为什么要做限流
首先让我们先看一看系统架构设计中,为什么要做“限流”。
旅游景点通常都会有最大的接待量,不可能无限制的放游客进入,比如故宫每天只卖八万张票,超过八万的游客,无法买票进入,因为如果超过八万人,景点的工作人员可能就忙不过来,过于拥挤的景点也会影响游客的体验和心情,并且还会有安全隐患;「只卖N张票,这就是一种限流的手段」。
软件架构中的服务限流也是类似,也是当系统资源不够的时候,已经不足以应对大量的请求,为了保证服务还能够正常运行,那么按照规则,「系统会把多余的请求直接拒绝掉,以达到限流的效果」;
不知道大家注意过没有,比如双11,刚过12点有些顾客的网页或APP会显示下单失败的提示,有些就是被限流掉了。
常见的限流算法
计数法
顾名思义就是来一个,记录一个,比如我1分钟只能处理1000个请求,那么我们就可以设置一个计数器,来一个请求就incr+1,当1分钟之内的数量大于等于1000之后不处理了即可,伪代码如下
$redis = new Redis();
$redis->connect('127.0.0.1', 6379);
$rate_limit = 1000; //限制个数
$rate_seconds = 60; //限制时间
$redis_key = "redis_limit";
$count = $redis->get($redis_key);
if ($count >= $rate_limit){ //判断60秒内请求个数是否已经达到上限
//直接返回,不处理请求
return
}
$redis->incr($redis_key, 1);//请求计数
$redis->expire($redis, $rate_seconds); //设置过期时间 60s
//to do 业务逻辑处理.......
这种计数方式比较简单快捷,但是有很大的缺点,因为请求的访问不一定是很平稳的,如果0:59过来了1000个请求,1:01已经是下一个窗口,又过来了1000个请求,但实际上三秒内来了2000个请求,已经超过我们的限流上限了。所以这种方法是不推荐的。
滑动窗口算法
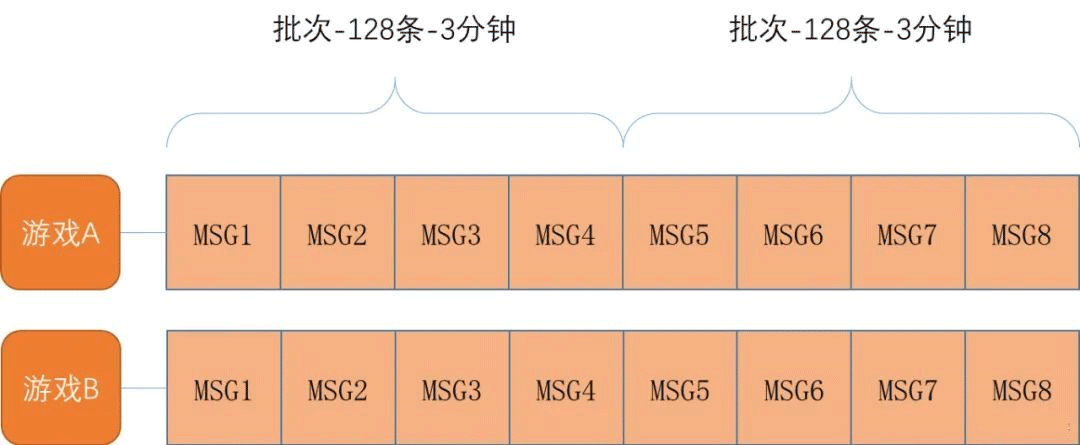
还拿上面的例子,一分钟分6份,每份10秒;每过10秒钟,我们的时间窗口就会往右滑动一格,每个格子都有独立的计数器,我们每次都计算时间窗口内的数量,可以解决计数器法中的问题,而且当滑动窗口的格子越多,那么限流的统计就会越精确。具体可以参考下图,看图比较清晰
伪代码实现如下
function api_limit($scene, $period, $maxCount){
$redis = new Redis();
$redis->connect('127.0.0.1', 6379);
$key = sprintf('hist:%s', $scene); //限流场景唯一标识
$now = msectime(); // 毫秒时间戳,这样更精确
$pipe=$redis->multi(Redis::PIPELINE); //使用管道提升性能
$pipe->zadd($key, $now, $now); //value 和 score 都使用毫秒时间戳
$pipe->zremrangebyscore($key, 0, $now - $period); //移除时间窗口之前的行为记录,剩下的都是时间窗口内的
$pipe->zcard($key); //获取窗口内的行为数量
$pipe->expire($key, $period/1000 + 1); //多加一秒过期时间
$replies = $pipe->exec();
return $replies[2] <= $maxCount; //$replies[2]为zcard返回的个数 如果zcard结果大于maxCount,则不处理结果
}
for ($i=0; $i<20; $i++){ //测试限流是否实现代码
var_dump(isActionAllowed("uniq_scene", 60*1000, 5)); //执行可以发现只有前5次是通过的
}
//返回当前的毫秒时间戳
function msectime() {
list($msec, $sec) = explode(' ', microtime());
$msectime = (float)sprintf('%.0f', (floatval($msec) + floatval($sec)) * 1000);
return $msectime;
}
这段代码还是略显复杂,需要读者花一定的时间好好啃。它的整体思路就是:每一个行为到来时,都维护一次时间窗口。将时间窗口外的记录全部清理掉,只保留窗口内的记录。
因为这几个连续的 Redis 操作都是针对同一个 key 的,使用 pipeline 可以显著提升Redis 存取效率。「但这种方案也有缺点,因为它要记录时间窗口内所有的行为记录,如果这个量很大,比如限定 60s 内操作不得超过 100w 次这样的参数,它是不适合做这样的限流的,因为会消耗大量的存储空间」。
后面还有漏桶算法和令牌桶算法,由于各自的实现比较复杂,所以准备各自新开一篇文章单独描述
到此这篇关于redis限流的实际应用的文章就介绍到这了,更多相关redis限流内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!