前文我们了解了redis的常用数据类型相关命令的使用和说明,回顾请参考https://www.haodaima.com/article/120364.htm今天我们来聊一下redis的高可用组件sentinel;首先来回顾下redis的主从同步,主从同步最主要的作用是让master的数据在其他服务器上实时存在副本,起到了备份的效果;对于redis的读写来说,主从架构能够让读的请求分散到多个从服务器上,从而降低了单台redis读请求的io压力,同时也提高了redis读请求的并发能力;通常为了数据的一致性,从服务器一旦成为某一台redis的slave,那么从服务器上之前有的数据会被清空,然后把master发送过来的数据应用到内存,从而实现和master数据一致;除此之外slave通常会是只读属性,也就说slave端只能执行读操作,写操作会被拒绝,所以写请求始终是由master来完成;
那么问题来了,对于这种主从复制架构的环境中,如果master宕机了,master宕机意味着整个系统将不能够写数据到redis,很显然这种情况我们应该及时解决;怎么解决呢?有没有这样的一组件帮我们对master做实时的监控,一旦发现master宕机就提升一个slave当选新的master,如果原master还有其他slave,将其他slave都从属于新的master;除此之外它还应该让系统在发生切换master时触发报警通知,让管理员尽快把坏掉的master修复上线;对,sentinel就有我们上述的这些功能,它能够监控主从同步集群中的master节点,在master发生宕机后能够自动故障转移,将提升一台slave作为新的master,然后通知管理员;
Sentinel是一个分布式系统,我们可以在一个架构中运行多个sentinel,这些sentinel进程使用流言协议(gossipprotocols)来接收关于 Master是否下线的信息,并使用投票协议(Agreement Protocols)来决定是否执行自动故障迁移,以及选择哪个 Slave 作为新的 Master。每个sentinel进程会向其他sentinel进程、master、slave定时发送消息,以确保对方是否”活”着,如果发现对方在指定配置时间(可配置的)内未得到回应,则暂时认为对方已掉线,也就是所谓的”主观认为宕机” ,英文名称:Subjective Down,简称 SDOWN。有主观宕机,肯定就有客观宕机。
当多个sentinel进程中多数的sentinel进程在对 Master 做出 SDOWN 的判断,并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后,得出的 Master Server 下线判断,这种方式就是“客观宕机”,英文名称是:Objectively Down, 简称 ODOWN。通过一定的 vote 算法,从剩下的 slave 从服务器节点中,选一台提升为 Master 服务器节点,然后自动修改相关配置,并开启故障转移(failover)。
配置使用sentinel
环境说明
| 角色 | ip地址 | 端口 |
| master | 192.168.0.41 | 6379 |
| slave01 | 192.168.0.42 | 6379 |
| slave02 | 192.168.0.43 | 6379 |
| sentinel01 | 192.168.0.41 | 26379 |
| sentinel02 | 192.168.0.42 | 26379 |
| sentinel03 | 192.168.0.43 | 26379 |
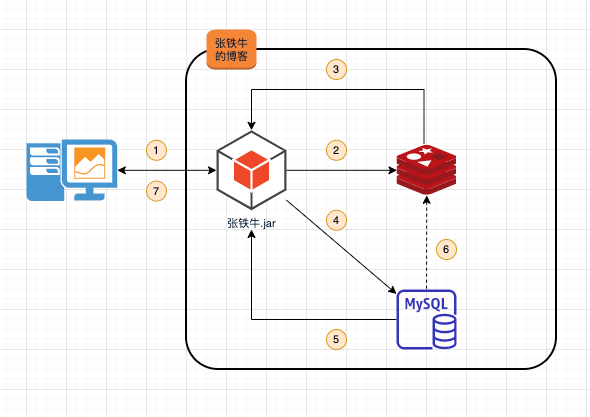
架构图
提示:从上面的架构图可以知道,首先我们必须要有一个主从架构的集群,然后在部署sentinel 来对主从同步集群做监控;
redis主从复制集群搭建
1、在192.168.0.41/42/43上安装redis,可以使用yum安装,也可以使用编译安装,redis安装请参考https://www.haodaima.com/article/79096.htm
2、配置192.168.0.41/42/43上的redis监听在非本机127.0.0.1上并配置42/43上的redis从属于192.168.0.41
master
slave01
slave02
提示:redis支持在线修改配置,保存配置到配置文件;SLAVEOF 指令用于指定redismaster的ip地址和端口,表示把该redis配置成对应master的slave角色;CONFIG REWRITE是把我们的配置保存到配置文件;
在master上查看是否有两个从节点连接到master
验证:在master上写数据,看看是否能够及时同步到两个slave上?
提示:可以看到在主库上写数据,从库上能够及时的同步主库上的数据;到此redis的主从集群就搭建完毕了;
配置sentinel,让其监控master
提示:三个sentinel的配置都是一样的,这里需要明确指定监控主从同步集群的master的ip地址和端口,以及有效法定票数,有效法定票数指的是至少有多少个sentinel主观认为master down了,然后才触发选举新master操作;通常在这种流言协议中,一般都是大于集群半数,如果是3台sentinel,至少要2台主观认为master宕机,才开始触发选举新master;如果是5台,那至少要3台;如果master配置的有认证密码,我们还需要在sentinel中指定认证密码;
sentinel配置文件说明
bind:该指令和redis配置文件中的bind是同样的用法,用于指定sentinel的监听地址;默认不指定,监听本机所有可用地址;
protected-mode:指定是否开启保护模式;
port:用于指定sentinel的监听端口;默认是26379
daemonize:用于指定sentinel是否运行为守护进程,yes表示运行为后台守护进程;no表示不运行为守护进程,直接在前台运行;
pidfile:指定pid文件路径;
logfile:指定日志文件路径;
dir:指定sentinel的工作路径;
sentinel monitor <master-name> <ip> <redis-port> <quorum>:用于指定监控master节点的ip地址和端口以及有效法定票数;其中<master-name>是给监控的master一个名称,可以随便写,起标识的作用;<quorum>表示sentinel集群的quorum机制,即至少有quorum个sentinel节点同时判定主节点故障时,才认为其真的故障;
sentinel auth-pass <master-name> <password>:指定master认证密码;通常都需要设置密码,并且master的密码和slave的密码应该是一样;
sentinel down-after-milliseconds <master-name> <milliseconds>:配置监控到指定的集群的主节点异常状态持续多久方才将标记为“故障”;
sentinel parallel-syncs <master-name> <numslaves>:指在failover过程中,能够被sentinel并行配置的从节点的数量;
sentinel failover-timeout <master-name> <milliseconds>:sentinel必须在此指定的时长内完成故障转移操作,否则,将视为故障转移操作失败;
sentinel notification-script <master-name> <script-path>:通知脚本,此脚本被自动传递多个参数;
了解了sentinel的配置文件,接下我们把3台sentinel都启动起来
master
slave01
slave02
提示:从上面的信息可以看到3个sentinel都监控master的ip地址和端口,其实他们3个的配置文件都是一样的;
查看sentinel日志
提示:从上面的日志信息可以了解到sentinel监控的master是192.168.0.41:6379;并且有两个slave分别是192.168.0.42:6379和192.168.0.43:6379;
查看sentinel状态
提示:它提示我们开启了保护模式;
关闭保护模式
重启sentinel,再次查看sentinel状态
[root@master ~]# systemctl restart redis-sentinel.service [root@master ~]# ss -tnl State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 511 *:26379 *:* LISTEN 0 511 *:6379 *:* LISTEN 0 128 *:22 *:* LISTEN 0 100 127.0.0.1:25 *:* LISTEN 0 511 :::26379 :::* LISTEN 0 128 :::22 :::* LISTEN 0 100 ::1:25 :::* [root@master ~]# redis-cli -h 192.168.0.41 -p 26379 192.168.0.41:26379> info sentinel # Sentinel sentinel_masters:1 sentinel_tilt:0 sentinel_running_scripts:0 sentinel_scripts_queue_length:0 sentinel_simulate_failure_flags:0 master0:name=mymaster,status=ok,address=192.168.0.41:6379,slaves=2,sentinels=3 192.168.0.41:26379> info clients # Clients connected_clients:3 client_longest_output_list:0 client_biggest_input_buf:0 blocked_clients:0 192.168.0.41:26379> CLIENT LIST id=2 addr=192.168.0.42:59048 fd=14 name=sentinel-f60b324b-cmd age=38 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=ping id=3 addr=192.168.0.43:37480 fd=15 name=sentinel-eada229c-cmd age=38 idle=1 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=publish id=4 addr=192.168.0.41:36706 fd=16 name= age=32 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=client 192.168.0.41:26379>
提示:从上面的状态信息可以看到当前sentinel监控的master是出于正常ok状态,有两个slave和3个sentinel;对于192.168.0.41:26379目前有3个客户端连接,二个是sentinel,一个本机;到此3台sentinel搭建启动完成;
验证:把master宕机,看看sentinel是否将在两个从节点选举一个为新master?是否将另外一个slave重新指向新master?
在slave01上查看主从同步信息
提示:第一次查看只是告诉我们master宕机了,第二次查看就告诉我们当前节点为master,并且拥有一个slave节点,这说明已经完成了故障转移,slave01已经被提升为新的master了;
在192.168.0.43上查看主从信息,看看是否指向新的master?
提示:在slave02上看主从同步信息,可以看到slave02已经从属新master了;
查看故障转移时 sentinel日志
提示:从上面的日志信息可以了解到,在从sdown到odown后,就会触发vote算法开始选举leader;然后将原master降级为slave,然后将选举出来的leader原salve属性去除(slaveof no one);然后提升新master,然后将剩下的slave重新配置新master为主;最后是切换master,开始新的监控;
查看故障 转移后的 redis 配置文件
提示:故障转移后 redis.conf 中的 slaveof 行的 master IP 会被修改,sentinel.conf 中的 sentinel monitor IP 会被修改。同时在sentinel配置文件的末尾还会有添加known-slave和known-sentinel等信息;
修复旧master 让其重新上线
提示:把原master启动后,它自动就成为了新主的slave;这主要是因为sentinel在故障转移时把其配置文件中的slaveof 修改成新的master地址了;
在新master上查看主从同步信息
提示:在没有恢复原master时,在新master上查看主从同步信息,只能看到一个salve,启动原master后,在看就有两个slave是在线;
总结
到此这篇关于Redis服务之高可用组件sentinel的文章就介绍到这了,更多相关Redis服务之高可用组件sentinel内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!