天成岩寺寺入山崖石做瓦,佛观殿外嶂连崖。碧空崖上水滴泄,胜似阳春雨打葩。
python从字符串中提取数字
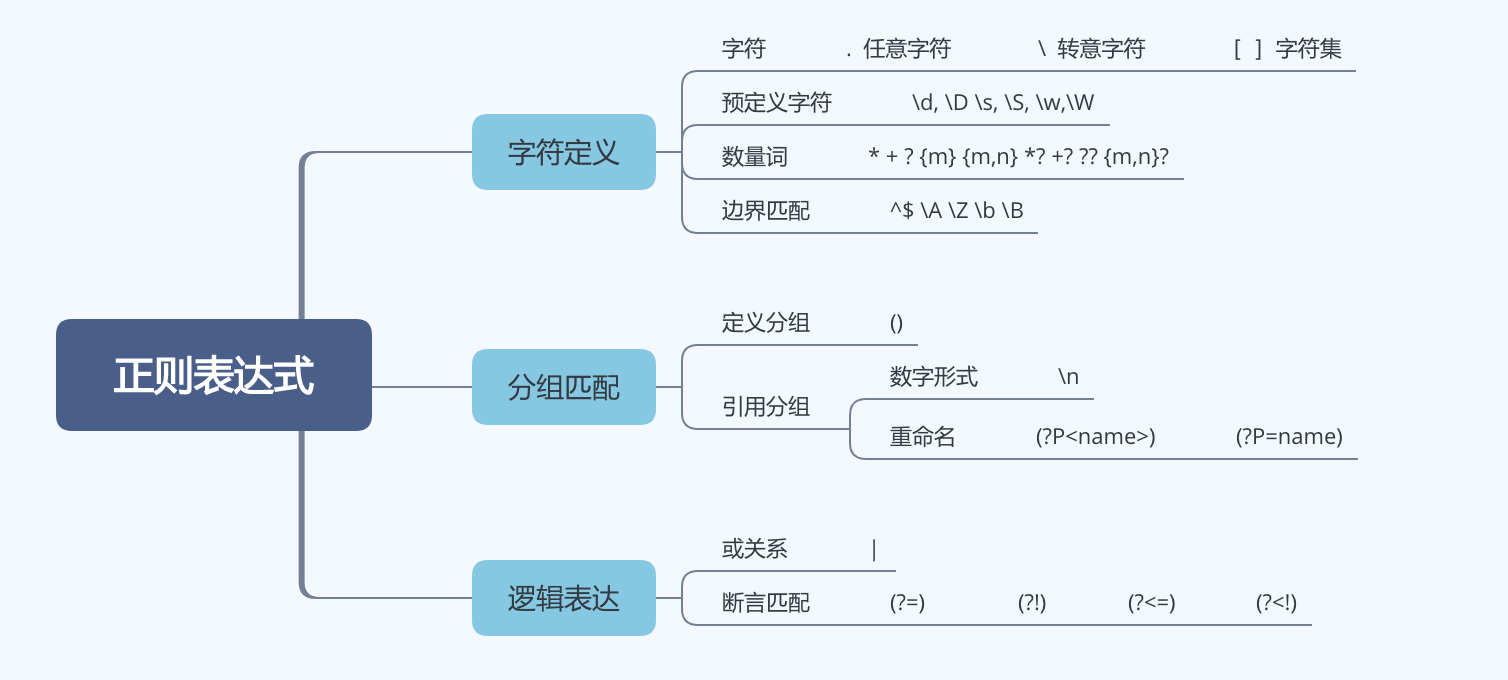
使用正则表达式,用法如下:
## 总结
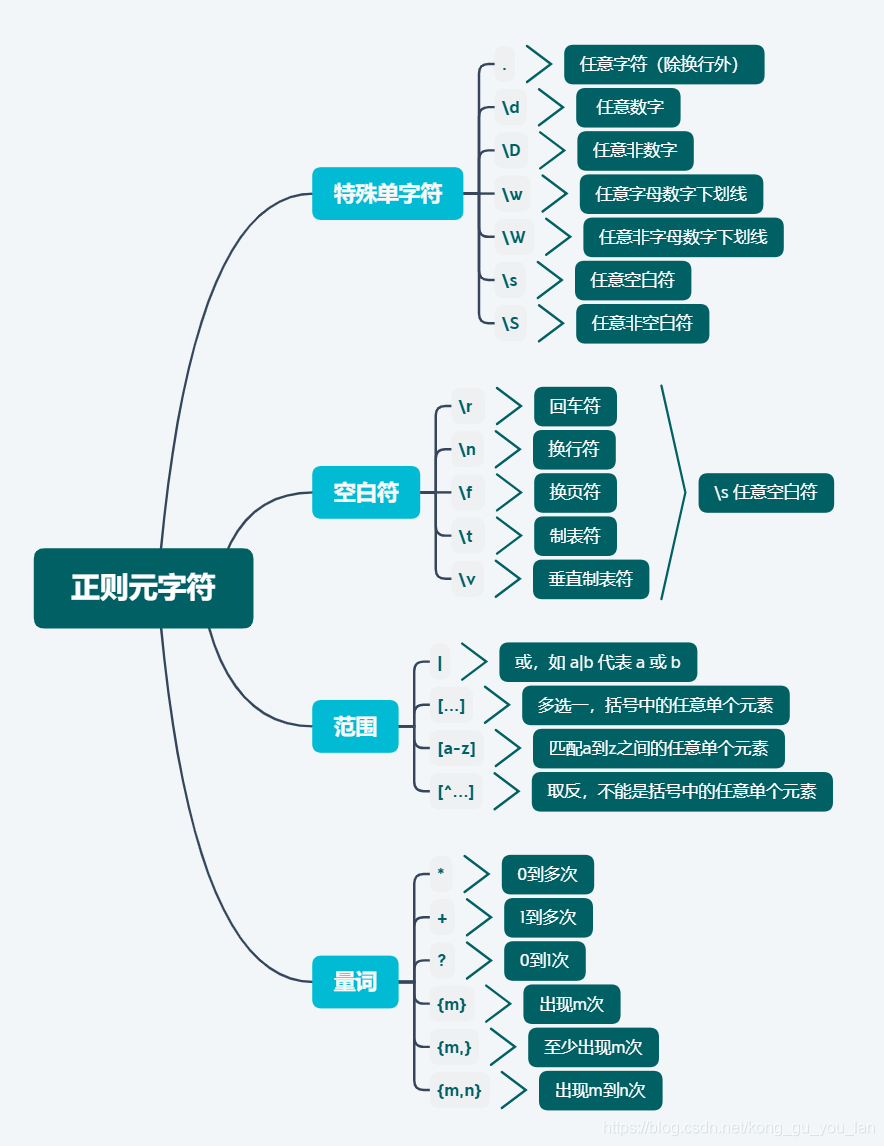
## ^ 匹配字符串的开始。
## $ 匹配字符串的结尾。
## \b 匹配一个单词的边界。
## \d 匹配任意数字。
## \D 匹配任意非数字字符。
## x? 匹配一个可选的 x 字符 (换言之,它匹配 1 次或者 0 次 x 字符)。
## x* 匹配0次或者多次 x 字符。
## x+ 匹配1次或者多次 x 字符。
## x{n,m} 匹配 x 字符,至少 n 次,至多 m 次。
## (a|b|c) 要么匹配 a,要么匹配 b,要么匹配 c。
## (x) 一般情况下表示一个记忆组 (remembered group)。你可以利用 re.search 函数返回对象的 groups() 函数获取它的值。
## 正则表达式中的点号通常意味着 “匹配任意单字符”
解题思路:
既然是提取数字,那么数字的形式一般是:整数,小数,整数加小数;
所以一般是形如:----.-----;
根据上述正则表达式的含义,可写出如下的表达式:"\d+\.?\d*";
\d+匹配1次或者多次数字,注意这里不要写成*,因为即便是小数,小数点之前也得有一个数字;\.?这个是匹配小数点的,可能有,也可能没有;\d*这个是匹配小数点之后的数字的,所以是0个或者多个;
代码如下:
import re string="A1.45,b5,6.45,8.82" print re.findall(r"\d+\.?\d*",string) # ['1.45', '5', '6.45', '8.82']
匹配指定字符串开头的数字
例如下面的string:
tensorflow:Final best valid 0 loss=0.20478513836860657 norm_loss=0.767241849151384 roc=0.8262403011322021 pr=0.39401692152023315 calibration=0.9863265752792358 rate=0.0 提取 calibration=0.9863265752792358 . # 匹配“calibration=”后面的数字 pattern = re.compile(r'(?<=calibration=)\d+\.?\d*') pattern.findall(string) # ['0.9863265752792358']
匹配包含指定字符串开头的数字
pattern = re.compile(r'(?:loss=)\d+\.?\d*') pattern.findall(string) # ['loss=0.20478513836860657', 'loss=0.767241849151384']
匹配时间,17:35:24
string = "WARNING:tensorflow: 20181011 15:28:39 Initialize training"
pattern = re.compile(r'\d{2}:\d{2}:\d{2}')
pattern.findall(string)
# ['15:28:39']
匹配时间,20181011 15:28:39
string = "WARNING:tensorflow: 20181011 15:28:39 Initialize training"
pattern = re.compile(r'\d{4}\d{2}\d{2}\s\d{2}:\d{2}:\d{2}')
pattern.findall(string)
# ['20181011 15:28:39']
总结
以上所述是小编给大家介绍的python正则表达式从字符串中提取数字的思路详解 ,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
到此这篇关于python正则表达式从字符串中提取数字的思路详解就介绍到这了。我们都有能力去解决别人的问题,却没有自信面对自己的困难。更多相关python正则表达式从字符串中提取数字的思路详解内容请查看相关栏目,小编编辑不易,再次感谢大家的支持!