Intro
有的时候我们需要对 Redis 的数据进行迁移,今天介绍一下通过 RDB(快照)文件进行 Redis 数据的备份和还原
Redis 持久化
Redis 的数据持久化有两种机制,一种是 RDB(Redis Database),一种是 AOF(Append Only File)
Redis 提供了不同级别的持久化方式:
- RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储.
- AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大.
- 如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式.
- 你也可以同时开启两种持久化方式, 在这种情况下, 当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整.
RDB的优点
- RDB是一个非常紧凑的文件,它保存了某个时间点得数据集,非常适用于数据集的备份,比如你可以在每个小时报保存一下过去24小时内的数据,同时每天保存过去30天的数据,这样即使出了问题你也可以根据需求恢复到不同版本的数据集.
- RDB是一个紧凑的单一文件,很方便传送到另一个远端数据中心或者亚马逊的S3(可能加密),非常适用于灾难恢复.
- RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能.
- 与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些.
RDB的缺点
- 如果你希望在redis意外停止工作(例如电源中断)的情况下丢失的数据最少的话,那么RDB不适合你.虽然你可以配置不同的save时间点(例如每隔5分钟并且对数据集有100个写的操作),是Redis要完整的保存整个数据集是一个比较繁重的工作,你通常会每隔5分钟或者更久做一次完整的保存,万一在Redis意外宕机,你可能会丢失几分钟的数据.
- RDB 需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,fork的过程是非常耗时的,可能会导致Redis在一些毫秒级内不能响应客户端的请求.如果数据集巨大并且CPU性能不是很好的情况下,这种情况会持续1秒,AOF也需要fork,但是你可以调节重写日志文件的频率来提高数据集的耐久度.
AOF 优点
- 使用AOF 会让你的Redis更加耐久: 你可以使用不同的fsync策略:无fsync,每秒fsync,每次写的时候fsync.使用默认的每秒fsync策略,Redis的性能依然很好(fsync是由后台线程进行处理的,主线程会尽力处理客户端请求),一旦出现故障,你最多丢失1秒的数据.
- AOF文件是一个只进行追加的日志文件,所以不需要写入seek,即使由于某些原因(磁盘空间已满,写的过程中宕机等等)未执行完整的写入命令,你也也可使用redis-check-aof工具修复这些问题.
- Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
- AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF 缺点
- 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
- 根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。
废话不多说直接看下面的示例吧,通过 docker 运行一个 redis 实例,并设置一些数据,然后导出 RDB 文件,再运行一个 redis 实例通过 RDB 文件还原数据
备份
通过 docker run -d --name redis-test-1 redis:alpine 命令来创建一个 redis 实例,接着 SET 一个 key 保存到我们的 redis,使用命令 SET hello world 写入测试数据,你也可以写入别的自己想写的数据,接着可以使用 keys * 来验证数据是否写入成功
测试数据写入成功后使用 SAVE 命令来创建 RDB 文件,命令执行成功后我们可以在 /data 目录下看到会有一个 dump.rdb 文件,这就是我们想要的 RDB 文件,通过 docker cp 命令可以把这个文件拷贝到 host 目录下
还原
通过上面 RDB 文件我们可以在 redis 启动的时候还原 RDB 文件中的数据,只需要在 Redis 启动前把 RDB 文件放在 redis 的 data 目录下就可以了。
执行 docker run --rm --name redis-test-2 -v ${pwd}/data:/data redis:alpine
这个命令我是在 powershell 上执行的,如果执行在 Linux 上执行需要把 ${pwd} 换成 $(pwd) 来表示当前目录
可以看到上面的日志里有 Loading RDB ... 就是在加载 RDB 文件中的数据
我们再来验证一下 RDB 文件里的数据是否真的加载到了新的 redis 实例中,先来验证一下 data 目录是否正常挂载了,执行 docker exec -it redis-test-2 sh 来进入到 redis 实例容器中,ls 查看 data 目录中的文件看是否有我们期望的 RDB 文件,接着进入 redis-cli 来验证数据是否存在
使用 keys * 来列出来所有的 key 信息,可以看到有我们在上一个 redis 里写入的测试数据了,再来使用 GET hello 来验证数据是否正确,至此我们的数据就还原到新的 redis 实例中了~~
More
当 Redis 需要保存 dump.rdb 文件时, 服务器执行以下操作:
- Redis 调用forks. 同时拥有父进程和子进程。
- 子进程将数据集写入到一个临时 RDB 文件中。
- 当子进程完成对新 RDB 文件的写入时,Redis 用新 RDB 文件替换原来的 RDB 文件,并删除旧的 RDB 文件。
这种工作方式使得 Redis 可以从写时复制(copy-on-write)机制中获益。
如果 redis 被访问的比较频繁,可以使用 BGSAVE 代替 SAVE 来异步创建 RDB 备份
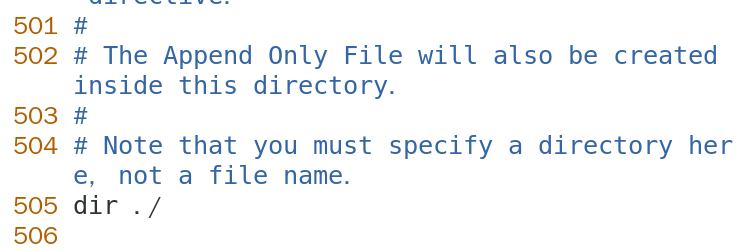
如果 redis 不是使用 docker 来使用的,/data 目录可以在 redis-cli 中使用 CONFIG GET dir 来获取保存 rdb 文件的目录,默认保存的 RDB 文件名称是 dump.rdb,如果有修改过,可以通过 CONFIG GET dbfilename 来获取当前使用的文件名
References
https://redis.io/topics/persistence
http://redis.cn/topics/persistence.html
到此这篇关于Redis 通过 RDB 方式进行数据备份与还原的文章就介绍到这了,更多相关Redis数据备份与还原内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!