Python语言及其应用
7.1.3使用正则表达式匹配
正则表达式使用:首先需要定义一个用于匹配的模式(pattern)字符串和一个匹配的对象:源(source)字符串,如下,
Result = re.match(‘’You,’Young France’)
这里的 “You”是模式,“Young France”是源——你想检查的字符串。函数用于查看源是否以模式开头。
以下列出几种匹配方法,
match( )以某某开头作精准匹配,
search( )会返回第一次成功匹配,如果存在的话
findall( )会返回所有不重叠的匹配,如果存在的话
split( )会根据pattern将source切分成若干段,返回由这些片段组成的列表
sub( )还需要一个额外的参数repacement,他会把source中所有匹配pattern给出replacement
1、使用match( )进行精准匹配
[root@promethus te]# python
Python 3.6.3 |Anaconda, Inc.| (default, Oct 13 2017, 12:02:49)
[GCC 7.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> aaa = 'Young FranceYou'
>>> m = re.match('You', aaa)
>>> print(m)
<_sre.SRE_Match object; span=(0, 3), match='You'>
>>> print(m.group())
You
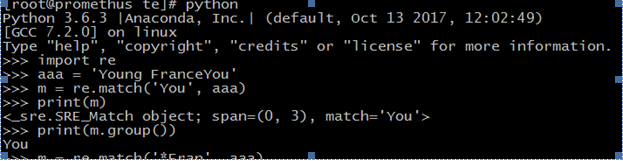
>>> n = re.match(".*Fran', aaa)
>>> print (n)
<_sre.SRE_Match object; span=(0, 10), match='Young Fran'>
>>> print (n.group())
Young Fran
>>>
以下对新模式能够匹配成功的解释:
.代表任何单一字符;
*代表任意一个它之前的字符,.*代表任意多个字符(包括0个)
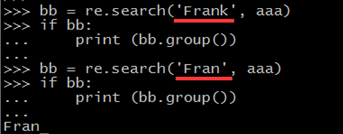
2、使用search( )寻找首次匹配
使用search('Frank', aaa)查找任意位置的“Frank”或“Fran”,无需通配符。
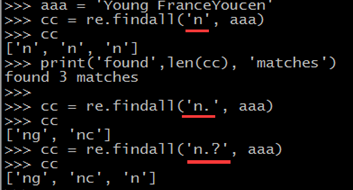
3、使用findall( )寻找所有匹配
结合.*?匹配规则进行。
4、使用split ( )按匹配切分
将一个字符串切分成由一系列的子串组成的列表

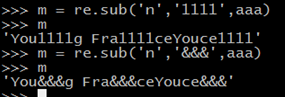
5、使用sub ( )替换匹配
6、模式:特殊字符归类
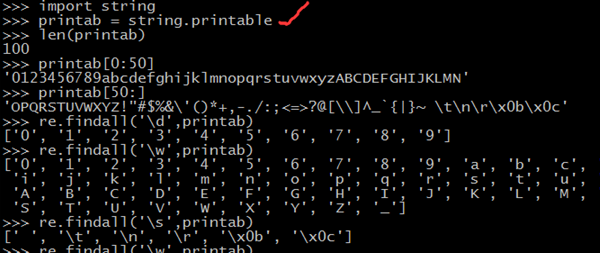
模式 匹配
\d 一个数字字符
\D 一个非数字字符
\w 一个字母或数字字符
\W 一个非字母非数字字符
\s 空白符
\S 非空白符
\b 单词边界(一个\w与\W之间的范围,顺序可逆)
\B 非单词边界
验证操作
7、模式:使用标识符
模式 匹配
abc 文本值abc
. 除\n外的任何字符
^ 源字符串的开头
$ 源字符串的结尾
prev? 0个或1个prev
prev* 0个或多个prev,尽可能多的匹配
prev*? 0个或多个prev,尽可能少的匹配
prev+ 1个或多个prev,尽可能多的匹配
prev+? 1个或多个prev,尽可能少的匹配
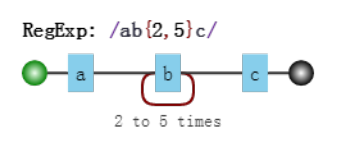
prev{m} m个连续的prev
prev{m,n} m到n个连续的prev,尽可能多的匹配
prev{m,n} m到n个连续的prev,尽可能少的匹配
[abc] a或b或c,跟[a|b|c]一样
[^abc] 非(a或b或c)
prev(?=next) 如果后面为next,返回prev
prev(?!next) 如果后面为非next,返回prev
(?<=prev)next 如果前面为prev,返回next
(?<!prev)next 如果前面为非prev,返回next
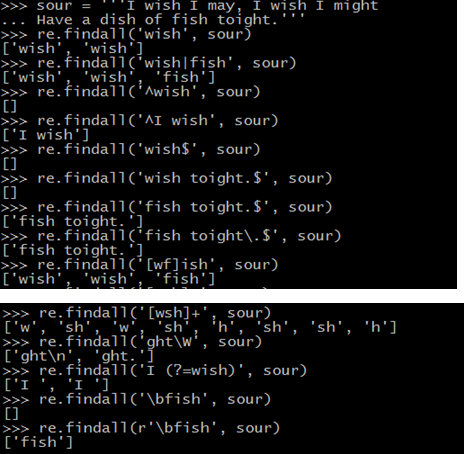
示例
>>> sour = '''I wish I may, I wish I might
... Have a dish of fish toight.'''
>>> re.findall('wish', sour)
['wish', 'wish']
8、模式:定义匹配的输出
当使用时match( )或search( )时,所有的匹配会以的形式返回对象m.group()中,如果你用括号将某一个模式包裹起来,括号中模式匹配得到的结果归自己的group中,而调用m.groups()可以得到包含这些匹配的元祖,如下,
>>> import re
>>> sour = "''I wish I may, I wish I might
... Have a dish of fish toight.'''
>>> m = re.search(r'(?P<DISH>. dish\b).*(?P<FISH>\bfish)', sour)
>>> m.group()
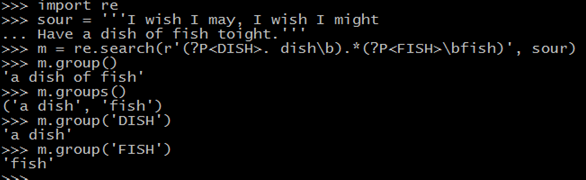
自此,完成正则匹配基本功能。