1 导引
我们在博客《Hadoop: 单词计数(Word Count)的MapReduce实现 》中学习了如何用Hadoop-MapReduce实现单词计数,现在我们来看如何用Spark来实现同样的功能。
2. Spark的MapReudce原理
Spark框架也是MapReduce-like模型,采用“分治-聚合”策略来对数据分布进行分布并行处理。不过该框架相比Hadoop-MapReduce,具有以下两个特点:
- 对大数据处理框架的输入/输出,中间数据进行建模,将这些数据抽象为统一的数据结构命名为弹性分布式数据集(Resilient Distributed Dataset),并在此数据结构上构建了一系列通用的数据操作,使得用户可以简单地实现复杂的数据处理流程。
- 采用了基于内存的数据聚合、数据缓存等机制来加速应用执行尤其适用于迭代和交互式应用。
Spark社区推荐用户使用Dataset、DataFrame等面向结构化数据的高层API(Structured API)来替代底层的RDD API,因为这些高层API含有更多的数据类型信息(Schema),支持SQL操作,并且可以利用经过高度优化的Spark SQL引擎来执行。不过,由于RDD API更基础,更适合用来展示基本概念和原理,后面我们的代码都使用RDD API。
Spark的RDD/dataset分为多个分区。RDD/Dataset的每一个分区都映射一个或多个数据文件, Spark通过该映射读取数据输入到RDD/dataset中。
因为我们这里采用的本地单机多线程调试模式,默认分区数即为本地机器使用的线程数,若在代码中设置了local[N](使用N个线程),则默认为N个分区;若设为local[*](使用本地CPU核数个线程),则默认分区数为本地CPU核数。大家可以通过调用RDD对象的getNumPartitions()查看实际分区个数。
我们下面的流程描述中,假设每个文件对应一个分区。
Spark的Map示意图如下:
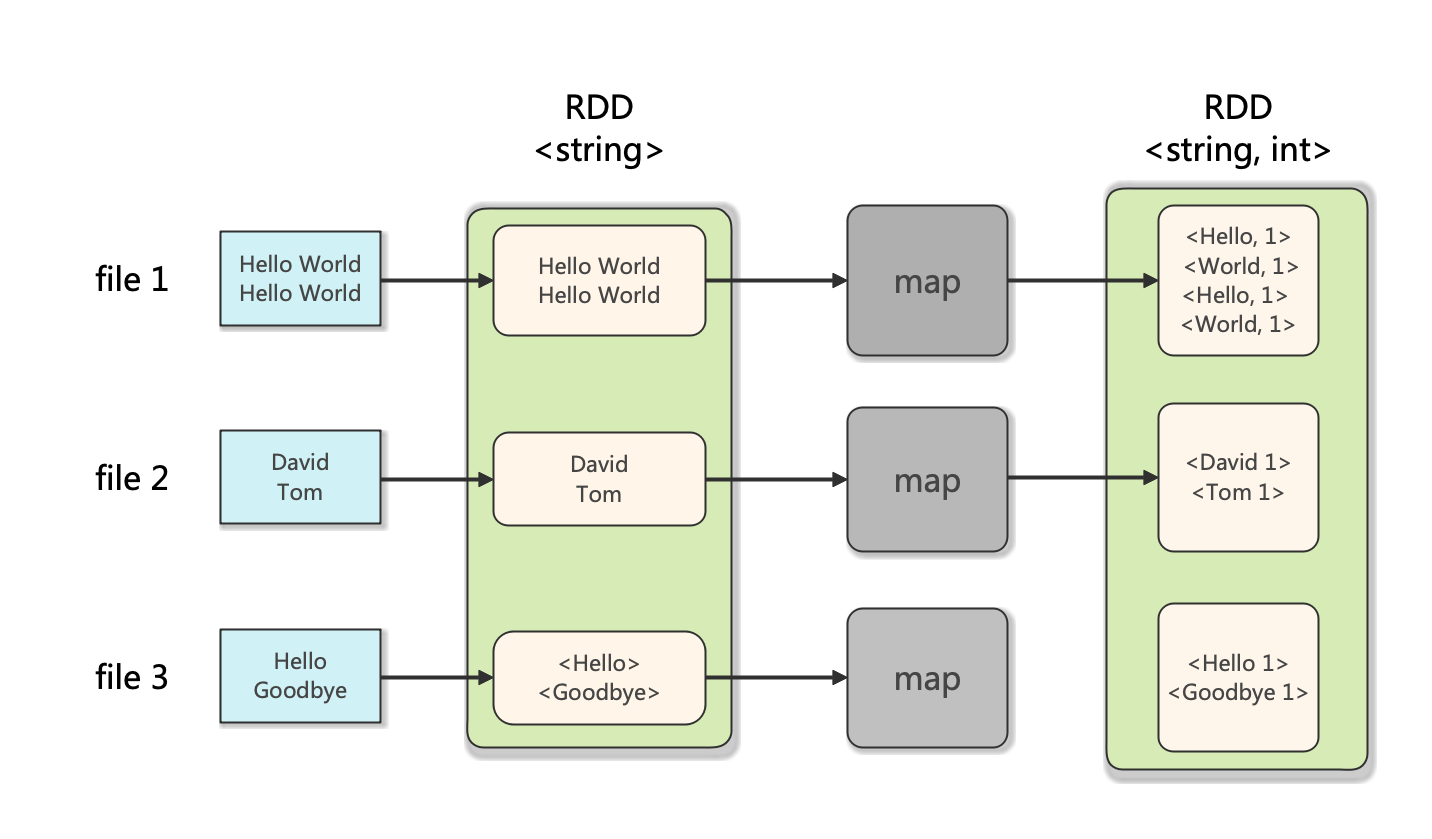
Spark的Reduce示意图如下:

3. Word Count的Java实现
项目架构如下图:
Word-Count-Spark
├─ input
│ ├─ file1.txt
│ ├─ file2.txt
│ └─ file3.txt
├─ output
│ └─ result.txt
├─ pom.xml
├─ src
│ ├─ main
│ │ └─ java
│ │ └─ WordCount.java
│ └─ test
└─ target
WordCount.java文件如下:
package com.orion;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern;
import java.io.*;
import java.nio.file.*;
public class WordCount {
private static Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
if (args.length != 3) {
System.err.println("Usage: WordCount <intput directory> <output directory> <number of local threads>");
System.exit(1);
}
String input_path = args[0];
String output_path = args[1];
int n_threads = Integer.parseInt(args[2]);
SparkSession spark = SparkSession.builder()
.appName("WordCount")
.master(String.format("local[%d]", n_threads))
.getOrCreate();
JavaRDD<String> lines = spark.read().textFile(input_path).javaRDD();
JavaRDD<String> words = lines.flatMap(s -> Arrays.asList(SPACE.split(s)).iterator());
JavaPairRDD<String, Integer> ones = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairRDD<String, Integer> counts = ones.reduceByKey((i1, i2) -> i1 + i2);
List<Tuple2<String, Integer>> output = counts.collect();
String filePath = Paths.get(output_path, "result.txt").toString();
BufferedWriter out = new BufferedWriter(new FileWriter(filePath));
for (Tuple2<?, ?> tuple : output) {
out.write(tuple._1() + ": " + tuple._2() + "\n");
}
out.close();
spark.stop();
}
}
pom.xml文件配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.WordCount</groupId>
<artifactId>WordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<name>WordCount</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<!-- 集中定义版本号 -->
<properties>
<scala.version>2.12.10</scala.version>
<scala.compat.version>2.12</scala.compat.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<project.timezone>UTC</project.timezone>
<java.version>11</java.version>
<scoverage.plugin.version>1.4.0</scoverage.plugin.version>
<site.plugin.version>3.7.1</site.plugin.version>
<scalatest.version>3.1.2</scalatest.version>
<scalatest-maven-plugin>2.0.0</scalatest-maven-plugin>
<scala.maven.plugin.version>4.4.0</scala.maven.plugin.version>
<maven.compiler.plugin.version>3.8.0</maven.compiler.plugin.version>
<maven.javadoc.plugin.version>3.2.0</maven.javadoc.plugin.version>
<maven.source.plugin.version>3.2.1</maven.source.plugin.version>
<maven.deploy.plugin.version>2.8.2</maven.deploy.plugin.version>
<nexus.staging.maven.plugin.version>1.6.8</nexus.staging.maven.plugin.version>
<maven.help.plugin.version>3.2.0</maven.help.plugin.version>
<maven.gpg.plugin.version>1.6</maven.gpg.plugin.version>
<maven.surefire.plugin.version>2.22.2</maven.surefire.plugin.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<spark.version>3.2.1</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!--======SCALA======-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
<plugins>
<!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle -->
<plugin>
<artifactId>maven-clean-plugin</artifactId>
<version>3.1.0</version>
</plugin>
<!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging -->
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.1</version>
</plugin>
<plugin>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-install-plugin</artifactId>
<version>2.5.2</version>
</plugin>
<plugin>
<artifactId>maven-deploy-plugin</artifactId>
<version>2.8.2</version>
</plugin>
<!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle -->
<plugin>
<artifactId>maven-site-plugin</artifactId>
<version>3.7.1</version>
</plugin>
<plugin>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.0.0</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>11</source>
<target>11</target>
<fork>true</fork>
<executable>/Library/Java/JavaVirtualMachines/jdk-11.0.15.jdk/Contents/Home/bin/javac</executable>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>记得配置输入参数input、output、3分别代表输入目录、输出目录和使用本地线程数(在VSCode中在launch.json文件中配置)。编译运行后可在output目录下查看result.txt:
Tom: 1
Hello: 3
Goodbye: 1
World: 2
David: 1
可见成功完成了单词计数功能。
4. Word Count的Python实现
先使用pip按照pyspark==3.8.2:
pip install pyspark==3.8.2
注意PySpark只支持Java 8/11,请勿使用更高级的版本。这里我使用的是Java 11。运行java -version可查看本机Java版本。
(base) orion-orion@MacBook-Pro ~ % java -version
java version "11.0.15" 2022-04-19 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.15+8-LTS-149)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.15+8-LTS-149, mixed mode)
项目架构如下:
Word-Count-Spark
├─ input
│ ├─ file1.txt
│ ├─ file2.txt
│ └─ file3.txt
├─ output
│ └─ result.txt
├─ src
│ └─ word_count.py
word_count.py编写如下:
from pyspark.sql import SparkSession
import sys
import os
from operator import add
if len(sys.argv) != 4:
print("Usage: WordCount <intput directory> <output directory> <number of local threads>", file=sys.stderr)
exit(1)
input_path, output_path, n_threads = sys.argv[1], sys.argv[2], int(sys.argv[3])
spark = SparkSession.builder.appName("WordCount").master("local[%d]" % n_threads).getOrCreate()
lines = spark.read.text(input_path).rdd.map(lambda r: r[0])
counts = lines.flatMap(lambda s: s.split(" "))\
.map(lambda word: (word, 1))\
.reduceByKey(add)
output = counts.collect()
with open(os.path.join(output_path, "result.txt"), "wt") as f:
for (word, count) in output:
f.write(str(word) +": " + str(count) + "\n")
spark.stop()
使用python word_count.py input output 3运行后,可在output中查看对应的输出文件result.txt:
Hello: 3
World: 2
Goodbye: 1
David: 1
Tom: 1
可见成功完成了单词计数功能。
到此这篇关于基于Python和Java实现单词计数(Word Count)的文章就介绍到这了,更多相关Python Java单词计数内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!