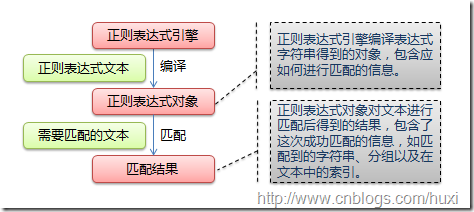
正则表达式
动机 :
1 处理文本称为计算机主要工作之一
2 根据文本内容进行固定搜索是文本处理的常见工作
3 为了快速方便的处理上述问题,正则表达式技
正则表达式
动机 :
1. 处理文本称为计算机主要工作之一
2. 根据文本内容进行固定搜索是文本处理的常见工作
3. 为了快速方便的处理上述问题,正则表达式技术诞生,逐渐发展为一个单独技术被众多语言使用
定义 : 即高级文本匹配模式,提供了搜索,替代等功能,本质是由一些字符和特殊符号组成的字串。这个字串描述了字符和字符的重复行为,可以匹配某一类特
征的字符串集合。
目标 :
1.熟练正则表达式符号和用法
2.能够正确的理解和简单使用正则表达式进行匹配
3.能够使用python re模块操作正则表达式
正则特点:
* 方便进行检索和修改
* 支持语言众多
* 使用灵活变化多样
* 文本处理,mongo存储某一类型字串,django、tornado路由,爬虫文本匹配
正则的规则和用法
import re
re.findall(regex,string)
功能 : 使用正则表达式匹配字符串
参数 : regex : 正则表达式
string : 目标字符串
返回值 : 匹配到的内容
元字符 (即正则表达式中有特殊含义的字符)
* 普通字符
元字符 : abc
匹配规则 : 匹配相应的普通字符
e.g. ab ----》 abcdef : ab
In [3]: re.findall('ab','abcdefabcde')
Out[3]: ['ab', 'ab']
* 使用 或 多个正则同时匹配
元字符 : |
匹配规则:符号两侧的正则均能匹配
e.g. ab|cd ---》 abcdefgh : ab cd
In [5]: re.findall('ab|fg','abcdefgabcde')
Out[5]: ['ab', 'fg', 'ab']
##* 匹配单一字符
元字符 : .
匹配规则: 匹配任意一个字符 '\n'除外
e.g. f.o ---》 foo fuo fao f@o
In [7]: re.findall('f.o','affooasand f@o,')
Out[7]: ['ffo', 'f@o']
*匹配字符串开头
元字符 : ^
匹配规则: 匹配一个字符串的开头位置
e.g. ^Hello ---> Hello world : Hello
*匹配字符串结尾
元字符: $
匹配规则: 匹配一个字符串的结尾位置
e.g. py$ ----> hello.py : py
In [10]: re.findall('py$','hello.py')
Out[10]: ['py']
*匹配重复0次或多次
元字符: *
匹配规则:匹配前面出现的正则表达式 0次或者多次
e.g. ab* a ab abbbb
*匹配重复1次或多次
元字符 : +
匹配规则: 匹配前面正则表达式至少一次
e.g ab+ ab abbbbb
In [29]: re.findall('.+\.py$','a.py')
Out[29]: ['a.py']
* 匹配重复0次或1次
元字符: ?
匹配规则 : 匹配前面出现的正则表达式0次或1次
e.g. ab? a ab
In [34]: re.findall('ab?','abcdeabasdfabbbbbb')
Out[34]: ['ab', 'ab', 'a', 'ab']
* 匹配重复指定次数
元字符 : {N}
匹配规则 : 匹配前面的正则表达式N次
e.g. ab{3} abbb
*匹配重复指定次数范围
元字符 :
匹配规则 : 匹配前面的正则表达式 m次到n次
e.g ab{3,5} abbb abbbb abbbbb
In [39]: re.findall('ab{2,5}','abbcdeabbbabsdfabbbbbb')
Out[39]: ['abb', 'abbb', 'abbbbb']
* 字符集匹配
元字符 : [abcd]
匹配规则 : 匹配中括号中的字符集,或者是字符集区间 的一个字符
e.g. [abcd] ----》 a b c d
[0-9] ---> 1 3 4 7 匹配任意一个数字字符
[A-Z] ---》 A D H 匹配任意一个大写字符
[a-z] ---》 a d f h 匹配任意一个小写字符
多个字符集形式可以写在一起
[+-*/0-9a-g] + - * / 4 b
In [42]: re.findall('^[A-Z][0-9a-z]{5}','Hello1 Join')
Out[42]: ['Hello1']
* 字符集不匹配
元字符 : [^ ...]
匹配规则 : 匹配出字符集中字符的任意一个字符
e.g. [^abcd] -> e f & #
[^0-9] -> a d g
In [48]: re.findall('[^_0-9a-zA-Z]','levi@126.com')
Out[48]: ['@', '.']
* 匹配任意数字(非数字)字符
元字符 : \d [0-9] \D [^0-9]
匹配规则: \d 匹配任意一个数字字符 \D 匹配任意非数字字符
In [49]: re.findall('1\d{10}','15100317766')
Out[49]: ['15100317766']
* 匹配任意普通字符(特殊字符)
元字符 : \w [_0-9a-zA-Z] \W [^_0-9a-zA-Z]
匹配规则 : \w 匹配数字字母下划线 \W 除了数字字母下划线
* 匹配任意 (非)空字符
元字符 : \s \S
匹配规则: \s 任意空字符 [ \n\0\t\r] 空格 换行 回车 制表
\S 任意非空字符
In [61]: re.findall('hello\s+\S+','hello l&#l hello lucy hellokadfh')
Out[61]: ['hello l&#l', 'hello lucy']
* 匹配字符串开头结尾
元字符 : \A ^ \Z $
匹配规则: \A 表示匹配字符串开头位置
\Z 表示匹配字符串的结尾位置
e.g. \Aabc\Z ---> abc
* 匹配(非)单词边界
元字符: \b \B
匹配规则 \b 匹配一个单词的边界
\B 匹配一个单词的非边界
数字字母下划线和其他字符的交界处认为是单词边界
is "This is a test"
In [71]: re.findall(r'\bis\b','This is a test')
Out[71]: ['is']
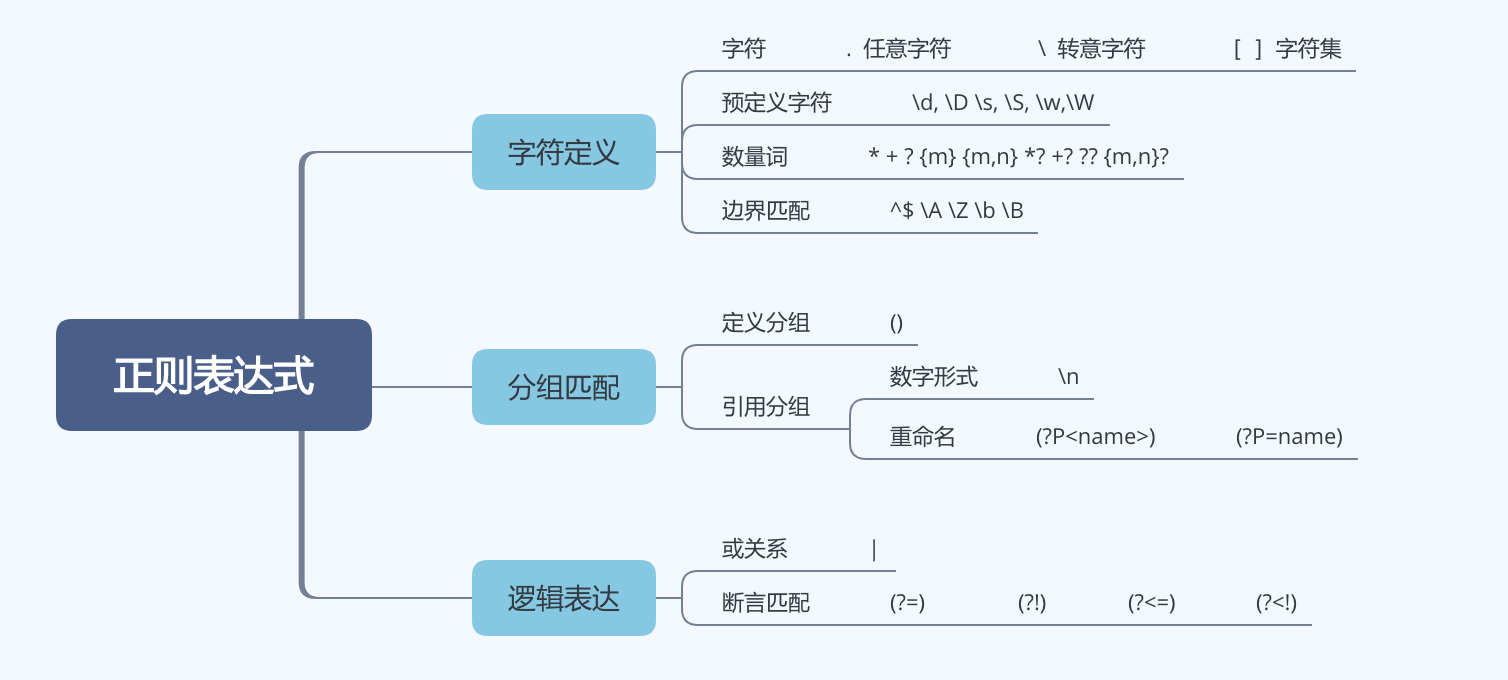
元字符总结
字符: 匹配实际字符
匹配单个字符 : . \d \D \w \W \s \S [...] [^...]
匹配重复次数 : * + ? {N} {M,N}
匹配字串位置 : ^ $ \A \Z \b \B
其他 : |
r字串和转义
转义 : . * ? $ "" '' [] () {} \
r ---> 将字符串变为 raw 字串
不进行字符串的转义
两种等价的写法
In [87]: re.findall(r'\? \* \\','what? * \\')
Out[87]: ['? * \\']
In [88]: re.findall('\\? \\* \\\\','what? * \\')
Out[88]: ['? * \\']
贪婪和非贪婪
和重复元字符相关
* + ?{m,n}
贪婪模式 :
在使用重复元字符的时候(* + ?{m,n}),元字符的匹配总是尽可能多的向后匹配更多内容,即为贪婪模式。贪婪模式是一种默认情况
e.g. 尽可能多的匹配b
In [90]: re.findall('ab+','abbbbbbalksdjfab')
Out[90]: ['abbbbbb', 'ab']
非贪婪模式 :
尽可能少的匹配内容,只要满足正则条件即可
贪婪 ---》 非贪婪 *? +? ?? {m,n}?
尽量少匹配
In [95]: re.findall('ab*?','abbbbbbalksdjfab')
Out[95]: ['a', 'a', 'a']
In [96]: re.findall('ab+?','abbbbbbalksdjfab')
Out[96]: ['ab', 'ab']
正则表达式的分组
使用()为正则表达式分组
((ab)cd(ef)) : 表示给ab分了一个子组
1. 正则表达式的子组用()表示,增加子组后对整体的匹配没有影响
2. 每个正则表达式可以有多个子组,子组由外到内由左到右为第一第二第三。。。。。。子组
3. 子组表示一个内部整体,很多函数可以单独提取子组的值
In [108]: re.match('(ab)cdef','abcdefghig').group(1)
Out[108]: 'ab'
4. 子组可以改变 重复行为,将子组作为一个整体重复
In [111]: re.match('(ab)*','ababababab').group()
Out[111]: 'ababababab'
捕获组和非捕获组 (命名组和非命名组)
格式 : (?P<name>regex)
(?P<word>ab)cdef
某些函数可以通过名字提取子组内容,或者通过名字进行键值对的生成。
In [112]: re.match('(?P<word>ab)cdef','abcdefghi').group()
Out[112]: 'abcdef'
起了名字的子组可以通过名称重复使用
(?P=name)
In [114]: re.match('(?P<word>ab)cd(?P=word)','abcdabdfewf').group()
Out[114]: 'abcdab'
re模块
compile(pattern, flags=0)
功能 : 获取正则表达式对象
参数 : pattern 正则表达式
flags 功能标志位 提供正则表达式结果的辅助功能
返回值:返回相应的正则对象
* compile 函数返回值的属性函数 和 re模块属性函数有相同的部分
相同点:
*功能完全相同
不同点:
compile返回值对象属性函数参数中没有pattern和flags部分,因为这两个参数内容在compile生成对象时已经指明,而re模块直接调用这些函数时则需要传入
compile返回值对象属性函数参数中有pos 和 endpos参数,可以指明匹配目标字符串的起始位置,而re模块直接调用这些函数时是没有这个
findall(string,pos ,endpos)
功能 : 将正则表达式匹配到的内容存入一个列表返回
参数 : 要匹配的目标字符串
返回值: 返回匹配到的内容列表
* 如果正则表达式中有子组,则返回子组的匹配内容
split()
功能: 以正则表达式切割字符串
返回值 : 分割后的内容放入列表
sub(pattern,re_string,string,count)
功能:用目标字符串替换正则表达式匹配内容
参数:re_string 用什么来替换
string 要匹配的目标字符串
max 最多替换几处
返回值 : 返回替换后的字符串
subn()
功能 : 同sub
参数 : 同sub
返回值 : 比sub多一个实际替换的个数
groupindex : compile对象属性 得到捕获组名和第几组数字组成的字典
groups: compile属性,得到一共有多少子组
finditer()
功能 : 同findall 查找所有正则匹配到的内容
参数:同findall
返回值 : 返回一个迭代器,迭代的每一项都是一个matchobj
match(pattern, string, flags=0)
功能:匹配一个字符串开头的位置
参数:目标字符串
返回值 : 如果匹配到返回 一个match obj
没匹配到返回None
search
功能:同match 只是可以匹配任意位置,只能匹配一处
参数:目标字符串
返回值 : 如果匹配到返回 一个match obj
没匹配到返回None
fullmatch()
要求目标字符串能够被正则表达式完全匹配
In [12]: obj = re.fullmatch('\w+','abcd2')
In [13]: obj.group()
Out[13]: 'abcd2'
match 对象属性及函数
'end'
'endpos'
'group'
'groupdict'
'groups'
'lastgroup'
'lastindex'
'pos'
're',
'span'
'start'