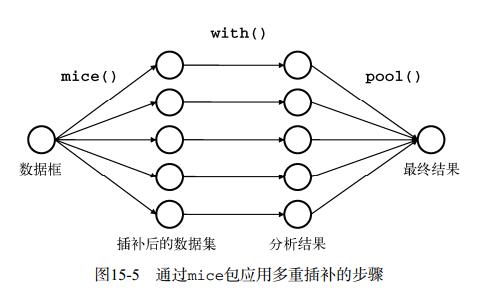
既然了解了R语言的基本数据类型,那么如何将庞大的数据送入R语言进行处理呢?送入的数据又是如何在R语言中进行存储的呢?处理这些数据的方法又有那些呢?下面我们一起来探讨一下。
首先,数据输入最直接最直观的方法就是键盘输入,在上面几篇都已经讲到,利用c创建向量,利用matrix创建矩阵,利用data.frame创建数据框等,但是我们处理的数据往往比较多,键盘输入在面对如此庞大的数据时显然不现实,当然你可以花费好几天来输入数据而且保证不出错除外,而且待处理的一般都存储在Excel,网页,数据库其他中介中,因此:如何大批量无差错高效率地读取数据就成为R语言首先要解决的问题。
第一:如果自己学习写代码,加载R语言中本身自带的数据包cars等,加载的方法跟其他包相同,具体代码如下:
> install.packages("car")
> library(cars)
第二:读取外部数据一般用read.***( ),***代表要读取的文件类型,下面详细解释了每种类型的文件的读取:
read.table(file, header = FALSE, sep = "", quote = "\"'",
dec = ".", numerals = c("allow.loss", "warn.loss", "no.loss"),
row.names, col.names, as.is = !stringsAsFactors,
na.strings = "NA", colClasses = NA, nrows = -1,
skip = 0, check.names = TRUE, fill = !blank.lines.skip,
strip.white = FALSE, blank.lines.skip = TRUE,
comment.char = "#",
allowEscapes = FALSE, flush = FALSE,
stringsAsFactors = default.stringsAsFactors(),
fileEncoding = "", encoding = "unknown", text, skipNul = FALSE)
read.csv(file, header = TRUE, sep = ",", quote = "\"",
dec = ".", fill = TRUE, comment.char = "", ...)
read.csv2(file, header = TRUE, sep = ";", quote = "\"",
dec = ",", fill = TRUE, comment.char = "", ...)
read.delim(file, header = TRUE, sep = "\t", quote = "\"",
dec = ".", fill = TRUE, comment.char = "", ...)
read.delim2(file, header = TRUE, sep = "\t", quote = "\"",
dec = ",", fill = TRUE, comment.char = "", ...)
其中:
参数file:代表要读去的文件名以及文件路径,如果当前工作路径就是需要读取的文件的存储路径,那么可以直接写文件名,记得要用双引号括起来。那么如何设置工作路径呢?首先我们查看当前的工作路径用getwd( )函数,设置工作路径的话用setwd(" 工作路径")函数,注意,在设置工作路径时,需要把路径中所有的 "\" 改成 “\\”。具体操作如下代码:
> getwd() #查看当前工作路径
[1] "E:/赵志博/R"
> setwd("E:\赵志博") #错误的设置方式
Error: '\? is an unrecognized escape in character string starting ""E:\?
> setwd("E:\\赵志博") #正确的设置方式
> getwd() #查看设置后的工作路径
[1] "E:/赵志博"
当工作路径设置完成后,便可以直接读取工作路径里面的文件而不需要加文件的存储位置。如代码所示,当前工作路径为"E:/赵志博",在该路径下创建了文件“123.txt”,可以直接读取文件,但是在“D:/”创建了新的文件“456.txt”,便不能直接读取,需要加上完整的文件路径,路径同样需要将"\" 改成 “\\”。
mydata <- read.table("123.txt",sep = ',')
> mydata
V1 V2 V3
1 1 2 3
2 4 5 6
3 7 8 9
> mydataD <- read.table("456.txt",sep = ',')
Error in file(file, "rt") : cannot open the connection
In addition: Warning message:
In file(file, "rt") : cannot open file '456.txt': No such file or directory
> mydataD <- read.table("D:\\456.txt",sep = ',')
> mydataD
V1 V2 V3
1 1 2 3
2 4 5 6
3 7 8 9
每次都要设置路径,对有些场合来说未免太过麻烦,因此R提供了一种可以直接选择文件位置的函数,read.***(file.choose()),例如读取txt数据:
mydatachoose <- read.table(file.choose()) #自由选取数据来读取,但是file.choose( )的参数好像没有
参数header:主要确定需要读取的文件是否自己已经设置了列名,默认值为FALSE。这个需要解释一下:上节我们已经讲过data.frame类型,那么read.***( )的返回值也是数据框类型,自然是按列填充的数据框格式,因此列名就显得尤为重要,相当于Excel的表头部分,行号系统会根据1~N的顺序排好,当然也可以修改。
参数sep:主要确定需要读取的文件中,各个字符的分割方式,一般有空格分割,逗号分割等,确定了分割方式,才能保证将数据读取为自己想要的样子。
常见用的参数就是这些,其他的原理都差不多,如果有需要自行学习。
1.txt文件:mydata <- read.table( )
2.Excel格式数据:mydata <- read.xlsx( ),在使用这个函数之前,需要先安装xlsx包,安装方法跟其他包的安装方法一致。一般来说,读取xlsx文件速度较慢,通常将Excel文件保存为csv格式,然后再进行读取 mydata <- read.csv( )
3.XML数据:读取XML数据前先要载入XML包,然后使用 mydata <- xmlRoot(xmlTreeParse("***.xml"))来读取
关于数据的读取就先介绍到这里,其他有用的着的再单独学习。
到此这篇关于R语言的数据输入深入讲解的文章就介绍到这了,更多相关R语言的数据输入内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!