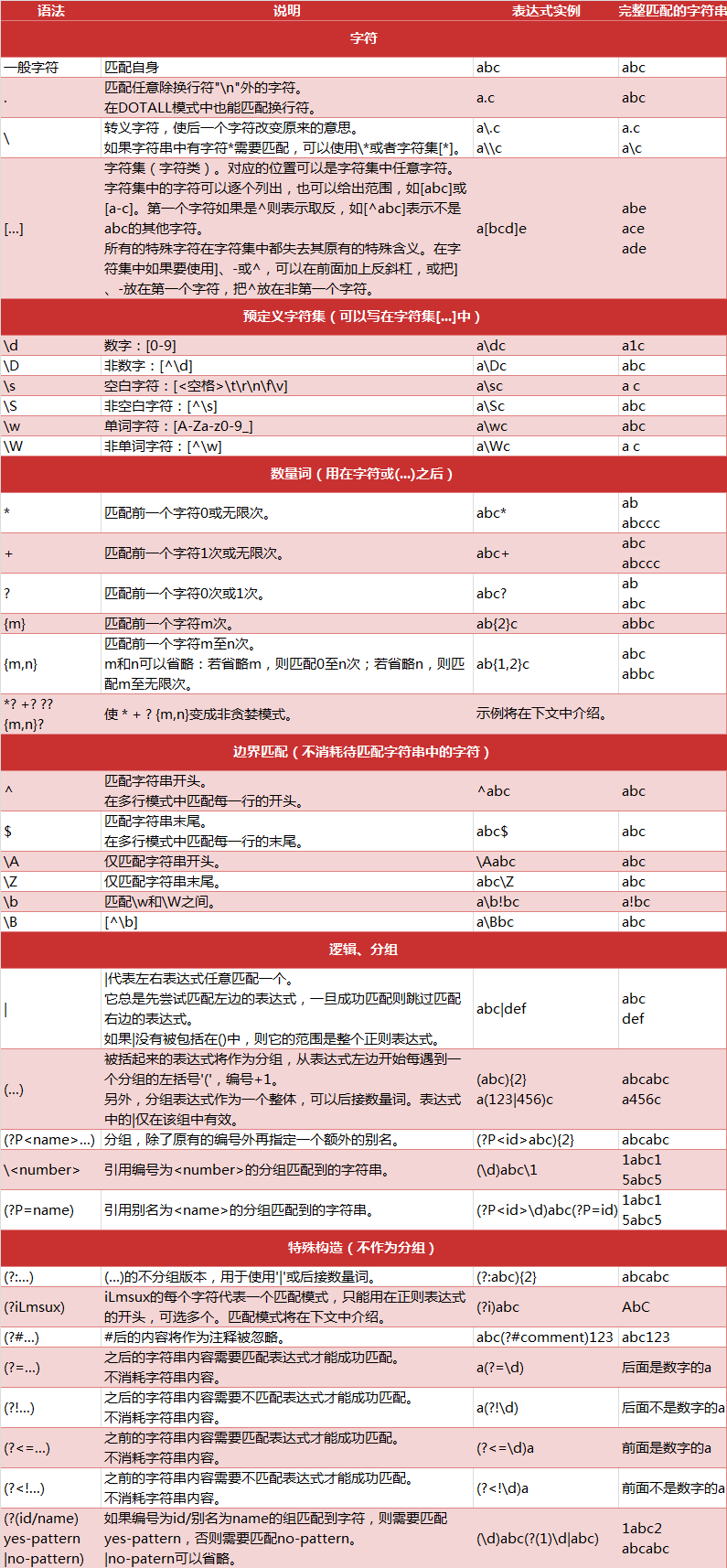
本节内容
- 正则表达式简介
- 正则表达式中的字符
- 元字符详解
- 常用正则表达式实例
- 正则表达式的匹配过程
- 正则表达式中的标志位-flag
- 参考资料
需要提前说明的是: 正则表达式的语法是由正则表达式引擎决定的(目前主流的正则引擎分为3类:DFA、传统型NFA 和 POSIX NFA),不同编程语言或应用程序所使用的引擎可能不同,它们对正则表达式的语法支持会有差别。
一、正则表达式简介
1. 什么是正则表达式
正则表达式(Regluar Expressions)又称规则表达式,这个概念最初是由Unix中的工具软件(如sed 和 grep)普及开的。正则表达式在代码中常简写为REs,regexes或regexp(regex patterns)。它本质上是一个小巧的、高度专用的编程语言。 许多程序设计语言都支持通过正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。
2. 正则表达式能做什么
正则表达式的主要应用对象是文本,使用正则表达式可以指定想要匹配的字符串规则,然后通过这个规则来匹配、查找、替换或切割那些符合指定规则的文本。总体来讲,正则表达式可以对指定的文本实现以下功能:
- 匹配验证: 判断给定的字符串是否符合正则表达式所指定的过滤规则,从而可以判断某个字符串的内容是否符合特定的规则(如email地址、手机号码等);当正则表达式用于匹配验证时,通常需要在正则表达式字符串的首部和尾部加上^和$,以匹配整个待验证的字符串。
- 查找与替换: 判断给定字符串中是否包含满足正则表达式所指定的匹配规则的子串,如查找一段文本中的所包含的IP地址。另外,还可以对查找到的子串进行内容替换。
- 字符串分割与子串截取: 基于子串查找功能还可以以符合正则表达式所指定的匹配规则的字符串作为分隔符对给定的字符串进行分割。
二、正则表达式中的字符
正则表达式的主要应用对象是文本,其最基础的功能是文本匹配,而文本是由一个个的字符组成,因此正则表达式实际上是对字符的匹配。正则表达式中的字符分为 普通字符 和 元字符,而正则表达式就是这些普通字符和特殊元字符组合成的表示一个特定匹配规则的表达式。
1. 普通字符
实际上,大多数字符都将简单地匹配它们的自身值,它们被称为普通字符,如数字(0-9),字母(a-z, A-Z)等。例如,正则表达式hello123将匹配字符串'hello123',因为该这则表达式中都是普通字符,不包含特殊元字符。当然,我们可以通过指定正则表达式的匹配模式为 忽略字母大小写模式,这么正则表达式hello123将能够匹配'Hello123', 'HellO123', 'HELLO123'等字符串。
提示: 其实我们并不需要去记忆哪些字符是普通字符,我们只需要知道哪些字符是特殊元字符就可以了,除了特殊元字符之外的所有字符都是普通字符。
2. 元字符
上面提到,正则表达式除了进行字符自身之的匹配外,还可以基于指定的规则进行模糊匹配。这就意味着它需要一些特殊字符来表示这些模糊的匹配规则,因此这些特殊字符默认情况下并不能匹配到它们自身的字面值,而是表示某些特殊的功能。这些特殊元字符包括:., [, ], (, ), *, +, ?, ^, $, \, |。这些特殊字符的使用,会在下面进行详细讲解。正则表达式的重点和难点也就在于对正则表达式引擎的工作原理以及对这些特殊元字符掌握和灵活运用。
提示: 那么如果想匹配这些特殊元字符本身的字面值怎么办呢?我们可以通过其中一个特殊字符对其它特殊字符进行转义,从而达到可以匹配这些特殊字符自身字面值的目的。
三、元字符详解
现在我们来详细说明一下正则表达式中的特殊元字符到底能完成哪些复杂的匹配功能。
1.单个字符匹配
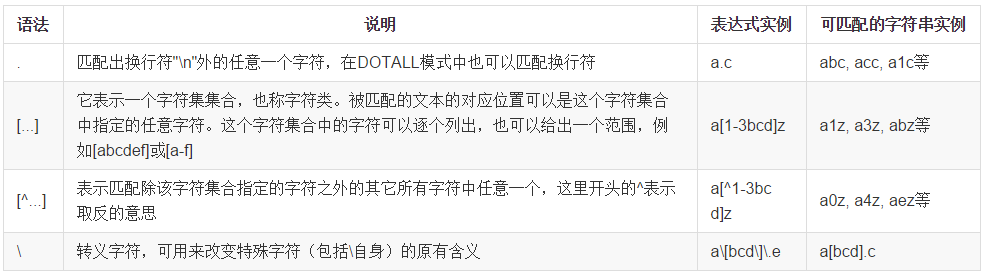
说明: 所有的特殊字符在[ ]内都将失去其原有的特殊含义:
- 有些特殊字符在[ ]中被赋予新的特殊含义,如 "^'出现在[ ]中的开始位置表示取反,它出现在[]中的其他位置表示其本身(变成了一个普通字符);
- 有些特殊字符则变为普通字符,如 '.', '*', '+', '?', '$'
- 有的普通字符变为特殊字符,如 '-' 在[ ]中的位置不是第一个字符则表示一个数字或字母区间,如果在[ ]中的位置是第一个字符则表示其本身(一个普通字符)
- 在[ ]中,如果要使用'-', '^' 或']',可在在它们前面加上反斜杠,或把'-', ']'放在第一个字符的 位置,把'^'放在非第一个字符的位置。
2. 预定义字符集
我们可以在反斜杠后面跟上一个指定的字母来表示预定义的字符集合

3. 字符次数匹配--量词
在正则表达式中,我们还可以指定匹配某个字符出现次数

说明: {m,n}中的m和n可以省略其中一个,{,n}相当于{0,n},{m,}相当于{m,整数最大值}。
我们可以得出以下结论:
- {0,1}或{,1} 等价于 ?
- {1,} 等价于 +
- {0,} 等价于 *
我们优先选择使用 ?, + 和 *,因为他们书写简单,也可以使整个正则表达式变得简洁。
说明: ? 这个字符在正则表达中与 ?, +, *, {m,n}连用时还有一个额外的功能,就是将匹配模式由贪婪模式(尽可能的增加匹配次数) 变成 非贪婪模式(尽可能减少匹配次数), 这个会在下面的内容中进行详细说明。
4. 边界匹配
正则表达式中还可以对边界位置进行匹配,如一个字符串的开头或结尾,一个单词的开头或结尾。

5. 逻辑与分组
语法 | 说明 | 表达式实例 | 可匹配到的字符串实例
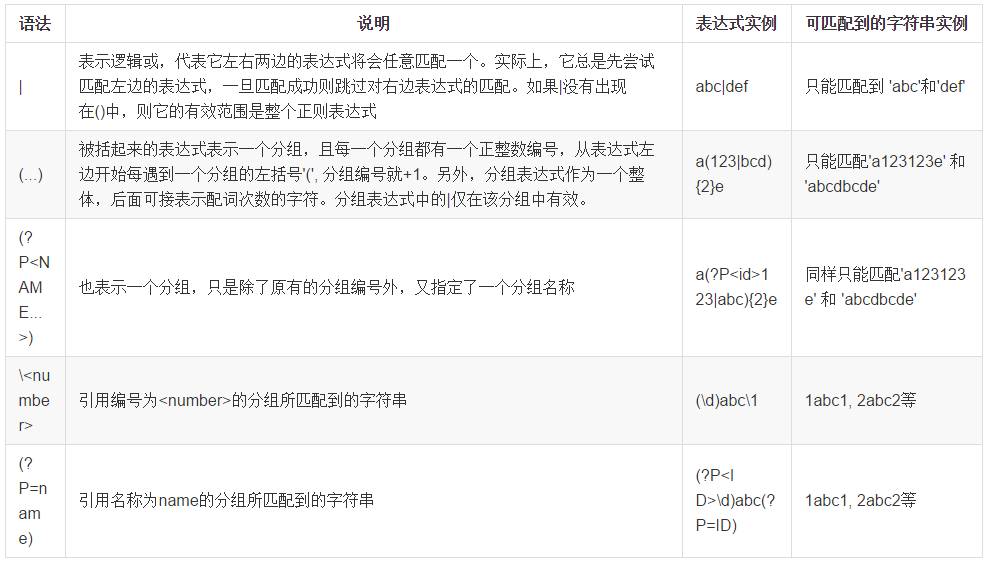
6. 特殊构造

说明: 上面所说的“不消耗字符串内容”是指只是进行匹配,但是不移动原始字符串的匹配位置,这样就可以完成多次匹配。下面有个匹配密码的正则表达式实例,就是用这个特性巧妙完成的。
四、常用正则表达式实例
通常写一个合适的正则表达式是比较耗费时间的,因此我们可以保留一些常用的正则表达式以备不时之需。但是需要说明的是,没有任何一个人敢说自己写的正则表达式是百分之百严谨的,而且也没有百分之百相同的匹配需求,因此这里只是列举我自己写的几个常用的正则表达式,欢迎大家留言讨论。
说明: 下面只是一些简单的匹配规则,实际情况中需要我们根据具体情况再这些正则表达式的首部和尾部加上相应的边界符,如:^, $, \A, \Z, \b, \B等
匹配一个网络地址(URL)
[a-zA-Z]+://[\S]+
需要说明的是,网络地址不一定是一个网页地址(http或https链接),还可能是ftp地址等。如果我们要匹配特定协议的网络地址,如http或http链接可以这样写:
(https?://)?[\S]+
匹配一个IP地址
最简单的写法:
(\d+[.]){3}\d+
严谨一点的写法:
(((?:[1-9]\d?)|(?:1\d{2})|(?:2[0-4]\d)|(?:25[0-5]))[.]){3}((?:[1-9]\d?)|(?:1\d{2})|(?:2[0-4]\d)|(?:25[0-5]))
或
((([1-9]\d?)|(1\d{2})|(2[0-4]\d)|(25[0-5]))[.]){3}(([1-9]\d?)|(1\d{2})|(2[0-4]\d)|(25[0-5]))
匹配一个邮箱地址
最简单的写法:
\S+@\S+\.\S+
严谨一点的写法(保证只出现一个@符):
[^\s@]+@[^\s@]+\.[^\s@]+
如果要非常严谨的话,就要区分不同的邮箱了,因为网易(126邮箱,163邮箱)、qq邮箱、hotmail邮箱以及gmail邮箱对邮箱名称中可以包含的字符都有不同的要求。
匹配网易邮箱:6-18个字符,只能包含字母、数字和下划线,且只能以字母开头
[a-zA-Z]\w{5,17}@(126|163)\.com
匹配qq邮箱:3-18个字符,只能包含字母、数字、点、减号和下划线
[\w.-]{3,18}@qq\.com
如果要多个邮箱的严谨匹配用一个正则表达式来匹配,比如要匹配网易邮箱和qq邮箱可以这样写:
(?:[a-zA-Z]\w{5,17}@(126|163)\.com)|(?:[\w.-]{3,18}@qq\.com)
当然,也可以分别匹配多个正则表达式,再通过程序逻辑来得到最后的结果
匹配密码是否合法:
要求比较简单的情况,比如只要求为非空字符且限定密码长度为6-18位
^\S[6-18]$
要求比较复杂的情况,比如必须同时包含含数字、大小字母、小写字母和标点符号,这就需要用到前面所说的正则表达式的特殊构造了(?=...), (?!=...)
(?=^.{6,8}$)(?=.*\d)(?=.*[a-z])(?=.*[A-Z])(?=.*\W+)
如果要求必须同时包含且只能包含数字、大小字母、小写字母和标点符号,可以这样写:
(?=^[\d\Wa-zA-Z]{6,8}$)(?=.*\d)(?=.*[a-z])(?=.*[A-Z])(?=.*\W+)
匹配大陆身份证号码(15位或18位)
\d{15}|(\d{18}|(\d{17}[Xx]))
小贴士: 当今的身份证号码有15位和18位之分。1985年我国实行居民身份证制度,当时签发的身份证号码是15位的,1999年签发的身份证由于年份的扩展(由两位变为四位)和末尾加了效验码,就成了18位。这两种身份证号码将在相当长的一段时期内共存。两种身份证号码的含义如下:
匹配日期(年-月-日)
(\d{2}|\d{4})-((0?[1-9])|(1[0-2]))-((0?[1-9])|([12][0-9])|(3[01]))
24小时制时间(小时:分钟:秒)
(((0?|1)[0-9])|(2[0-3])):([0-5][0-9]):([0-5][0-9])
其他常用正则表达式
| 匹配内容 | 正则表达式 |
|---|---|
| QQ号码 | [1-9]\d{4,} |
| 中国大陆固定电话号码 | (\d{3,4}-)?\d{7,8} |
| 中国大陆手机号码 | 1\d{10} |
| 中国大陆邮政编码 | \d{6} |
| 汉字 | [\u4e00-\u9fa5] |
| 中文及全角标点符号 | [\u3000-\u301e\ufe10-\ufe19\ufe30-\ufe44\ufe50-\ufe6b\uff01-\uffee] |
| 不含abc的单词 | (?=\w+)(?!abc) |
| 正整数 | [1-9]+ |
| 负整数 | -[1-9]+ |
| 非负整数(正整数+0) | [1-9]+ |
| 非正整数(负整数+0) | -[1-9]+ |
| 整数+0 | -?[1-9]+ |
| 正浮点数 | \d+.\d+ |
| 负浮点数 | -\d+.\d+ |
| 浮点数 | -?\d+.\d+ |
再次说明,实际情况中需要我们根据具体情况再这些正则表达式的首部和尾部加上相应的边界符,如:^, $, \A, \Z, \b, \B等
五、正则表达式的匹配过程
基于量词(如?, +, *, {m,n}, {m,})的字符重复次数匹配是正则表达式优于普通字符串处理方法的一个重要方面,也是正则表达式的一个重要组成部分。量词对正则表达式的匹配过程具有非常重大的影响,因此在介绍正则表达式的匹配过程时,必不可少的要提到量词的两个重要分类:
- 匹配优先量词 我们上面介绍的量词就是匹配优先量词包括:?, +, *, {m,n},但是不包括{m}
- 忽略优先量词 在匹配优先量词后面加上一个问号就变成了忽略优先量词,包括:??, +?, *?, {m,n}?
如果大家对这两个词不熟悉的话,那么大家一定听说过这两个词:
- 贪婪模式(或非惰性匹配) 顾名思义,就是在整个表达式匹配成功的前提下,尽可能多的去匹配量词所修饰的字符
- 非贪婪模式(或惰性匹配) 在整个表达式匹配成功的前提下,尽可能少的去匹配量词所修饰的字符
它们之间的关系是:
- 匹配优先量词修饰的子表达式使用的是就是贪婪模式(非惰性匹配);
- 忽略优先量词修饰的子表达式使用的就是模式就是非贪婪模式(惰性匹配);
下面我们通过一个实例来分析 贪婪模式 和 非贪婪模式 下的正则匹配过程:
-
要匹配的字符串:'abcbd'
-
贪婪模式正则表达式:
a[bcd]*b -
非贪婪模式正则表达式:
a[bcd]*?b
1. 贪婪模式匹配过程分析

2. 非贪婪模式匹配过程分析
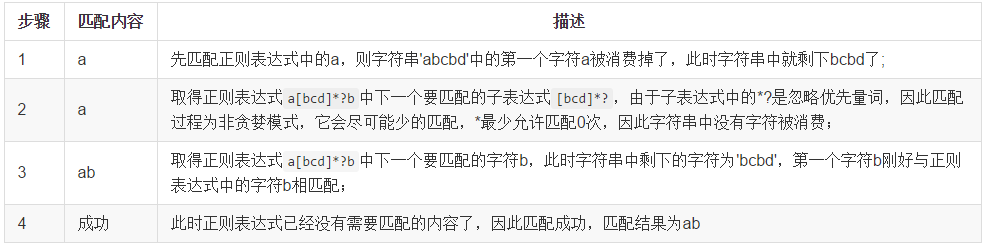
3. 总结
贪婪模式与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配;非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。另外,非贪婪模式只被部分NFA引擎所支持。从匹配效率上来看,能达到相同匹配结果时,贪婪模式的匹配效率通常会比较高,因为它回溯过程会比较少。
4. 补充示例
偶然看到一个比较好的关于贪婪模式的匹配过程示例,分享给大家。该示例出自 《这篇文章》

-
首先由“<”取得控制权,由位置0位开始尝试匹配,匹配字符“a”,匹配失败,第一轮匹配结束。第二轮匹配从位置1开始尝试匹配,同样匹配失败。第三轮从位置3开始尝试匹配,匹配字符“<”,匹配成功,控制权交给“d”。
-
“d”尝试匹配字符“d”,匹配成功,控制权交给“i”。重复以上过程,直到由“>”匹配到字符“>”,控制权交给“.*”。
-
“.*”属于贪婪模式,将从B处后的字符“t”开始,一直匹配到E处,也就是字符串结束位置,将控制权交给“<”。
-
“<”从字符串结束位置尝试匹配,匹配失败,向前查找可供回溯的状态,把控制权交给“.”,由“.”让出一个字符“c”,把控制权再交给“<”,尝试匹配,匹配失败,向前查找可供回溯的状态。一直重复以上过程,直到“.*”让出已匹配的字符“<”,实际上也就是到让出了已匹配的子串
“</div>cc"为止,“<”才匹配字符“<”成功,控制权交给“/”。 -
接下来由“/”、“d”、“i”、“v”分别匹配对应的字符成功,此时整个正则表达式匹配完毕。
六、正则表达式中的标志位-flag
上面提到的贪婪模式与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,而这里所说的标志位将会影响正则表达式的整体工作方式。不同编程语言中通常都会有预设的常量值来表示这些标志位,大家在用到时自己查下文档既可以。常用的标志位如下:
| 标志位作用 | 描述 |
|---|---|
| 表示忽略大小写的标志位 | 默认情况下,正则表达式在进行匹配时是区分大小写的 |
| 表示匹配任何字符的标志位 | 这个标志位影响的是'.'这个元字符,因为它默认情况下是匹配除换行符之外的任意字符,当指定这个标志位之后,'.'将可以匹配任意字符 |
| 表示多行匹配的标志位 | 它影响是是'^'和'$'这两个元字符,它们默认匹配的是一个字符串的开头和结尾,指定这个标志位后,它们可以匹配每一行的行首和行尾 |
七、常用匹配
正则表达式--验证手机号码:1[3|5|7|8|]\d{9}
实现手机号前带86或是+86的情况:^((\+86)|(86))?(13)\d{9}$
电话号码与手机号码同时验证:(^(\d{3,4}-)?\d{7,8})$|(1[3|5|7|8]\d{9})
提取信息中的网络链接:(h|H)(r|R)(e|E)(f|F) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?
提取信息中的邮件地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
提取信息中的图片链接:(s|S)(r|R)(c|C) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?
提取信息中的IP地址:(\d+)\.(\d+)\.(\d+)\.(\d+)
提取信息中的中国手机号码:(86)*0*13\d{9}
提取信息中的中国固定电话号码:(\(\d{3,4}\)|\d{3,4}-|\s)?\d{8}
提取信息中的中国电话号码(包括移动和固定电话):(\(\d{3,4}\)|\d{3,4}-|\s)?\d{7,14}
提取信息中的中国邮政编码:[1-9]{1}(\d+){5}
提取信息中的中国身份证号码:\d{18}|\d{15}
提取信息中的整数:\d+
提取信息中的浮点数(即小数):(-?\d*)\.?\d+
提取信息中的任何数字 :(-?\d*)(\.\d+)?
提取信息中的中文字符串:[\u4e00-\u9fa5]*
提取信息中的双字节字符串 (汉字):[^\x00-\xff]*
八、参考资料
- https://docs.python.org/3.5/howto/regex.html
- http://blog.csdn.net/lxcnn/article/details/4756030
- 一张经典的总结图(收藏了很久,忘记了出处,如果哪位知道请告知,这里会附上链接地址,谢谢。)