人来到这世界后,命运注定了他必须要拼搏,奋斗,坚持,勇敢地走下去,走出属于自己的道路,没有人能不劳而获。
--创建测试表
CREATE TABLE [dbo].[testtab](
[id] [nchar](10) NULL,
[name] [nchar](10) NULL
) ;
--向测试表插入测试数据
insert into testtab values('1','1');
insert into testtab values('1','1');
insert into testtab values('2','2');
insert into testtab values('2','2');
insert into testtab values('3','3');
insert into testtab values('3','3');
--创建临时表并向临时表中插入测试表testtab中数据以及添加自增id:autoID
select identity(int,1,1) as autoID, * into #Tmp from testtab
--根据autoID删除临时表#tmp中的重复数据,只保留每组重复数据中的第一条
delete #Tmp where autoID in(select max(autoID) from #Tmp group by id);
--清除testtab表中的所有数据
delete testtab;
--向testtab表中插入#Tmp表中被处理过的数据
insert into testtab select id,name from #Tmp;
--删除临时表#Tmp
drop table #Tmp;
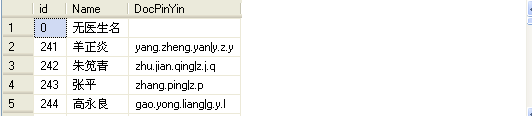
以上就是sqlserver清除完全重复的数据只保留重复数据中的第一条。老一代人完全不用担心小辈们会在你们的路上跌倒,因为他们走的根本是另一条路。更多关于sqlserver清除完全重复的数据只保留重复数据中的第一条请关注haodaima.com其它相关文章!