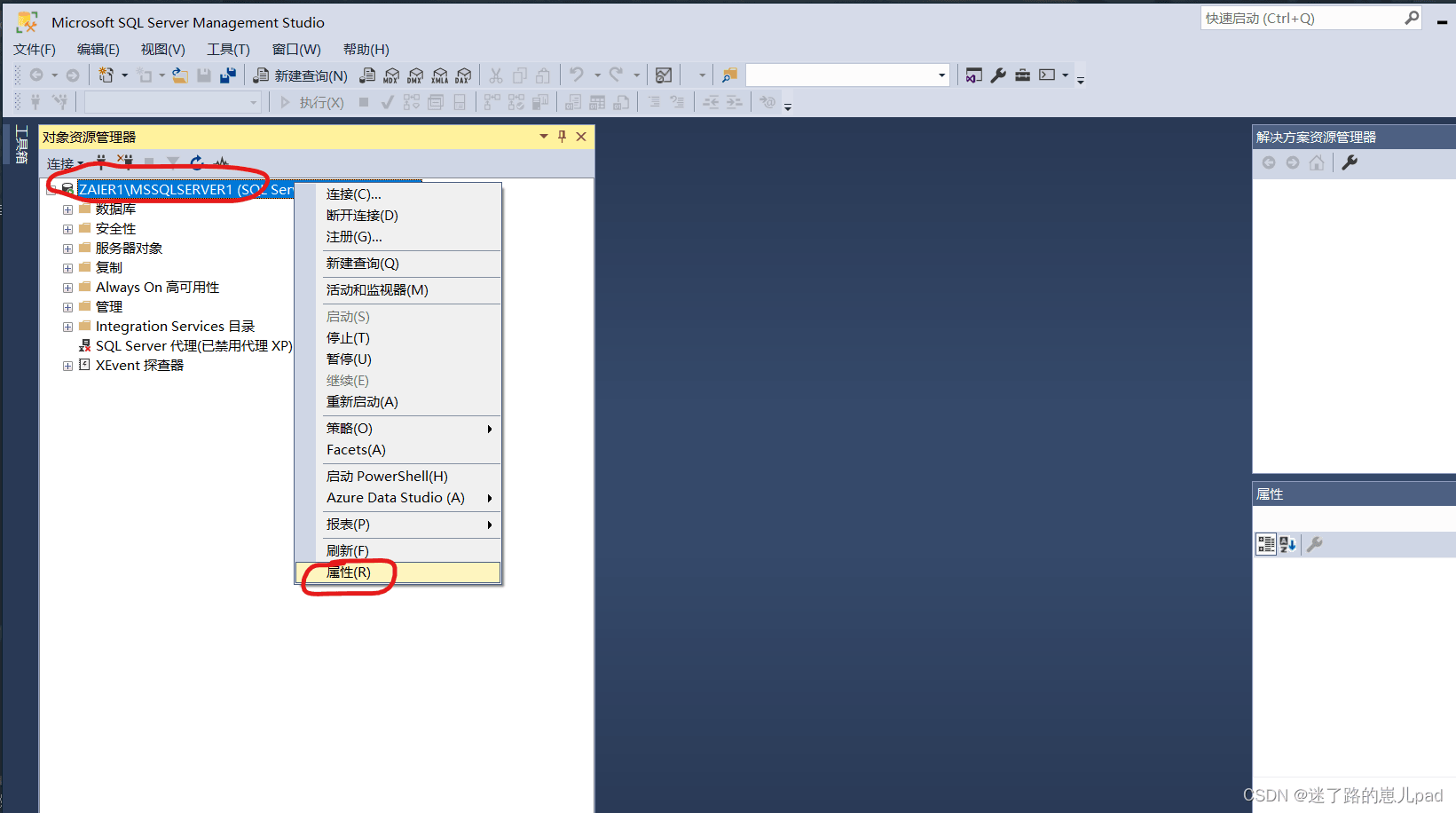
我们在进行项目开发中,经常会遇到多条件模糊查询的需求。对此,我们常见的解决方案有两种:一是在程序端拼接SQL字符串,根据是否选择了某个条件,构造相应的SQL字符串;二是在数据库的存储过程中使用动态的SQL语句。其本质也是拼接SQL字符串,不过是从程序端转移到数据库端而已。
这两种方式的缺点是显而易见的:一是当多个条件每个都可为空时,要使用多个if语句进行判断;二是拼接的SQL语句容易产生SQL注入漏洞。
最近写数据库存储过程的时候经常使用case when 语句,正好可以用这个语句解决一下以上问题。以SQL中的NorthWind数据库为例,我要操作的是其中的Employees表,该表中默认数据如下:
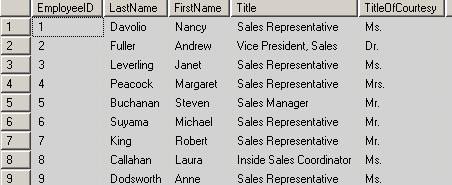
使用如下脚本来查询表中数据:
代码
DECLARE @FirstName NVARCHAR(),
@LastName NVARCHAR();
SELECT @FirstName = '',
@LastName = '';
SELECT *
FROM Employees c
WHERE CHARINDEX(
(
CASE
WHEN @FirstName = '' THEN FirstName
ELSE @FirstName
END
),
FirstName
) >
AND CHARINDEX(
(CASE WHEN @LastName = '' THEN LastName ELSE @LastName END),
LastName
) >
执行后会发现查出的结果和图1一样。
我们把第二行的@FirstName变量赋值为'n'试试,会把所有FirstName字段中包含字符串'n'的记录查出来,如下图:

如果我们再把第三行的@LastName变量赋值为"d'试试,结果会把所有FirstName字段包含'n'并且LastName字段包含'd'的记录查出来,如下图:

通过以上例子我们可以看到,通过给两个变量传递不同的值,就可以根据多条件进行模糊查询了,如果把上面的语句写在存储过程中,就可以不必再拼接SQL语句了,也不会出现注入式问题了。
以上脚本的简单说明:用charindex函数替换like,避免拼接sql语句;使用case when 语句,当传递的参数值为空字符串时让条件始终为真,即等于忽略该条件,不为空串时按参数值模糊查询。
以上是工作中的经验总结,希望对大家有帮助。有关case when还有一些比较实用的用法,有时间的话再写写。
下面给大家介绍SQL CASE 多条件用法
Case具有两种格式。简单Case函数和Case搜索函数。
--简单Case函数
CASE sex
WHEN '' THEN '男'
WHEN '' THEN '女'
ELSE '其他' END
--Case搜索函数
CASE WHEN sex = '' THEN '男'
WHEN sex = '' THEN '女'
ELSE '其他' END
这两种方式,可以实现相同的功能。简单Case函数的写法相对比较简洁,但是和Case搜索函数相比,功能方面会有些限制,比如写判断式。
还有一个需要注意的问题,Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略。
--比如说,下面这段SQL,你永远无法得到“第二类”这个结果
CASE WHEN col_ IN ( 'a', 'b') THEN '第一类'
WHEN col_ IN ('a') THEN '第二类'
ELSE'其他' END
下面我们来看一下,使用Case函数都能做些什么事情。
一,已知数据按照另外一种方式进行分组,分析。
有如下数据:(为了看得更清楚,我并没有使用国家代码,而是直接用国家名作为Primary Key)
国家(country) 人口(population)
中国
美国
加拿大
英国
法国
日本
德国
墨西哥
印度
根据这个国家人口数据,统计亚洲和北美洲的人口数量。应该得到下面这个结果。
洲 人口
亚洲
北美洲
其他
想要解决这个问题,你会怎么做?生成一个带有洲Code的View,是一个解决方法,但是这样很难动态的改变统计的方式。
如果使用Case函数,SQL代码如下:
SELECT SUM(population),
CASE country
WHEN '中国' THEN '亚洲'
WHEN '印度' THEN '亚洲'
WHEN '日本' THEN '亚洲'
WHEN '美国' THEN '北美洲'
WHEN '加拿大' THEN '北美洲'
WHEN '墨西哥' THEN '北美洲'
ELSE '其他' END
FROM Table_A
GROUP BY CASE country
WHEN '中国' THEN '亚洲'
WHEN '印度' THEN '亚洲'
WHEN '日本' THEN '亚洲'
WHEN '美国' THEN '北美洲'
WHEN '加拿大' THEN '北美洲'
WHEN '墨西哥' THEN '北美洲'
ELSE '其他' END;
同样的,我们也可以用这个方法来判断工资的等级,并统计每一等级的人数。SQL代码如下;
SELECT
CASE WHEN salary <= THEN ''
WHEN salary > AND salary <= THEN ''
WHEN salary > AND salary <= THEN ''
WHEN salary > AND salary <= THEN ''
ELSE NULL END salary_class,
COUNT(*)
FROM Table_A
GROUP BY
CASE WHEN salary <= THEN ''
WHEN salary > AND salary <= THEN ''
WHEN salary > AND salary <= THEN ''
WHEN salary > AND salary <= THEN ''
ELSE NULL END;
二,用一个SQL语句完成不同条件的分组。
有如下数据
国家(country) 性别(sex) 人口(population)
中国
中国
美国
美国
加拿大
加拿大
英国
英国
按照国家和性别进行分组,得出结果如下
国家 男 女
中国
美国
加拿大
英国
普通情况下,用UNION也可以实现用一条语句进行查询。但是那样增加消耗(两个Select部分),而且SQL语句会比较长。
下面是一个是用Case函数来完成这个功能的例子
SELECT country,
SUM( CASE WHEN sex = '' THEN
population ELSE END), --男性人口
SUM( CASE WHEN sex = '' THEN
population ELSE END) --女性人口
FROM Table_A
GROUP BY country;
这样我们使用Select,完成对二维表的输出形式,充分显示了Case函数的强大。
三,在Check中使用Case函数。
在Check中使用Case函数在很多情况下都是非常不错的解决方法。可能有很多人根本就不用Check,那么我建议你在看过下面的例子之后也尝试一下在SQL中使用Check。
下面我们来举个例子
公司A,这个公司有个规定,女职员的工资必须高于块。如果用Check和Case来表现的话,如下所示
CONSTRAINT check_salary CHECK
( CASE WHEN sex = ''
THEN CASE WHEN salary >
THEN ELSE END
ELSE END = )
如果单纯使用Check,如下所示
CONSTRAINT check_salary CHECK
( sex = '' AND salary > )
女职员的条件倒是符合了,男职员就无法输入了。
****我的一个示例:<br>SELECT (CASE WHEN t.name='name' THEN 'ok' ELSE 'no' END) AS myCom, jname FROM t<br>定义一个新的字段,此字段用来显示字段结果的不同显示结果,似于switch...case