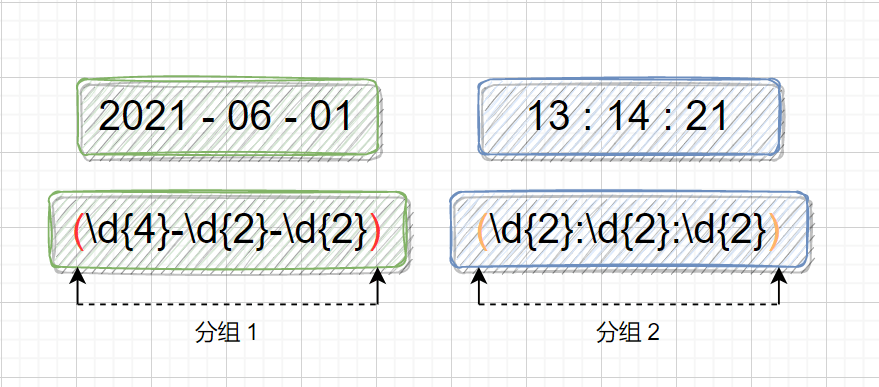
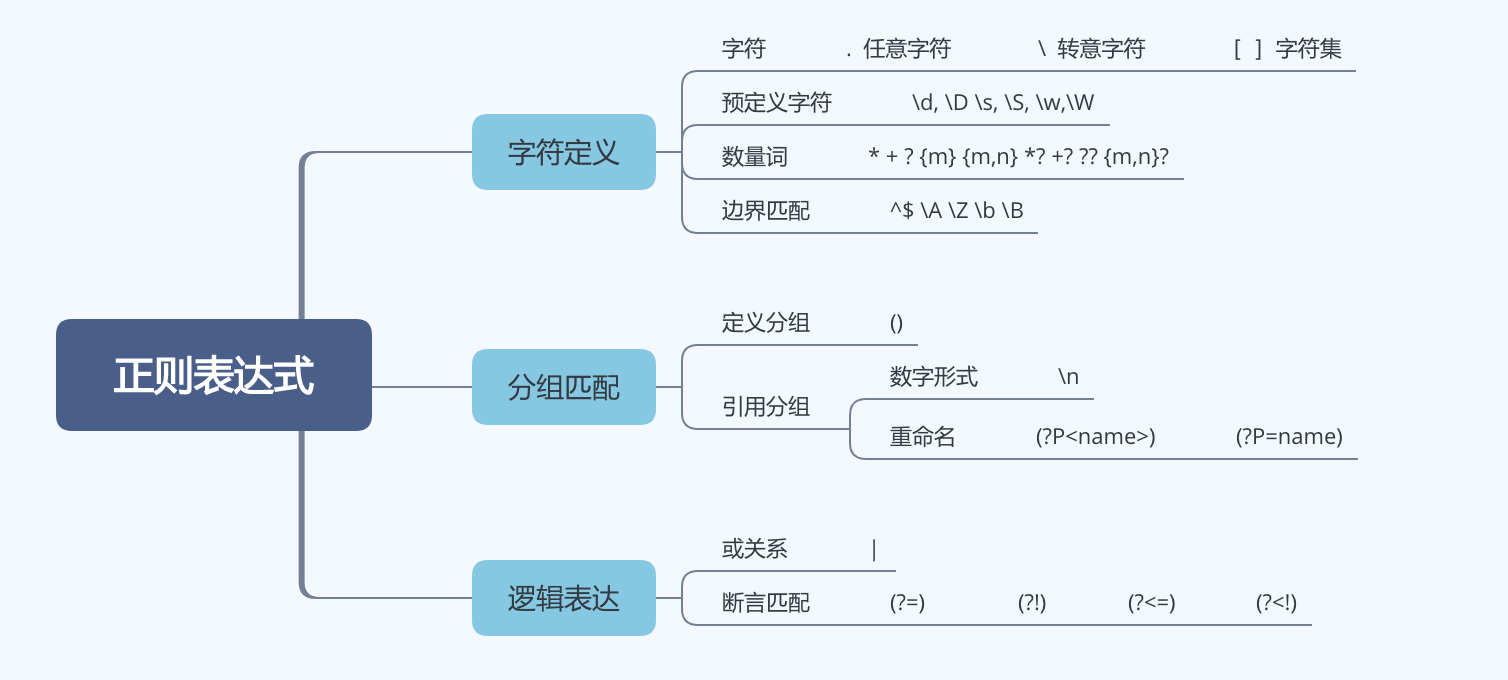
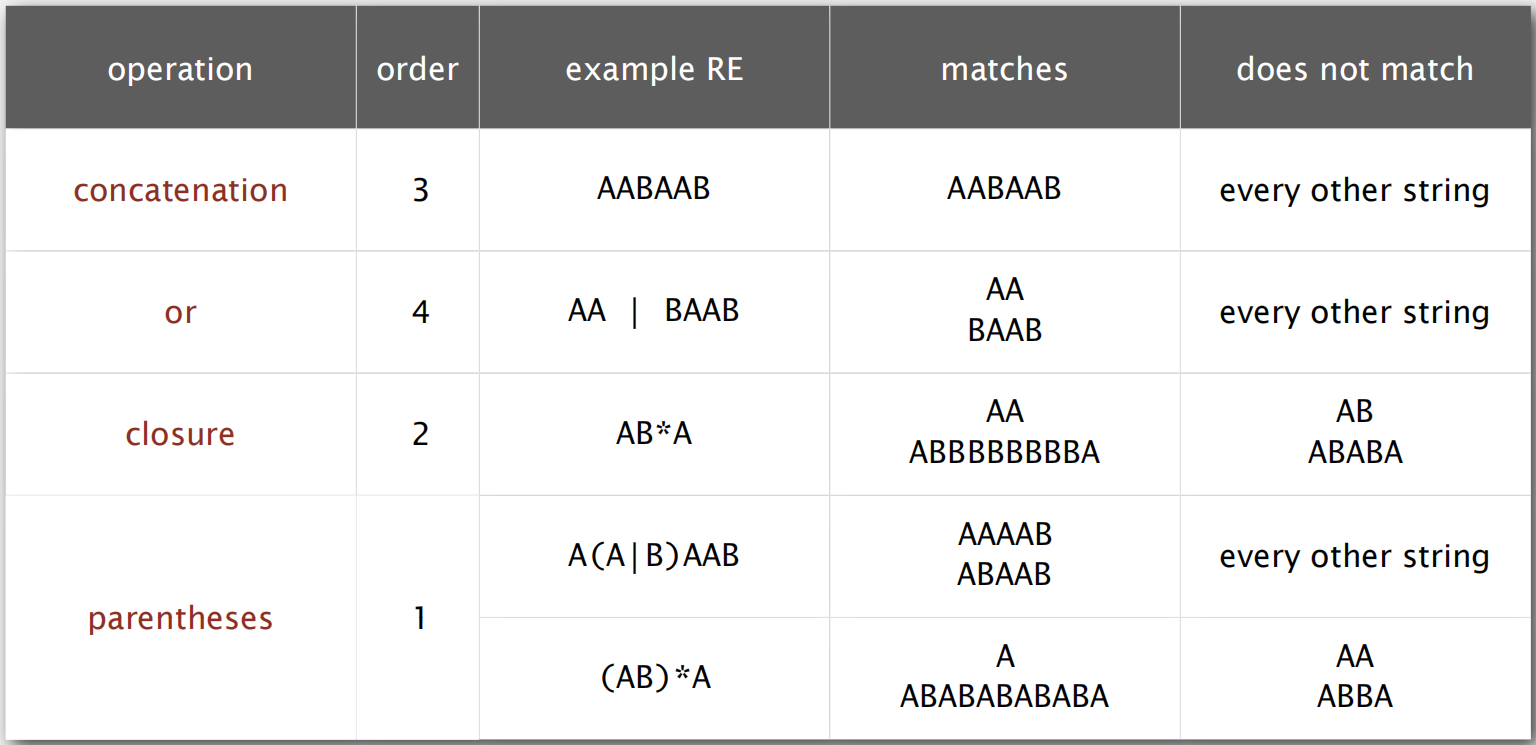
正则表达式常用符号说明:
1、 .是除换行以外的所有任意符号
2、 \s空白符号
3、 \S除空白符号以外的任意符号
4、 \w字母、数字、下划线
5、 \W 除字母、数字、下划线以外的其他任意符号
6、 \d 数字(0----9)
7、 \D 除数字以外的任意其他符号
8、 ^ 字符串开始
9、 $ 字符串结束
10、 * 匹配0到无数次(匹配的是符号前边的字母或者数字等)
11、 + 匹配1到无数次(匹配的是符号前边的字母或者数字等)
12、 ?匹配0次或1次(匹配的是符号前边的字母或者数字等)
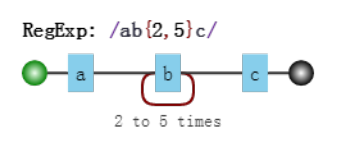
13、 {x} 重复x次
14、 {x,} 重复至少x次
15、 {x,y} 重复x次到y次
16、 [] 字符组,表示字符范围
17、 () 捕获组(子表达式)
18、 \ 转义符号
19、 \b:匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配 "never" 中的 'er',但不能匹配 "verb" 中的 'er'。
\b是正则表达式规定的一个特殊代码,代表着单词的开头或结尾,也就是单词的分界处,虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是\b并不匹配这些单词
分隔字符中的任何一个,它只匹配一个位置。
没测试)
\b代表字与字中间那个看不见的东西,如 here is a word 那么,这句中有好几个\b, 每个单词的前后都有一个\b.所以你用 \bhere\b 可以匹配上面这个here,但如果here
不是一个单词,而是一个单词的一部分,如 adheread, 这样的话,用here 可以匹配,用\bhere\b就不能区配了,因为ad后面没有\b. 所以 adhere 中的here 不会被匹配。
总结: \b 就是用在你匹配整个单词的时候。 如果不是整个单词就不匹配。 你想匹配 I 的话,你知道,很多单词里都有I的,但我只想匹配I,就是“我”,这个时候用 \bI\b
字符组:
1、 [0-9] 数字0到数组9之间的任意一个
2、 [a-z] 字母a到字母z的任意一个
3、 [^cfC] 除了字母 c f C的任意一个字符
4、 [\一-\龥] 汉字中的任意一个汉字 注
5、 [^a-z] 除了字母 a 到字母z的任意一个字符
6、 [^-a-c] 除了 - 字符以及字母a到字母z的任意一个字符
7、 | 多选分支,或者关系
8、 \1 \2 … 反向引用 < (\w) >.*</\1> 引用第一个捕获组的结果,用于匹配html的闭合标签