积极的人在每一次忧患中都看到一个机会,而消极的人则在每个机会都看到某种忧患。
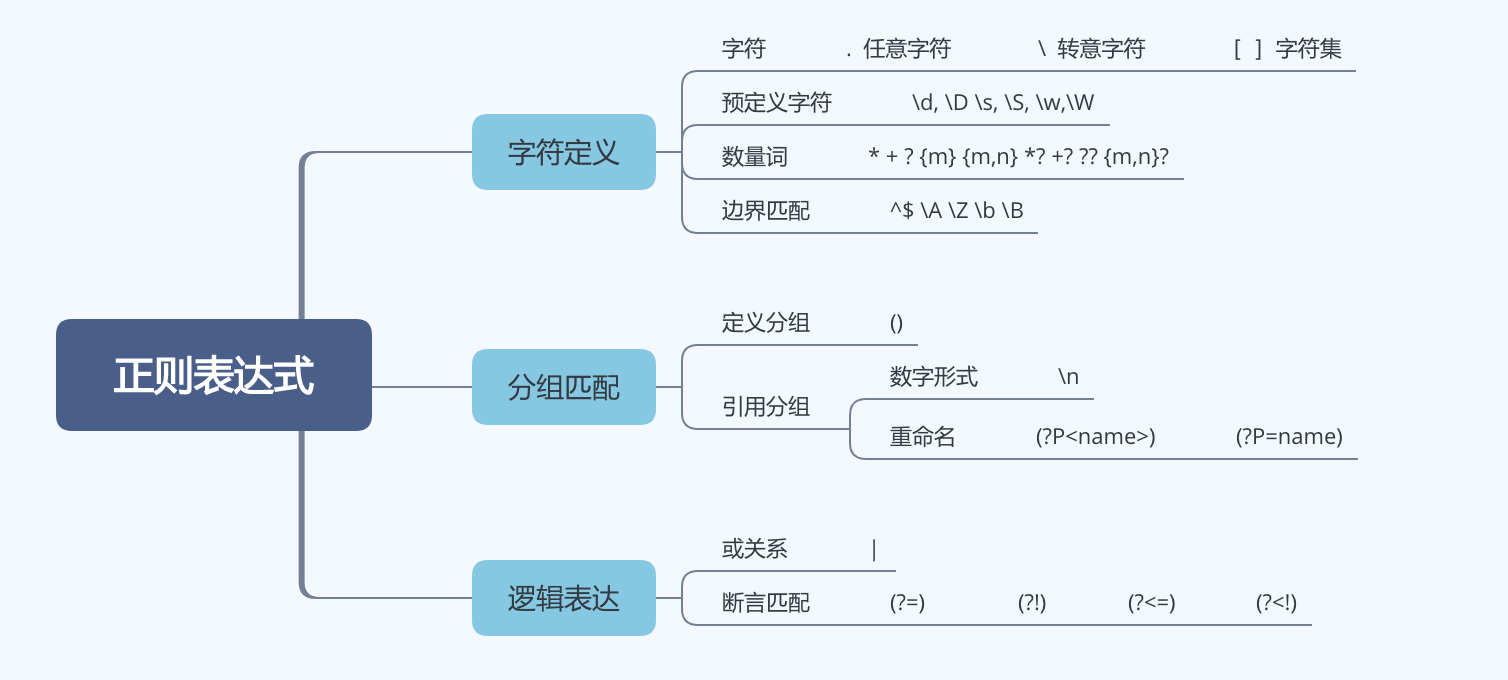
1. Regular-expression literal characters Character Matches
Alphanumeric character Itself
\0 The NUL character (\u0000)
\t Tab (\u0009)
\n Newline (\u000A)
\v Vertical tab (\u000B)
\f Form feed (\u000C)
\r Carriage return (\u000D)
\xnn The Latin character specified by the hexadecimal number nn; for example, \x0A is the same as \n
\uxxxx The Unicode character specified by the hexadecimal number xxxx; for example, \u0009 is the same as \t
\cX The control character ^X; for example, \cJ is equivalent to the newline character \n
2. Regular expression character classes Character Matches
[...] Any one character between the brackets.
[^...] Any one character not between the brackets.
. Any character except newline or another Unicode line terminator.
\w Any ASCII word character. Equivalent to [a-zA-Z0-9_].
\W Any character that is not an ASCII word character. Equivalent to [^a-zA-Z0-9_].
\s Any Unicode whitespace character.
\S Any character that is not Unicode whitespace. Note that \w and \S are not the same thing.
\d Any ASCII digit. Equivalent to [0-9].
\D Any character other than an ASCII digit. Equivalent to [^0-9].
[\b] A literal backspace (special case).
3. Regular expression repetition characters Character Meaning
{n,m} Match the previous item at least n times but no more than m times.
{n,} Match the previous item n or more times.
{n} Match exactly n occurrences of the previous item.
? Match zero or one occurrences of the previous item. That is, the previous item is optional. Equivalent to {0,1}.
+ Match one or more occurrences of the previous item. Equivalent to {1,}.
* Match zero or more occurrences of the previous item. Equivalent to {0,}.
4。 Regular expression alternation, grouping, and reference characters Character Meaning
| Alternation. Match either the subexpression to the left or the subexpression to the right.
(...) Grouping. Group items into a single unit that can be used with *, +, ?, |, and so on. Also remember the characters that match this group for use with later references.
(?:...) Grouping only. Group items into a single unit, but do not remember the characters that match this group.
\n Match the same characters that were matched when group number n was first matched. Groups are subexpressions within (possibly nested) parentheses. Group numbers are assigned by counting left parentheses from left to right. Groups formed with (?: are not numbered.
5. Regular-expression anchor characters Character Meaning
^ Match the beginning of the string and, in multiline searches, the beginning of a line.
$ Match the end of the string and, in multiline searches, the end of a line.
\b Match a word boundary. That is, match the position between a \w character and a \W character or between a \w character and the beginning or end of a string. (Note, however, that [\b] matches backspace.)
\B Match a position that is not a word boundary.
(?=p) A positive lookahead assertion. Require that the following characters match the pattern p, but do not include those characters in the match.
(?!p) A negative lookahead assertion. Require that the following characters do not match the pattern p.
6. Regular-expression flags Character Meaning
i Perform case-insensitive matching.
g Perform a global matchthat is, find all matches rather than stopping after the first match.
m Multiline mode. ^ matches beginning of line or beginning of string, and $ matches end of line or end of string.
string.replace(regexp, replacement)
Characters Replacement
$1, $2, ..., $99 The text that matched the 1st through 99th parenthesized subexpression within regexp
$& The substring that matched regexp
$' The text to the left of the matched substring
$' The text to the right of the matched substring
$$ A literal dollar sign
name.replace(/(\w+)\s*,\s*(\w+)/, "$2 $1");
text.replace(/"([^"]*)"/g, "''$1''");
text.replace(/\b\w+\b/g, function(word) {
return word.substring(0,1).toUpperCase( ) +
word.substring(1);
});
本文javascipt 正则表达式英文版到此结束。失败时郁郁寡欢,这是懦夫的表现。小编再次感谢大家对我们的支持!