正则表达式的意思是使用单个字符串来描述、匹配一系列符合某个语句规则的字符串搜索模式。
字符串的正则方法有:match()、replace()、search()、split()
正则对象的方法有:exec()、test()
正则方法讲解
match()
功能:使用正则表达式模式对字符串执行查找,并将包含查找的结果作为数组返回
函数格式:stringObj.match(rgExp) stringObj为字符串必选 rgExp为正则表达式必选项
返回值:如果能匹配则返回结果数组,如果不能匹配返回null
replace()
功能:用指定的字符串替换字符串中与正则表达式匹配的子字符串。
语法结构:
stringObject.replace(regexp,replacement)
返回值:是一个替换后的新字符串。
search()
功能:返回与正则表达式查找内容匹配的第一个子字符串的位置
语法:stringObj.search(regexp )
返回值:search 方法指明是否存在相应的匹配。如果找到一个匹配,search方法将返回一个整数值,指明这个匹配距离字符串开始的偏移位置。如果没有找到匹配,则返回 -1
注意:search() 方法不执行全局匹配,它将忽略标志 g。它同时忽略 regexp 的 lastIndex 属性,并且总是从字符串的开始进行检索,这意味着它总是返回 stringObject 的第一个匹配的位置。
split()
split() 方法用于把一个字符串分割成字符串数组。
语法
stringObject.split(separator,howmany)
参数 描述
separator 必需。字符串或正则表达式,从该参数指定的地方分割 stringObject。
howmany 可选。该参数可指定返回的数组的最大长度。如果设置了该参数,返回的子串不会多于这个参数指定的数组。如果没有设置该参数,整个字符串都会被分割,不考虑它的长度。
返回值
一个字符串数组。该数组是通过在 separator 指定的边界处将字符串 stringObject 分割成子串创建的。返回的数组中的字串不包括 separator 自身。
但是,如果 separator 是包含子表达式的正则表达式,那么返回的数组中包括与这些子表达式匹配的字串(但不包括与整个正则表达式匹配的文本)
exec()
语法结构:
RegExpObject.exec(string)
正则表达式exec()函数:
exec() 方法用于检索字符串中的正则表达式的匹配。
返回值是一个数组,但是此数组的内容和正则对象是否是全局匹配有着很大关系:
1.没有g修饰符:
在非全局匹配模式下,此函数的作用和match()函数是一样的,只能够在字符串中匹配一次,如果没有找到匹配的字符串,那么返回null,否则将返回一个数组,数组的第0个元素存储的是匹配字符串,第1个元素存放的是第一个引用型分组(子表达式)匹配的字符串,第2个元素存放的是第二个引用型分组(子表达式)匹配的字符串,依次类推。同时此数组还包括两个对象属性,index属性声明的是匹配字符串的起始字符在要匹配的完整字符串中的位置,input属性声明的是对要匹配的完整字符串的引用。
特别说明:
在非全局匹配模式下,IE浏览器还会具有lastIndex属性,不过这时是只读的。
2.具有g修饰符:
在全局匹配模式下,此函数返回值同样是一个数组,并且也只能够在字符串中匹配一次。不过此时,此函数一般会和lastIndex属性匹配使用,此函数会在lastIndex属性指定的字符处开始检索字符串,当exec()找到与表达式相匹配的字符串时,在匹配后,它将lastIndex 属性设置为匹配字符串的最后一个字符的下一个位置。可以通过反复调用exec()函数遍历字符串中的所有匹配,当exec()函数再也找不到匹配的文本时,它将返回null,并把lastIndex 属性重置为0。
数组的内容结构和没有g修饰符时完全相同。
特别说明:
如果在一个字符串中完成了一次模式匹配之后要开始检索新的字符串,就必须手动地把lastIndex属性重置为0。
test()
用于检测一个字符串是否匹配某个模式.
返回一个 Boolean 值,它指出在被查找的字符串中是否匹配给出的正则表达式。
regexp.test(str)
正则匹配注意要点
正则表达式test(),正则加g和不加g的区别
问题如下图:3在正则测试时为false
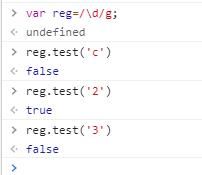
g表示全文查找。而且在正则表达式内部有一个**lastIndex**来记录匹配的位置,第一次调用reg后,那么lastIndex就不再等于0,当下次在调用该方法的时候,字符串的匹配会从lastIndex位置进行匹配,所以因为lastIndex的变化匹配str内的数字是跳着匹配的,只要去掉g就可以了
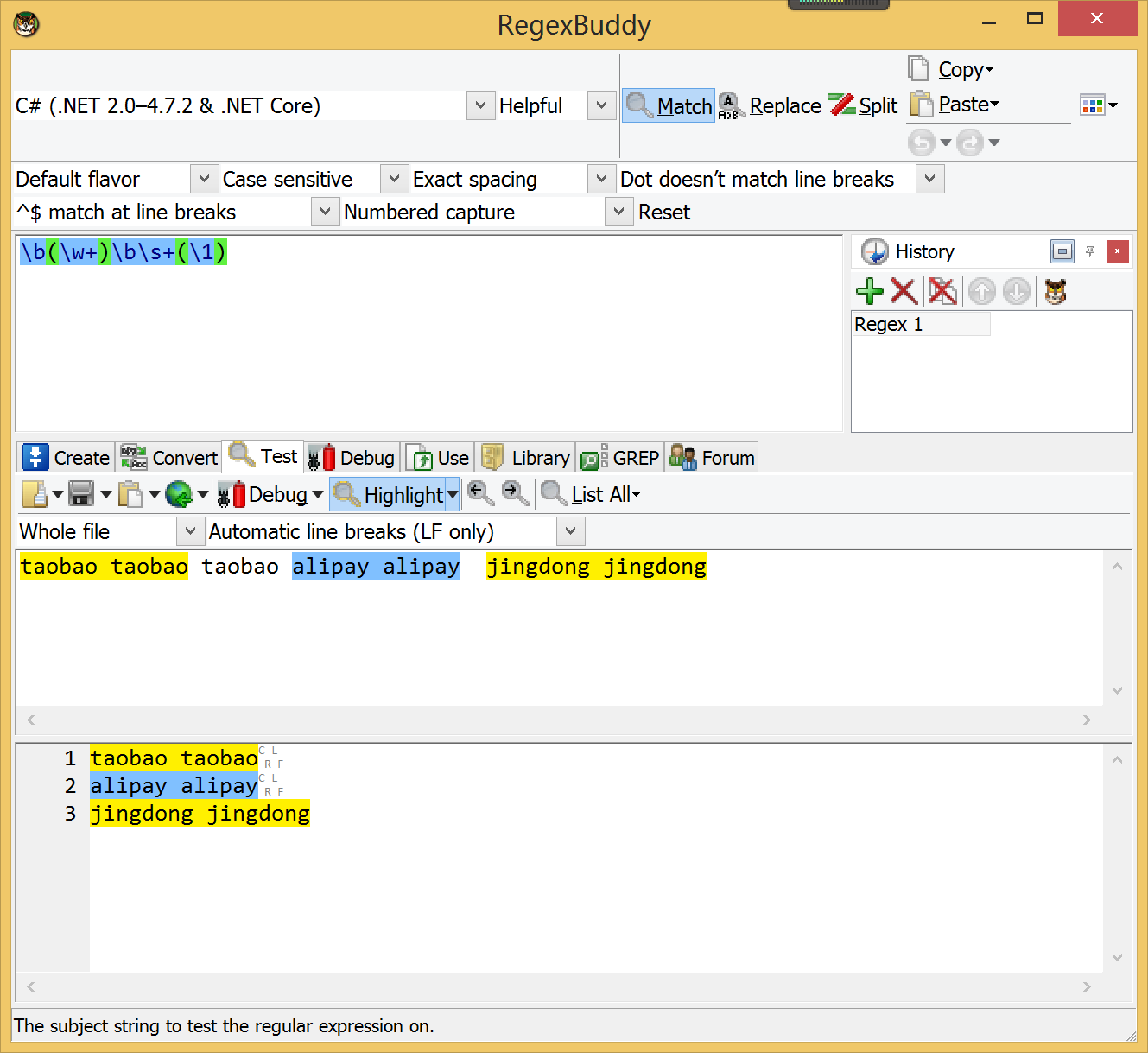
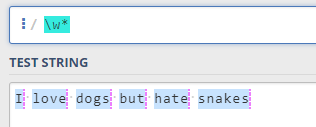
用\w匹配单词遇到空串的问题
我使用了\w* 结果如下图 没隔一个单词出现一个空。原因就在于用了* (重复零次或更多次),改为+(重复一次或更多次)就好了,就是说最少有一个字母才算一个单词。
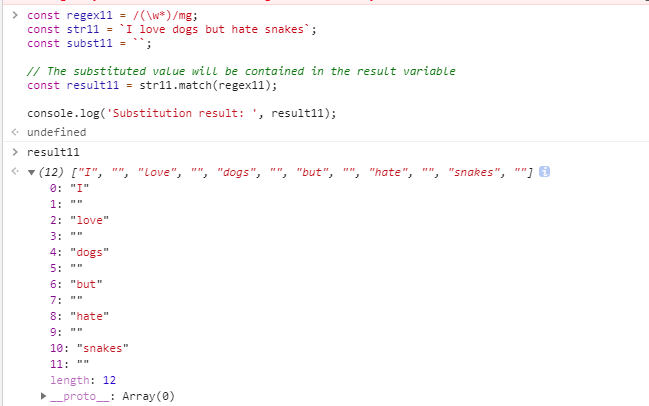
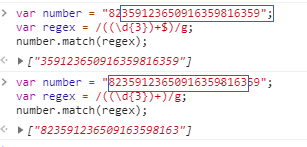
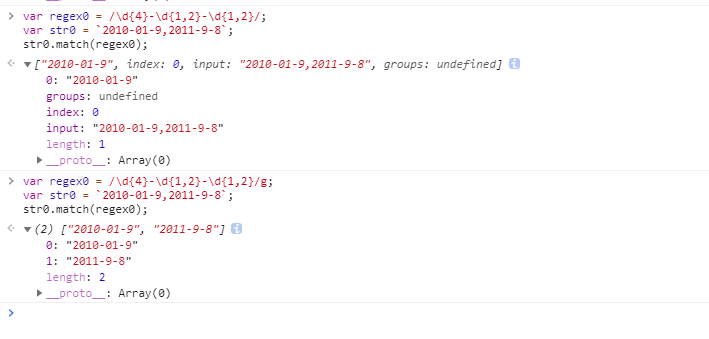
正则匹配分组时加不加g(是否全局搜索)的match结果
有()分组不设置g时,匹配第一个整体符合正则规则的字符串,返回结果数组第一个值“2010-01-9”,并且可以分别匹配出每一个分组的值从数组下第二个值开始,["2010","01","9"];
有()分组且设置g时,匹配所有符合正则规则的字符串,返回结果[“2010-01-9”,“2011-9-8”];
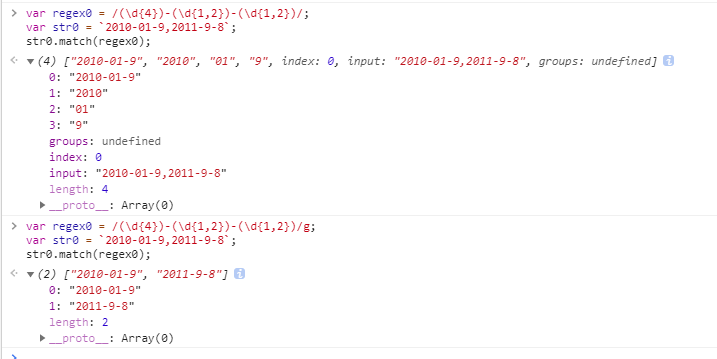
无()分组不设置g时,匹配第一个整体符合正则规则的字符串,返回结果[“2010-01-9”];
无()分组且设置g时,匹配所有符合正则规则的字符串,返回结果[“2010-01-9”,“2011-9-8”];
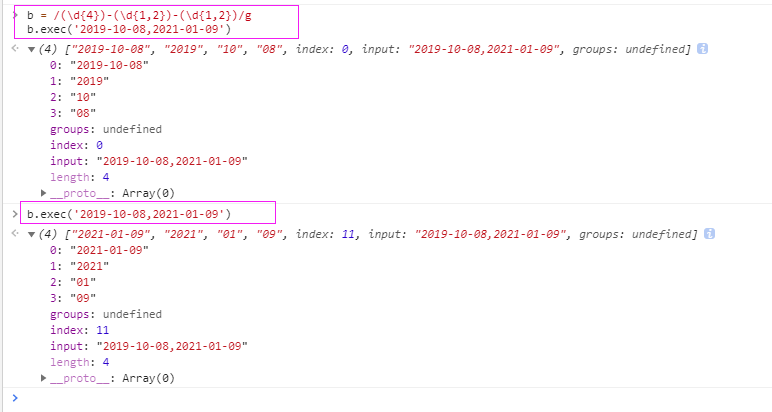
exec 从字符串中提取(每次只能匹配一组数据)

如果想全部匹配 可以加g,需要多次执行exec。(参照第一个问题说到的lastIndex)

如果正则中有分组,使用/g可以匹配出所有符合正则规则的字符串,且内部有分组
split切割+正则表达式
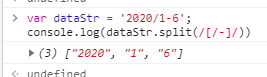
var dataStr = '2020/1-6'
// 将上面的字符串中日期格式切割成年、月、日
console.log(dataStr.split(/[/-]/))// 利用正则表达式匹配出/或
使用Reg.$1-Reg.$9提取
RegExp 是javascript中的一个内置对象。为正则表达式。
RegExp.$1是RegExp的一个属性,指的是与正则表达式匹配的第一个 子匹配(以括号为标志)字符串,以此类推,RegExp.$2,RegExp.$3,..RegExp.$99总共可以有99个匹配
如果你直接在控制台打印RegExp, 出现的一定是一个空字符串: ""。那么, 我们在什么时候可以使用RegExp.$1呢?
其实RegExp这个对象会在我们调用了正则表达式的方法后, 自动将最近一次的结果保存在里面, 所以如果我们在使用正则表达式时, 有用到分组, 那么就可以直接在调用完以后直接使用RegExp.$xx来使用捕获到的分组内容, 如下
const r = /^(\d{4})-(\d{1,2})-(\d{1,2})$/
r.exec('2019-10-08')
console.log(RegExp.$1) // 2019
console.log(RegExp.$2) // 10
console.log(RegExp.$3) // 08
replace方法的第二个参数可以使用的特殊字符含义:
1. ```$&`` : 表示匹配到的结果。'javascript'.replace(/script/, '$&$&') -> ‘javascriptscript’ 2. ```$\```` : 表示匹配到的结果的左边或者说前面的那一堆字符串。 'javascript'.replace(/script/, '$& 不是 $`') -> "javascript 不是 java" 3. ```$'``` : 表示匹配到的结果的右边或者说后面的那一堆字符串。 '我是猪'.replace(/我是/, "$&$'") -> "我是猪猪" 4. ```$$``` : 表示$字符。
正则中的 ?= 、?<= 、?!、 ?<!=
-
?=: 询问后面跟着的东西是否等于这个 /b(?=a)/.test(‘bab’) -
?<=: 询问是否以这个东西开头 /(?<=a)b/.test(‘ab’) -
?!: 询问后面跟着的东西是否不是这个 /b(?!a)/.test(‘bb’) -
?<!=:询问是否不是以这个东西开头 /(?<!=a)b/.test(‘bb’)
$的作用可以优先从行末匹配