一、概述
SQL SERVER2012 之前版本,一般采用GUID或者IDENTITY来作为标示符。在2012中,微软终于增加了 SEQUENCE 对象,功能和性能都有了很大的提高。
序列是一种用户定义的架构绑定对象,它根据创建该序列时采用的规范生成一组数值。 这组数值以定义的间隔按升序或降序生成,并且可根据要求循环(重复)。
- 序列不与表相关联,这一点与标识列不同。
- 应用程序将引用某一序列对象以便接收其下一个值。
- 序列是通过使用 CREATE SEQUENCE 语句独立于表来创建的。 其选项使您可以控制增量、最大值和最小值、起始点、自动重新开始功能和缓存以便改进性能。
- 与在插入行时生成的标识列值不同,应用程序可以通过调用 NEXT VALUE FOR 函数在插入行之前获取下一序列号。 在调用 NEXT VALUE FOR 时分配该序列号,即使在该序列号永远也不插入某个表中时也是如此。 此 NEXT VALUE FOR 函数可用作表定义中某个列的默认值。
- 使用 sp_sequence_get_range 可一次获取某个范围的多个序列号。
- 序列可定义为任何整数数据类型。 如tinyint, smallint, int, bigint, decimal 或是小数精度为0的数值类型。如果未指定数据类型,则序列将默认为
bigint。
序列的限制(limitation)有二个
- 序列不支持事务,即使事务中进行了回滚(rollback)操作,序列仍然返回下一个元素。
- 序列不支持SQL Server 复制(replication),序列不会复制到订阅的SQL Server实例中。如果一个表的默认值依赖一个序列,而序列又是不可复制的,这会导致订阅的SQL Server出现脚本错误。
选择使用序列的情况:
在以下情况下将使用序列,而非标识列:
- 应用程序要求在插入到表中之前有一个数值。
- 应用程序要求在多个表之间或者某个表内的多个列之间共享单个数值系列。
- 在达到指定的数值时,应用程序必须重新开始该数值系列。 例如,在分配值 1 到 10 后,应用程序再次开始分配值 1 到 10。
- 应用程序要求序列值按其他字段排序。 NEXT VALUE FOR 函数可以将 OVER 子句应用于该函数调用。 OVER 子句确保返回的值按照 OVER 子句的 ORDER BY 子句的顺序生成。
- 应用程序要求同时分配多个数值。 例如,应用程序需要保留五个序号。 如果正在同时向其他进程发出数值,则请求标识值可能会导致在系列中出现间断。 调用 sp_sequence_get_range 可以一次检索该序列中的若干数值。
- 您需要更改序列的规范,例如增量值。
二、创建序列:CREATE SEQUENCE
我们可以在SSMS中创建也可以使用SQL SERVER脚本创建序列对象:
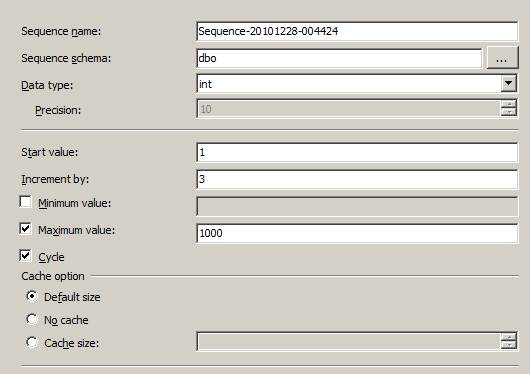
1、使用默认值创建序列:若要创建从 -2,147,483,648 到 2,147,483,647 且增量为 1 的整数序列号。
CREATE SEQUENCE Schema.SequenceName
AS int
INCREMENT BY 1 ;2、若要创建类似于从 1 到 2,147,483,647 且增量为 1 的标识列的整数序列号,请使用以下语句。
CREATE SEQUENCE Schema.SequenceName
AS int
START WITH 1
INCREMENT BY 1 ;3、使用所有参数创建序列
以下示例使用 decimal 数据类型(范围为 0 到 255)创建一个名为 DecSeq 的序列 。 序列以 125 开始,每次生成数字时递增 25。 因为该序列配置为可循环,所以,当值超过最大值 200 时,序列将从最小值 100 重新开始。
CREATE SEQUENCE Test.DecSeq
AS decimal(3,0)
START WITH 125
INCREMENT BY 25
MINVALUE 100
MAXVALUE 200
CYCLE
CACHE 3 ;二、使用序列号:NEXT VALUE FOR
执行以下语句可查看第一个值;START WITH 选项为 125。将该语句再执行三次,以返回 150、175 和 200。再次执行该语句,以查看起始值如何循环回到 MINVALUE选项值 100。
SELECT NEXT VALUE FOR Test.DecSeq;
1、序列值插入到表中
下面的示例创建一个名为 Test 的架构、一个名为 Orders 的表以及一个名为 CountBy1 的序列,然后使用 NEXT VALUE FOR 函数将行插入到该表中。
--Create the Test schema
CREATE SCHEMA Test ;
GO
-- Create a table
CREATE TABLE Test.Orders
(OrderID int PRIMARY KEY,
Name varchar(20) NOT NULL,
Qty int NOT NULL);
GO
-- Create a sequence
CREATE SEQUENCE Test.CountBy1
START WITH 1
INCREMENT BY 1 ;
GO
-- Insert three records
INSERT Test.Orders (OrderID, Name, Qty)
VALUES (NEXT VALUE FOR Test.CountBy1, 'Tire', 2) ;
INSERT test.Orders (OrderID, Name, Qty)
VALUES (NEXT VALUE FOR Test.CountBy1, 'Seat', 1) ;
INSERT test.Orders (OrderID, Name, Qty)
VALUES (NEXT VALUE FOR Test.CountBy1, 'Brake', 1) ;
GO
-- View the table
SELECT * FROM Test.Orders ;
GO下面是结果集:
OrderID Name Qty
1 Tire 2
2 Seat 1
3 Brake 1
2、在select 语句中使用 NEXT VALUE FOR 。
SELECT NEXT VALUE FOR CountBy5 AS SurveyGroup, Name FROM sys.objects ;
3、通过使用 OVER 子句为结果集生成序列号
SELECT NEXT VALUE FOR Samples.IDLabel OVER (ORDER BY Name) AS NutID, ProductID, Name, ProductNumber FROM Production.Product WHERE Name LIKE '%nut%' ;
4、sp_sequence_get_range:同时获取多个序列号
从序列对象中返回一系列序列值。 序列对象生成和发出请求的值数目,并为应用程序提供与该系列序列值相关的元数据。
以下语句从 RangeSeq 序列对象中获取四个序列号,并向用户返回过程中的所有输出值。
DECLARE @range_first_value_output sql_variant ; EXEC sys.sp_sequence_get_range @sequence_name = N'Test.RangeSeq' , @range_size = 4 , @range_first_value = @range_first_value_output OUTPUT ; SELECT @range_first_value_output AS FirstNumber ;
5、将表从标识更改为序列
下面的示例创建一个包含该示例的三行的架构和表。 然后,该示例添加一个新列并且删除旧列。
使用 Transact-SQL 的 SELECT * 语句将这个新列作为最后一列接收,而非作为第一列接收。 如果这样做是不可接受的,则您必须创建全新的表,将数据移到该表中,然后针对这个新表重新创建权限。
-- 添加没有IDENTITY属性的新列
ALTER TABLE Test.Department
ADD DepartmentIDNew smallint NULL
GO
-- 将值从旧列复制到新列
UPDATE Test.Department
SET DepartmentIDNew = DepartmentID ;
GO
-- 删除旧列上的主键约束
ALTER TABLE Test.Department
DROP CONSTRAINT [PK_Department_DepartmentID];
-- 删除旧列
ALTER TABLE Test.Department
DROP COLUMN DepartmentID ;
GO
-- 将新列重命名为旧列名
EXEC sp_rename 'Test.Department.DepartmentIDNew',
'DepartmentID', 'COLUMN';
GO
-- 将新列更改为NOT NULL
ALTER TABLE Test.Department
ALTER COLUMN DepartmentID smallint NOT NULL ;
-- 添加唯一的主键约束
ALTER TABLE Test.Department
ADD CONSTRAINT PK_Department_DepartmentID PRIMARY KEY CLUSTERED
(DepartmentID ASC) ;
-- 从DepartmentID列中获取当前的最高值,并创建一个用于列的序列。(返回3。)
SELECT MAX(DepartmentID) FROM Test.Department ;
--使用下一个期望值(4)作为START WITH VALUE;
CREATE SEQUENCE Test.DeptSeq
AS smallint
START WITH 4
INCREMENT BY 1 ;
GO
-- 为DepartmentID列添加一个默认值
ALTER TABLE Test.Department
ADD CONSTRAINT DefSequence DEFAULT (NEXT VALUE FOR Test.DeptSeq) FOR DepartmentID;
GO
-- 查看结果
SELECT DepartmentID, Name, GroupName FROM Test.Department ;
-- Test insert
INSERT Test.Department (Name, GroupName) VALUES ('Audit', 'Quality Assurance') ;
GO
-- 查看结果
SELECT DepartmentID, Name, GroupName FROM Test.Department ;
GO三、管理序列
1、更新(重置)序列:ALTER SEQUENCE
重新开始 Samples.IDLabel 序列。
ALTER SEQUENCE Samples.IDLabel RESTART WITH 1 ;
2、DROP SEQUENCE:删除序列
在生成编号后,序列对象与其生成的编号之间没有延续关系,因此可以删除序列对象,即使生成的编号仍在使用。
当序列对象由存储过程或触发器引用时,可以删除序列对象,因为序列对象未绑定到架构上。 如果序列对象是作为表中的默认值引用的,则无法删除序列对象。 错误消息将列出引用序列的对象。
以下示例从当前数据库中删除一个名为 CountBy1 的序列对象。
DROP SEQUENCE CountBy1 ;
3、查看序列信息
有关序列的信息,请查询 sys.sequences。
执行以下代码,以确认缓存大小并查看当前值。
SELECT cache_size, current_value FROM sys.sequences WHERE name = 'DecSeq' ;
到此这篇关于SQL Server序列SEQUENCE的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持好代码网。