文章目录
1. 正则表达式
1.1 正则表达式的概念
1.2 正则表达式与通配符
1.3 基础正则表达式
1.4 几个例子
2. 字符截取命令
2.1 grep 命令
2.2 cut 命令
2.3 printf 命令
2.4 awk 命令
2.5 sed 命令
3. 字符处理命令
3.1 sort 命令
3.2 wc 命令
1. 正则表达式
1.1 正则表达式的概念
正则表达式是用于描述字符排列和匹配模式的一种语法规则. 它主要用于字符串的模式分割、匹配、查找及替换操作.
1.2 正则表达式与通配符
正则表达式用来在文件中匹配符合条件的字符串,正则是包含匹配。grep、egrep、awk、sed 等命令可以支持正则表达式。
通配符用来匹配符合条件的文件名,通配符是完全匹配。ls、find、cp 这些命令不支持正则表达式。
shell 命令通配符:
*:匹配任意内容
?:匹配任意一个内容
[]:匹配中括号中的一个字符
例子:
user@ubuntu:~# touch abc.txt adc.txt
user@ubuntu:~# ls
abc.txt adc.txt anaconda-ks.cfg
user@ubuntu:~# ls a*
abc.txt adc.txt anaconda-ks.cfg
user@ubuntu:~# ls a?c.txt
abc.txt adc.txt
user@ubuntu:~# ls a[bd]c.txt
abc.txt adc.txt
1.3 基础正则表达式
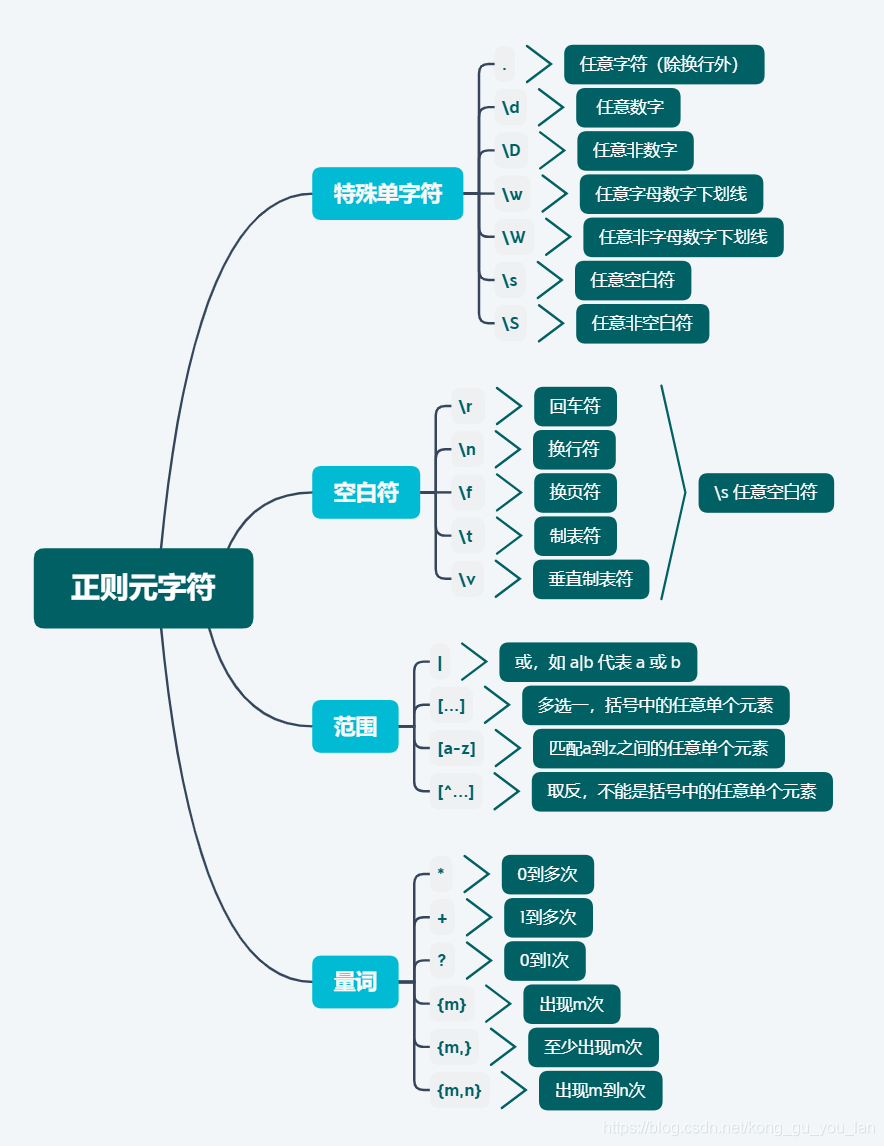
正则表达式分为:
- 基础正则表达式
- 扩展正则表达式
1、基础正则表达式常见元字符(支持的工具:grep、egrep、sed、awk)
\ :转义字符,用于取消特殊符号的含义,例: !、\n、$等
^ :匹配字符串开始的位置,例: ^a、 ^the、 #、[a-z]
$ :匹配字符串结束的位置,例: word$、^$匹配空行
. :匹配除\n之外的任意的一个字符,例: go.d、 g…d
* :匹配前面子表达式0次或者多次,例: goo*d、 go.*d
[list] :匹配list列表中的一个字符,例: go[ola]d, [abc]、 [a-z]、 [a-z0-9]、 [0-9]匹配任意一位数字
[^list] :匹配任意非list列表中的一个字符,例: [^0-9]、 [^A-Z0-9]、 [^a-z]匹配任意一位非小写字母
\{n\} :匹配前面的子表达式n次,例: go{2}d、 '[0-9]{2} '匹配两位数字
\{n,\} :匹配前而的子表达式不少于n次,例: go{2, }d、’[0-9]{2, }'匹配两位及两位以上数字
\{n,m\}: 匹配前面的子表达式n到m次,例: go{2,3}d、'[0-9]{2,3}'匹配两位到三位数字
注:egrep、awk使用{n}、{n,}、{n,m}匹配时"{}"前面不用加"\"
2、扩展正则表达式元字符(支持的工具:egrep、awk)
+ :匹配前面子表达式1次以上,例: go+d, 将匹配至少一个o, 如god、 good、 goood等 ? :匹配前面子表达式0次或者1次,例: go?d, 将匹配gd或god () )将括号中的字符串作为h一个整体,例1: g(oo)+d," 将匹配oo整体1次以上,如good、gooood等 | :以或的方式匹配字条串,例: g (oo|la)d," 将匹配good或者glad
1.4 几个例子
1. 匹配日期格式 YYYY-MM-DD
[0-9]\{4\}-[0-9]\{2\}-[0-9]\{2\}
2. 匹配IP地址
[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\
2. 字符截取命令
2.1 grep 命令
grep 命令用来行提取字符串:
grep [选项] [正则表达式] [文件]
常用选项:
-v:反匹配,找出不匹配的行-n:显示行号-i:不区分大小写--color:[ always | nerver | auto ] 颜色高亮
user@ubuntu:~# grep "bin/bash" /etc/passwd
root:x:0:0:root:/root:/bin/bash
lucifer:x:1000:1000::/home/lucifer:/bin/bash
user1:x:1001:1001::/home/user1:/bin/bash
user2:x:1002:1002::/home/user2:/bin/bash
user@ubuntu:~# grep -n "bin/bash" /etc/passwd
1:root:x:0:0:root:/root:/bin/bash
26:lucifer:x:1000:1000::/home/lucifer:/bin/bash
27:user1:x:1001:1001::/home/user1:/bin/bash
28:user2:x:1002:1002::/home/user2:/bin/bash
user@ubuntu:~# grep "bin/bash" /etc/passwd | grep -v "root"
lucifer:x:1000:1000::/home/lucifer:/bin/bash
user1:x:1001:1001::/home/user1:/bin/bash
user2:x:1002:1002::/home/user2:/bin/bash
2.2 egrep 命令
yao@yao-PC:~/ylx/shell-code/regular-expression$ bash getnumber.sh
02588888888
025 54325753
025-85556666
(025) 85556666
yao@yao-PC:~/ylx/shell-code/regular-expression$ cat getnumber.sh
#!/bin/bash
egrep "^\(?025\)?[ -]?[58][0-9]{7}$" 01.txt
2.2 cut 命令
cut 命令用来列提取字符串:
cut [选项] 文件名
选项:
-f列号:提取第几列-d分隔符:按照指定分隔符分割列
student.txt 文件如下,其中使用制表符
ID Name Gender Mark
1 Ford M 85
2 White M 60
3 Clyde M 70
user@ubuntu:~# cut -f 2 student.txt
Name
Ford
White
Clyde
user@ubuntu:~# cut -f 2,4 student.txt
Name Mark
Ford 85
White 60
Clyde 70
user@ubuntu:~# grep "bin/bash" /etc/passwd | grep -v "root" | cut -f 1 -d ":"
lucifer
user1
user2
缺陷:适合以制表符为分隔符的文档,以空格为分隔符时难以实现需求.
user@ubuntu:~# df -h | cut -f 5
Filesystem Size Used Avail Use% Mounted on
devtmpfs 899M 0 899M 0% /dev
tmpfs 910M 0 910M 0% /dev/shm
tmpfs 910M 9.6M 901M 2% /run
tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/sda3 19G 1.5G 18G 8% /
/dev/sda1 488M 117M 336M 26% /boot
tmpfs 182M 0 182M 0% /run/user/0
user@ubuntu:~# df -h | cut -f 1,3 -d " "
Filesystem
devtmpfs
tmpfs
tmpfs
tmpfs
/dev/sda3
/dev/sda1
tmpfs
2.3 printf 命令
printf '输出类型输出格式' 输出内容
输出类型:
%ns:输出字符串. n 是数字指代输出几个字符.
%ni:输出整数. n 是数字指代输出几个数字
%m.nf:输出浮点数. m 和 n 是数字,指代输出的整数位和小数位,如 %8.2f 代表共输出 8 位数,其中 2 位是小数,6位是整数.
输出格式:
\a:输出警告声音
\b:输出退格键,也就是 Backspace 键
\f:清除屏幕
\n:换行
\r:回车,也就是 Enter 键
\t:水平输出退格键,也就是 Tab 键
\v:垂直输出退格键,也就是 Tab 键
2.4 awk 命令
2.5 sed 命令
sed 是一种几乎包括所有 UNIX 平台(包括 Linux)的轻量级流编辑器. sed 主要是用来将数据进行选取、替换、删除、新增的命令.
sed [选项] ‘[动作]’ 文件名
选项:
-n:一般 sed 命令会把所有数据都输出到屏幕,如果加入次选项则只会把经过 sed 命令处理的行输出到屏幕.
-e:允许对输入数据应用多条命令编辑
-i:用 sed 命令修改结果直接修改读取数据的文件,而不是由屏幕输出.
动作:
a:追加,在当前行后添加一行或多行
c:行替换,用 c 后面的字符串替换原数据行
i:插入,在当期行前插入一行或多行.
d:删除,删除指定的行
p:打印,输出指定的行.
s:字串替换,用一个字符串替换另外一个字符串. 格式为 “行范围s/旧字串/新字串/g”(和 vim 中的替换格式类似).
3. 字符处理命令
3.1 sort 命令
sort [选项] 文件名
项:
- -f:忽略大小写
- -n:以数值型进行排序,默认使用字符串型排序
- -r:反向排序
- -t:指定分隔符,默认分隔符是制表符
- -k n[,m]:按照指定的字段范围排序. 从第 n 字段开始,m 字段结束(默认到行尾)
sort -n -t ":" -k 3,3 /etc/passwd
3.2 wc 命令
wc [选项] 文件
选项:
- -l:只统计行数
- -w:只统计单词数
- -m:只统级字符数