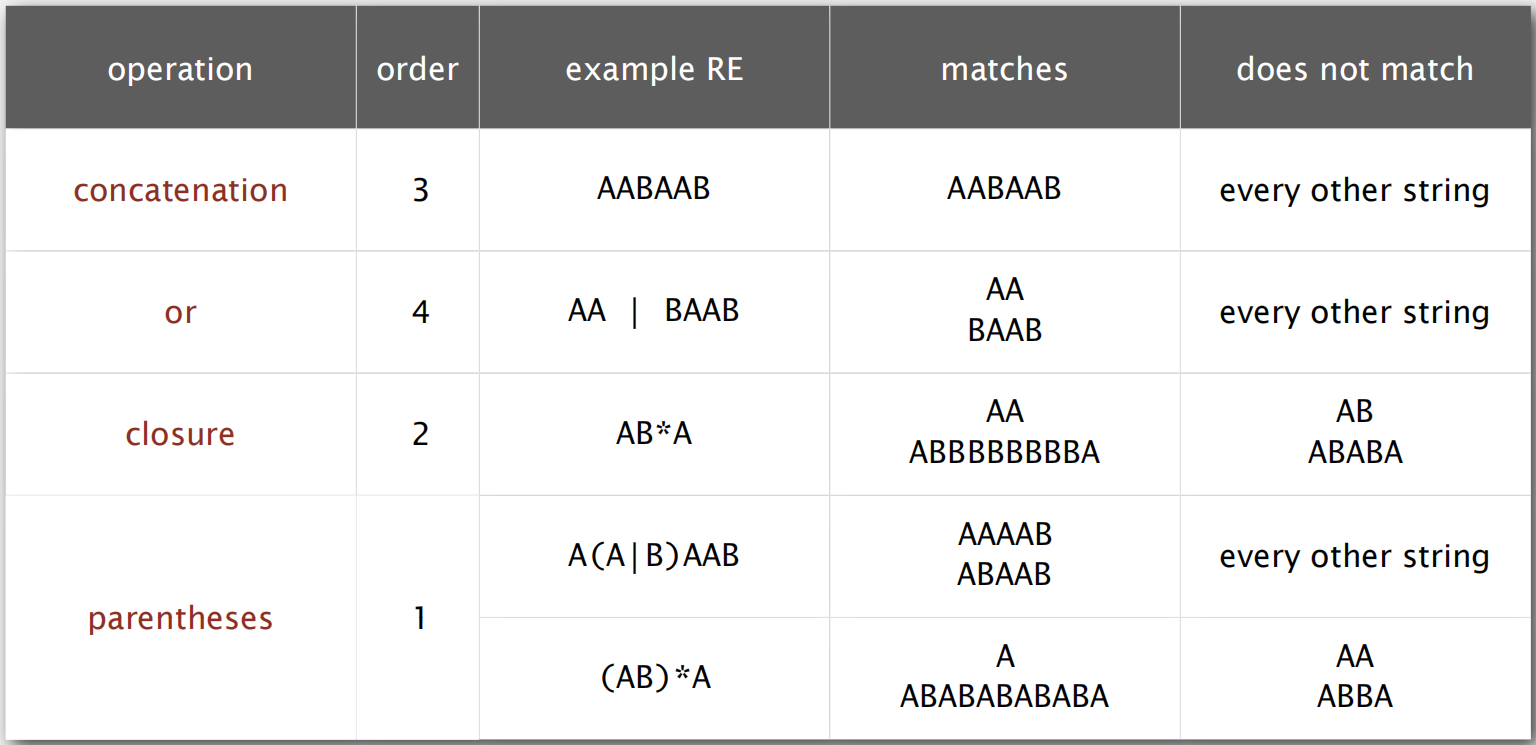
正则表达式就是用于匹配每行输入的一种模式,模式是指一串字符序列。拥有强大的字符搜索功能。也非常方便的搜索过滤出我们想要的内容。
linux正则表达式分为基本正则表达式(Basic Regexp)和扩展正则表达式(Extended Regexp)
linux中,grep,sed,awk都支持正则表达式,这次我们使用grep来演示正则表达式的测试。grep默认仅支持基础正则表达式,如果使用扩展型正则表达式,可以使用grep -E
为了便于观察匹配的值高亮显示,可以给grep命令设置GREP_COLOR的值来指定颜色。
下面是部分颜色的值编号
30 black
31 red
32 green
33 yellow
34 blue
35 purple
36 cyan
37 white
[root@localhost tmp]# vim ~/.bashrc 添加这行 export GREP_OPTIONS='--color=auto' GREP_COLOR='33' [root@localhost tmp]# source ~/.bashrc
正则单字符的表示方式
1.1 单字符分为三种
特定字符(比如 ' a' '中')
范围内字符,用[]表示,它表示单个字符的范围,转指一个字符,比如要搜索包含数字0到9的,就可以[0-9],或者找到123中其中某一个数字[123]。
grep '[0-9]' passwd
grep '[a-zA-Z]' passwd
取反字符
grep '[^a-zA-Z]' passwd
任意字符( . 来表示)表示匹配任意的字符
grep . passwd
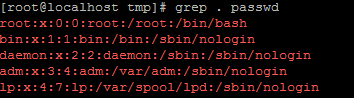
如果把点放在[]里面就代表本身的意义

加上反义字符 \,效果也是一样,这个反义字符功能就是对点(.) 本身功能的取反。

这三种也可以组合成为一个复杂的正则表达式
边界字符:头尾字符
^ : 头字符符号,例如:^www 注意与[^www]的区别,这里是代表头字符的意思,是一行以www字符为开头,而不是一个范围取反。
[root@localhost tmp]# grep ^www passwd www:x:1002:1002::/home/www:/bin/bash
$:尾字符符号,代表以什么字符为结束的行。
[root@localhost tmp]# grep halt$ passwd halt:x:7:0:halt:/sbin:/sbin/halt
如果要匹配空行,可以用头字符和尾字符放一起
[root@localhost tmp]# grep ^$ passwd
显示行号可以加n
[root@localhost tmp]# grep -n ^$ passwd 49:
元字符(代表普通字符或特殊字符)
\w: (小写的w)匹配任何字类字符,包括下划线([A-Za-z0-9_])。
\W:(大写的w)匹配任何非字类字符([^A-Za-z0-9_]),相当于上面\w的取反。
\b:代表单词的分割。
[root@localhost tmp]# grep '\bx\b' passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin
正则表达式字符组合
匹配一个大写后面跟着一个小写字母的这样字符组合
[root@localhost tmp]# grep '[A-Z][a-z]' /etc/passwd ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin nobody:x:99:99:Nobody:/:/sbin/nologin avahi-autoipd:x:170:170:Avahi IPv4LL Stack:/var/lib/avahi-autoipd:/sbin/nologin dbus:x:81:81:System message bus:/:/sbin/nologin polkitd:x:999:998:User for polkitd:/:/sbin/nologin unbound:x:998:996:Unbound DNS resolver:/etc/unbound:/sbin/nologin
同理试下匹配两位数字。
[root@localhost tmp]# grep '[0-9][0-9]' /etc/passwd mysql:x:1001:1001::/home/mysql:/bin/bash www:x:1002:1002::/home/www:/bin/bash nginx:x:1003:1003::/home/nginx:/bin/bash rabbitmq:x:989:986:RabbitMQ messaging server:/var/lib/rabbitmq:/bin/bash songguojun:x:1004:1004::/home/songguojun:/bin/bash lang:x:1005:1005::/home/lang:/bin/bash
结果发现匹配到了所有的挨在一起的两位数,这个也是正则的最大化匹配,所有有时候返回的结果并不是我们想要的。我们可以用到上面用到的分隔符\b。
[root@localhost tmp]# grep '\b[0-9][0-9]\b' /etc/passwd
正则表达式可以匹配重复的字符,
*:零次或多次匹配前面的字符或子表达式。
+:一次或多次匹配前面的字符或子表达式。
?:零次或一次匹配前面的字符或子表达式。
准备字符串
[root@localhost tmp]# echo -ne " auu \n aeeeeeee\n se \n sdddd \n ooaekkaemma \n" auu aeeeeeee se sdddd ooaekkaemmae+
kka
将上面的字符串写入到文件中:
[root@localhost tmp]# echo -ne " auu \n aeeeeeee\n se \n sdddd \n ooaekkaemmae+ \n kka \n aeaekk" > test.txt
[root@localhost tmp]# cat test.txt
auu
aeeeeeee
se
sdddd
ooaekkaemmae+
kka
下面就分别使用 * , + , ? 这个三个元字符来匹配ae字符串。
示例1-1
[root@localhost tmp]# grep 'ae*' test.txt auu aeeeeeee ooaekkaemmae+
kka
示例1-2
[root@localhost tmp]# grep 'ae+' test.txt ooaekkaemmae+ [root@localhost tmp]# grep 'ae\+' test.txt 这里+要转义下 aeeeeeee ooaekkaemmae+
示例1-3
[root@localhost tmp]# grep 'ae\?' test.txt 这里?也要转义下 auu aeeeeeee ooaekkaemmae+ kka
上面是匹配重复的单个字符,那如果想匹配重复的表达式呢?这里我们需要另一个符号()。
示例1-4
[root@localhost tmp]# grep '\(ae\)*' test.txt ()需要转义 auu aeeeeeee se sdddd ooaekkaemmae+ kka aeaekk
重复特定的次数{n,m} , n代表重复的最小次数,m代表重复的最大的次数,如果m不写那就是表示重复无限大的次数。
任意字符串表示:.*
[root@localhost tmp]# grep 'n..n' /etc/passwd nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin gnome-initial-setup:x:992:990::/run/gnome-initial-setup/:/sbin/nologin nginx:x:1003:1003::/home/nginx:/bin/bash [root@localhost tmp]# grep 'n.*n' /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@localhost tmp]# grep '\bn.*n\b' /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin nobody:x:99:99:Nobody:/:/sbin/nologin 正则的贪婪匹配
就不要让匹配任意字符,缩小匹配范围。
[root@localhost tmp]# grep '\bn[a-z]*n\b' /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin nobody:x:99:99:Nobody:/:/sbin/nologin
正则表达式逻辑字符组合
逻辑的表示:
| : ' /bin\(false\|true\)' 两种可能性都存在的情况,注意括号和逻辑或 | 符号 要加上反斜线。
[root@localhost tmp]# grep 'bin/\(bash\|nologin\)' /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin mysql:x:1001:1001::/home/mysql:/bin/bash www:x:1002:1002::/home/www:/bin/bash
下面在看几个案例
匹配4-9位qq号
[root@localhost tmp]# grep '^[0-9]\{4,10\}$' test.txt 1123258953 32232 1234
匹配15位或者18位可以包含末尾是x的身份证
[root@localhost tmp]# echo 345895847856388 | grep '^[1-9]\([1-9]\{13\}\|[0-9]\{16\}\)[0-9xX]$' 345895847856388
匹配密码(包含数字,26个字母和下划线组成)
[root@localhost tmp]# echo abc_6388 | grep '^\w\+$' abc_6388

正则表达式总结图
linux通配符
通配符是指一些特殊符号,可以用来模糊搜索文件,这些字符包括“?”,“*”,“[]”,{}。
[root@localhost etc]# ls *.conf asound.conf cgconfig.conf colord.conf extlinux.conf host.conf krb5.conf libuser.conf mke2fs.conf ntp.conf autofs.conf cgrules.conf dnsmasq.conf fprintd.conf idmapd.conf ksmtuned.conf locale.conf
[root@localhost data]# ls -l /usr/lib*/libm.so* lrwxrwxrwx. 1 root root 21 6月 27 2017 /usr/lib64/libm.so -> ../../lib64/libm.so.6 lrwxrwxrwx. 1 root root 12 6月 27 2017 /usr/lib64/libm.so.6 -> libm-2.17.so lrwxrwxrwx. 1 root root 19 6月 27 2017 /usr/lib/libm.so -> ../../lib/libm.so.6 lrwxrwxrwx. 1 root root 12 6月 27 2017 /usr/lib/libm.so.6 -> libm-2.17.so
[root@spark78-245 kyhome]# ls *.gif;ls *.png 15194410503451858272.gif 15194410506312962733.gif 15194410811930618141.gif 15194572224055871555.gif 15194572228918706981.gif 15194575455399643251.png15194575459612727704.gif 15198085947116977864.gif 15194575454541195873.gif 15194575458714249740.gif 15198085946007107442.gif 15222289284897297936.gif 15194577551806668917.png
[^0-9] !^表示非,取反
[root@spark78-245 kyhome]# touch abc.png [root@spark78-245 kyhome]# ls [^0-9]*.png abc.png
[root@spark78-245 kyhome]# ls [!0-9]*.png abc.png
? 任何一个字符
[root@localhost etc]# ls ??? rpc gdm: custom.conf Init PostLogin PostSession PreSession Xsession gss: mech mech.d
| 符号 | 作用 |
|---|---|
| * | 匹配任何字符串/文本,包括空字符串;*代表任意字符(0个或多个) ls file * |
| ? | 匹配任何一个字符(不在括号内时)?代表任意1个字符 ls file 0 |
| [abcd] | 匹配abcd中任何一个字符 |
| [a-z] | 表示范围a到z,表示范围的意思 []匹配中括号中任意一个字符 ls file 0 |
| {..} | 表示生成序列. 以逗号分隔,且不能有空格 |
| 补充 | |
| [!abcd] | 或[^abcd]表示非,表示不匹配括号里面的任何一个字符 |