1. Stream简介
Stream是redis最复杂的一个数据结构, 也是redis 5.0的一个重要更新。Redis Stream 主要用于消息队列(MQ,Message Queue),这样的数据结构其实很常见, 比如腾讯云的CMQ、阿里的RocketMQ、ActiveMQ、RabbitMQ以及炙手可热的Kafka等。
Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
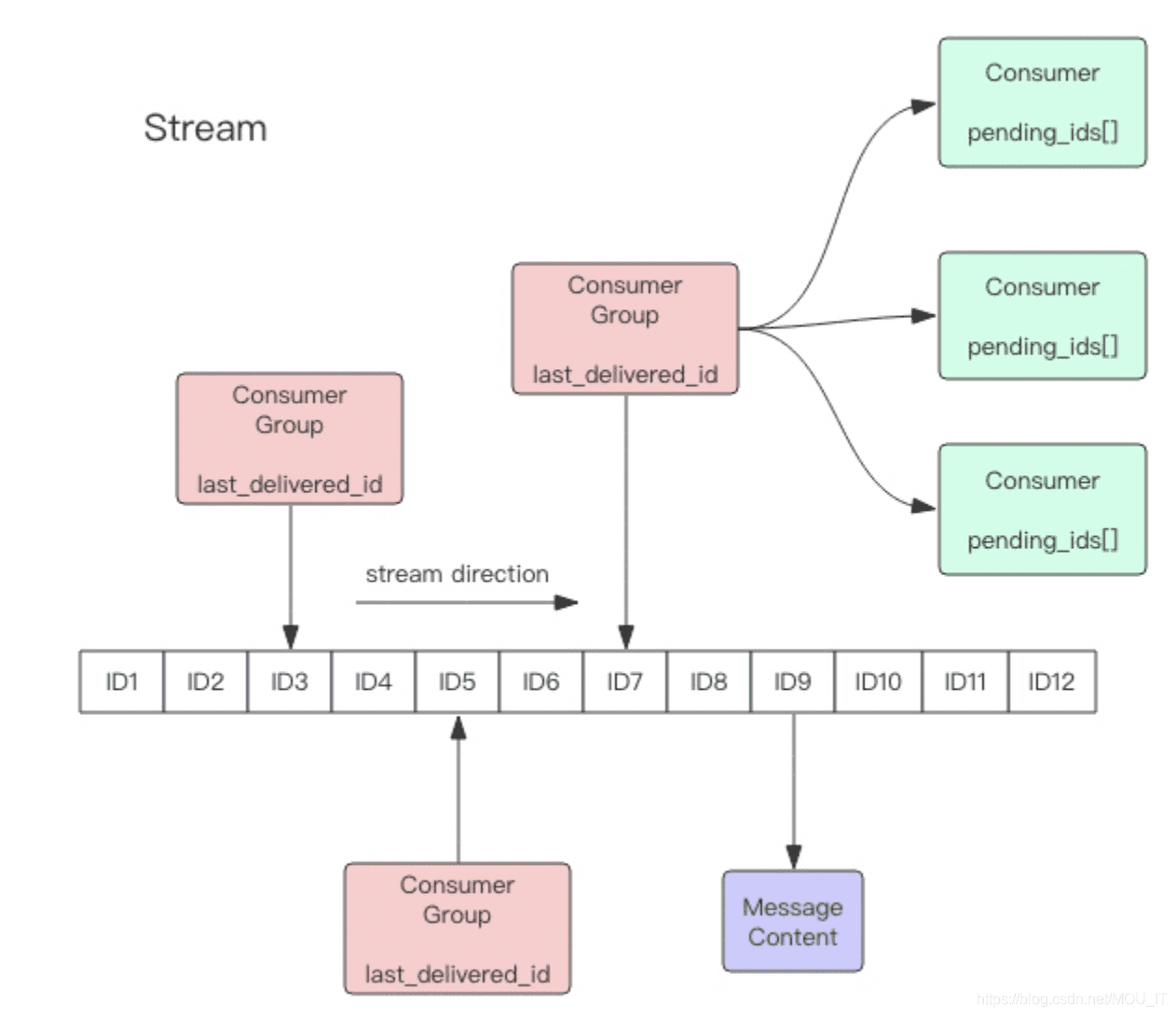
Stream主要由消息、生产者、消费者、消费组4部分组成. 这里消费组可能让人有些困惑, 其实就是消费组里面有多个消费者, 他们互相竞争, 当一个消费了某条消息, 消息会被放入待确认队列, 消息队列的迭代器就会前移, 下一个同组消费者不管是谁, 都不会再次消费这个消息, 而是下一个消息。这种概念和kafka很雷同,在某些特定场景可以使用redis的stream代替kafka等消息队列,减少系统复杂性,增强系统的稳定性。
(1)创建消息队列
/* * xadd用来创建, 每个stream有一个唯一key, *意味着让系统给你返回id, id是由unix时间和从0开始下标 * 组成, 也就是这一毫秒的第几个条目. 你可以自己设定, 但是要确保严格单调递增. 后面就是键值对, 也就 * 是消息本身. */ xadd mystream * str1 hello str2 world
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
(2)删除消息队列
del mystream
(3)删除消息队列中某条消息
通过xdel可以删除消息, 但是注意, 其实没有删除, 只是设置了标志位.
xdel mystream streamID
(4)消费一条消息
xread count 1 streams mystream streanID
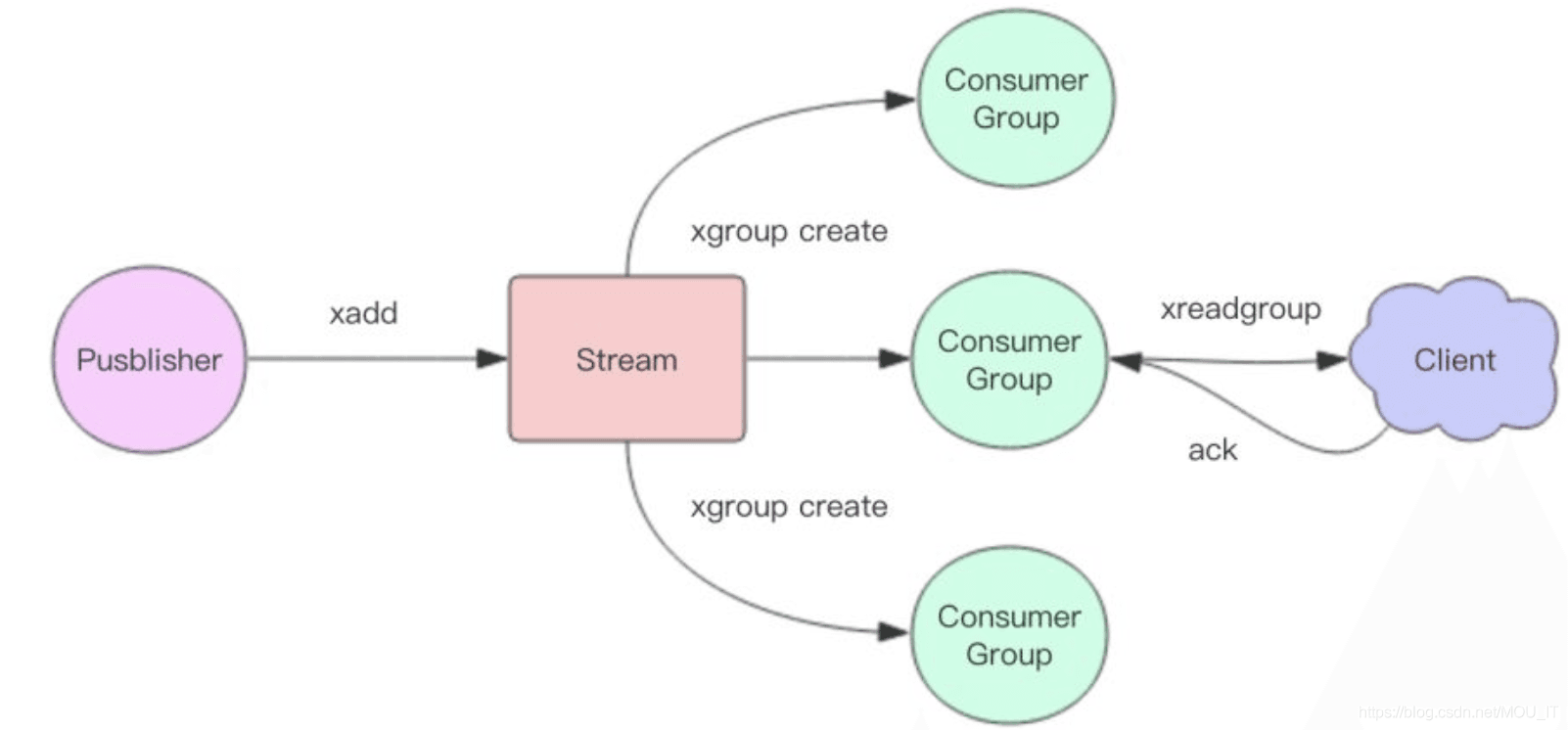
(5)消费者组消费
创建消费者组:
xgroup create mystream myg 0 # 这里最后是id, 0就代表从最前面开始获取消息, 可以写成$, 意味着获取新消息.
消费者组内第一个消费者读取消息:
xreadgroup group myg alice count 2 streams mystream # 消费者alice读取2条消息
消费者组内第二个消费者读取消息:
xreadgroup group myg bob count 1 streams mystream # 消费者bob读取1条消息
接下来我们介绍Stream的数据结构,在介绍Stream的数据结构之前,我们先来看看字典数(Trie Tree)和基数树(Radix Tree),Redis的消息队列Stream主要是基于基数树来实现的。
2. 字典树(Trie Tree)
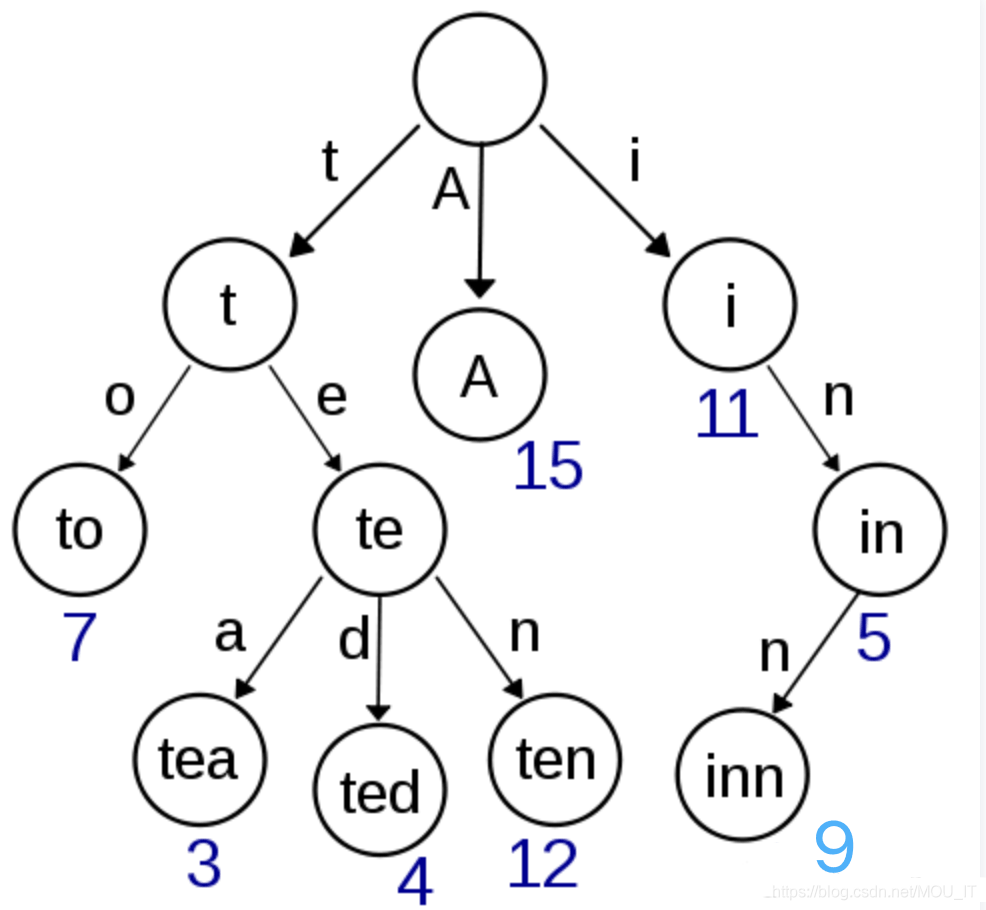
在计算机科学中,字典树(Trie Tree),又称前缀树,是一种有序树,用于保存关联数组,可以保存一些字符串->值的对应关系。基本上,它哈希表功能相同,都是 key-value 映射,只不过其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。trie tree中的键通常是字符串,但也可以是其它的结构。trie的算法可以很容易地修改为处理其它结构的有序序列,比如一串数字或者形状的排列。比如,bitwise trie中的键是一串位元,可以用于表示整数或者内存地址。
它的原理是将每个key拆分成每个单位长度字符,然后对应到每个分支上,分支所在的节点对应为从根节点到当前节点的拼接出的key的值。Trie树有3个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符;
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;
- 每个节点的所有子节点包含的字符都不相同;
字典树的结构图如下所示:
Trie 的强大之处就在于它的时间复杂度。它的插入和查询时间复杂度都为 O(k) ,其中 k 为 key 的长度,与 Trie 中保存了多少个元素无关。Hash 表号称是 O(1) 的,但在计算 hash 的时候就肯定会是 O(k) ,而且还有碰撞之类的问题;Trie 的缺点是空间消耗很高。
字典树的应用场景包括:
(1)字符串检索:事先将已知的一些字符串(字典)的有关信息保存到trie树里,查找另外一些未知字符串是否出现过或者出现频率。
(2)词频统计:一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
(3)排序:Trie树是一棵多叉树,只要先序遍历整棵树,输出相应的字符串便是按字典序排序的结果。
(4)字符串最长公共前缀:Trie树利用多个字符串的公共前缀来节省存储空间,当我们把大量字符串存储到一棵trie树上时,我们可以快速得到某些字符串的公共前缀。
(5)字符串搜索的前缀匹配:trie树常用于搜索提示。如当输入一个网址,可以自动搜索出可能的选择。当没有完全匹配的搜索结果,可以返回前缀最相似的可能。
3. 基数树(Radix Tree)
3.1 Radix Tree
Trie树其实依然比较浪费空间,有人曾经反馈他们在实际的项目发现,随着key的数量的增加,发现Trie树会占用大量的内存和空间。现在我们就演绎下Trie树是如何浪费内存和空间的。比如下面的一组数据:
{
"deck": someValue,
"did": someValue,
"doe": someValue,
"dog": someValue,
"doge": someValue,
"dogs": someValue
}用Trie树的画法把上面的key value画出来如下:
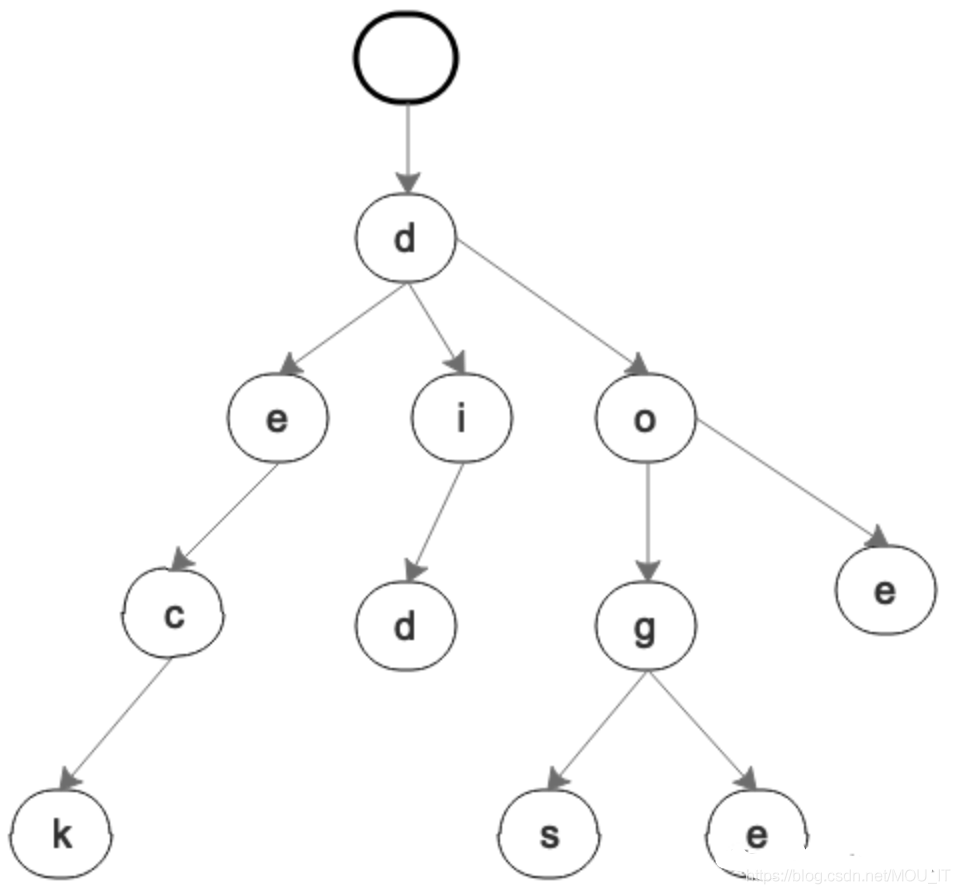
也许你已经发现了一些问题。比如"deck"这一个分支,有没有必要一直往下来拆分吗?还是"did",有必要d,然后i,然后d吗?像这样的不可分叉的单支分支,其实完全可以合并,也就是压缩。
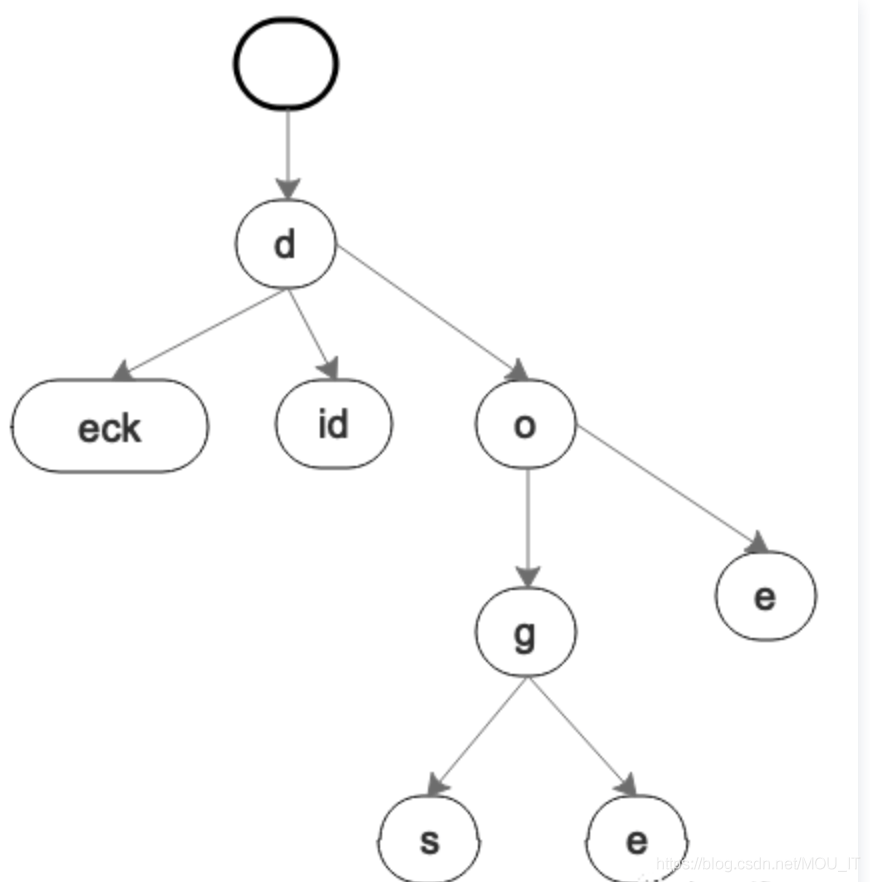
这样看起来是不是要更节省一点空间呢?这只是6个单词的样子,数据越多,空间节省的效果越明显。而且这样压缩后,不可分叉的分支高度也变矮了。我们叫这样的Trie树为压缩Trie树(Compressed Trie Tree)。压缩Trie树也就是Radix树,只不过他有多个名字,有人叫压缩Trie树,有人叫Radix树,它和字典树的不同之处在于,所有只有一个子节点的中间节点都被删除。Redis中就用到了Radix树。
3.2 计算机对Radix Tree的处理
因为计算机可不会像人类一样可以通过英文像上面的图一样来构建树,计算机只认识0和1。所以为了真正的了解Radix树,我们需要知道机器是怎么读取Radix树的。计算机对于Radix树的处理是以bit(或二进制数字)来读取的。一次被对比r个bit,2的r次方是radix树的基数。这也是基数树的这个名字的由来。现在我们把上面的三个单词变成二进制的样子,然后一位一位的看:
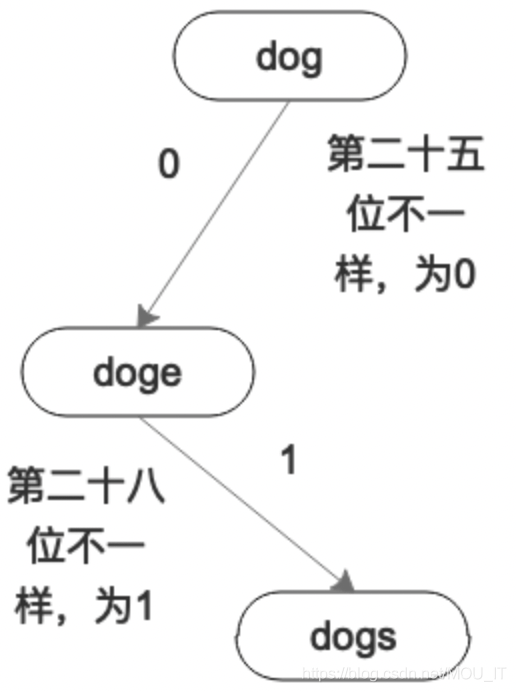
dog: 01100100 01101111 01100111 doge: 01100100 01101111 01100111 01100101 dogs: 01100100 01101111 01100111 01110011
按照字符串的比对,你会发现dog是dogs和doge的子串。但我们现在比对二进制,一位一位的比对,你会发现dog和doge是在第二十五位的时候不一样的。dogs和doge是在第二十八位不一样的。按照位的比对的结果,你会发现doge居然是dogs二进制子串。这就是计算机的方式。
4. 基数树(Radix Tree)的实现
4.1 raxNode结构定义
raxNode是radix tree的核心数据结构,其结构体如下所示:
typedef struct raxNode {
uint32_t iskey:1;
uint32_t isnull:1;
uint32_t iscompr:1;
uint32_t size:29;
unsigned char data[];
} raxNode;
typedef struct rax {
raxNode *head;
uint64_t numele;
uint64_t numnodes;
} rax;- iskey:表示这个节点是否包含key
- 0:没有key
- 1:表示从头部到其父节点的路径完整的存储了key,查找的时候按子节点iskey=1来判断key是否存在
- isnull:是否有存储value值,比如存储元数据就只有key,没有value值。value值也是存储在data中
- iscompr:是否有前缀压缩,决定了data存储的数据结构
- size:该节点存储的字符个数
- data:存储子节点的信息
- iscompr=0:非压缩模式下,数据格式是:[header strlen=0][abc][a-ptr][b-ptr][c-ptr](value-ptr?),有size个字符,紧跟着是size个指针,指向每个字符对应的下一个节点。size个字符之间互相没有路径联系。
- iscompr=1:压缩模式下,数据格式是:[header strlen=3][xyz][z-ptr](value-ptr?),只有一个指针,指向下一个节点。size个字符是压缩字符片段
4.2 Rax Insert
以下用几个示例来详解rax tree插入的流程。假设 j 是遍历已有节点的游标,i 是遍历新增节点的游标。
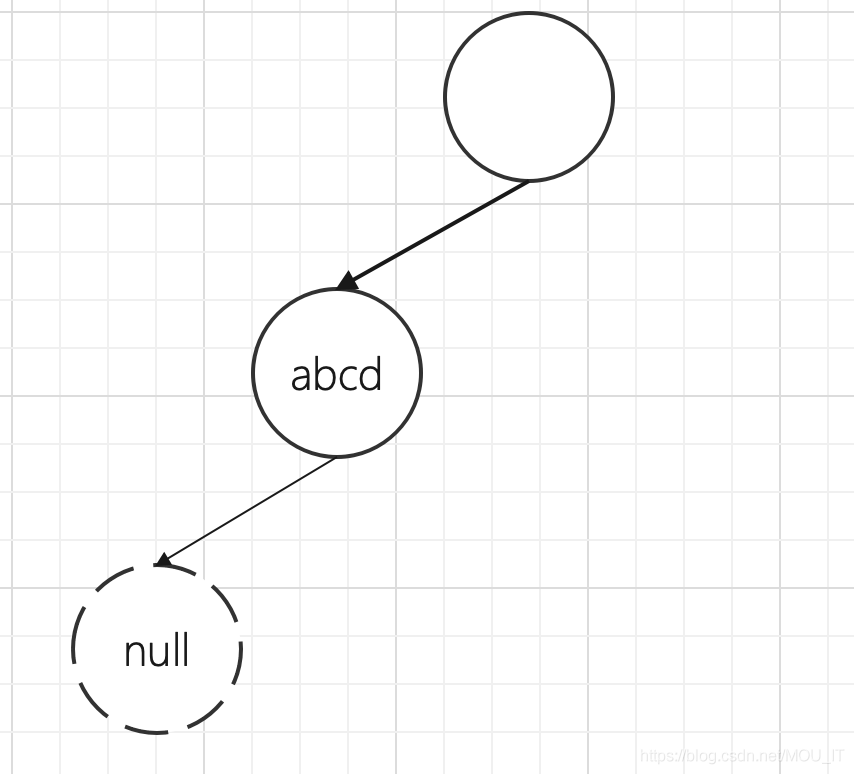
(1)场景一:只插入abcd

该场景下iscompr = 1,表示使用了压缩前缀, 因此data域只有一个z-ptr指针,z-ptr指向的叶子节点iskey = 1。节点图为:
(2)场景二:在abcd之后插入abcdef
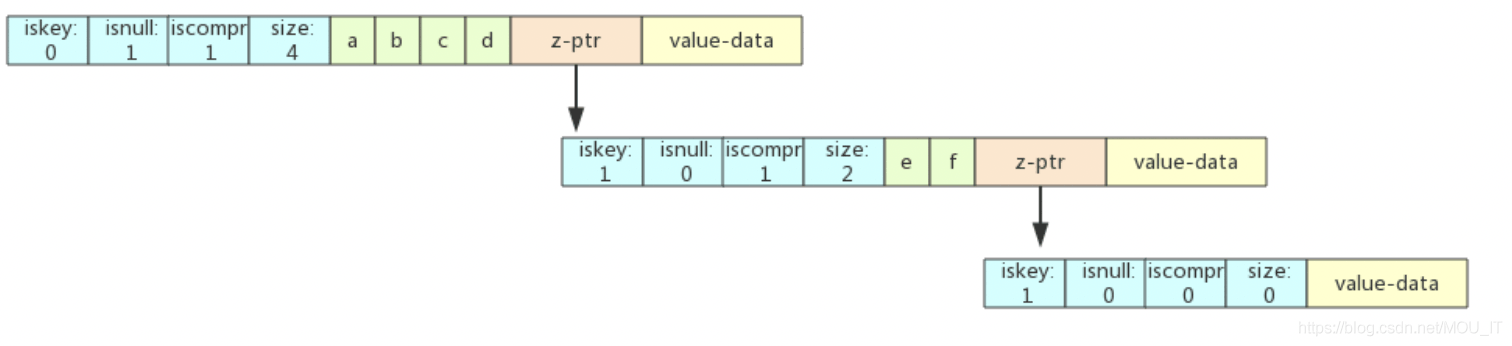
从abcd父节点的每个压缩前缀字符比较,遍历完所有abcd节点后指向了其空子节点,j = 0, i < len(abcded)。查找到abcd的空子节点,直接将ef赋值到子节点上,成为abcd的子节点。ef节点被标记为iskey=1,用来标识abcd这个key。ef节点下再创建一个空子节点,iskey=1来表示abcdef这个key。节点图为:
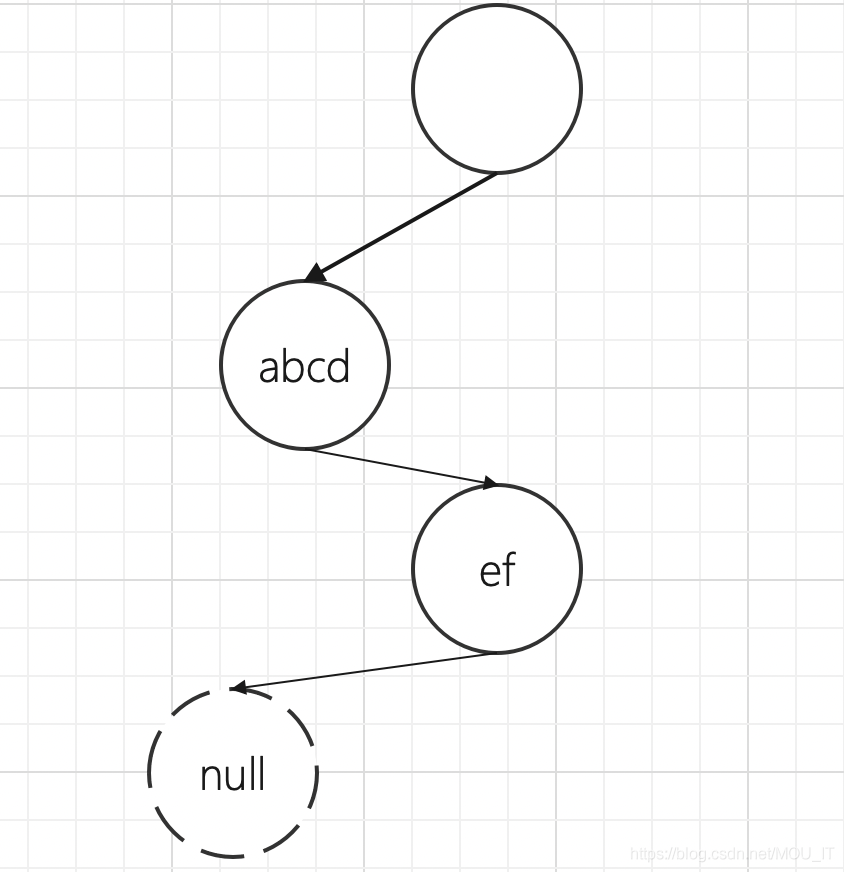
(3)场景三:在abcd之后插入ab

ab在abcd能找到前两位的前缀,也就是i=len(ab),j < len(abcd)。将abcd分割成ab和cd两个子节点,cd也是一个压缩前缀节点,cd同时被标记为iskey=1,来表示ab这个key。cd下挂着一个空子节点,来标记abcd这个key。节点图为:
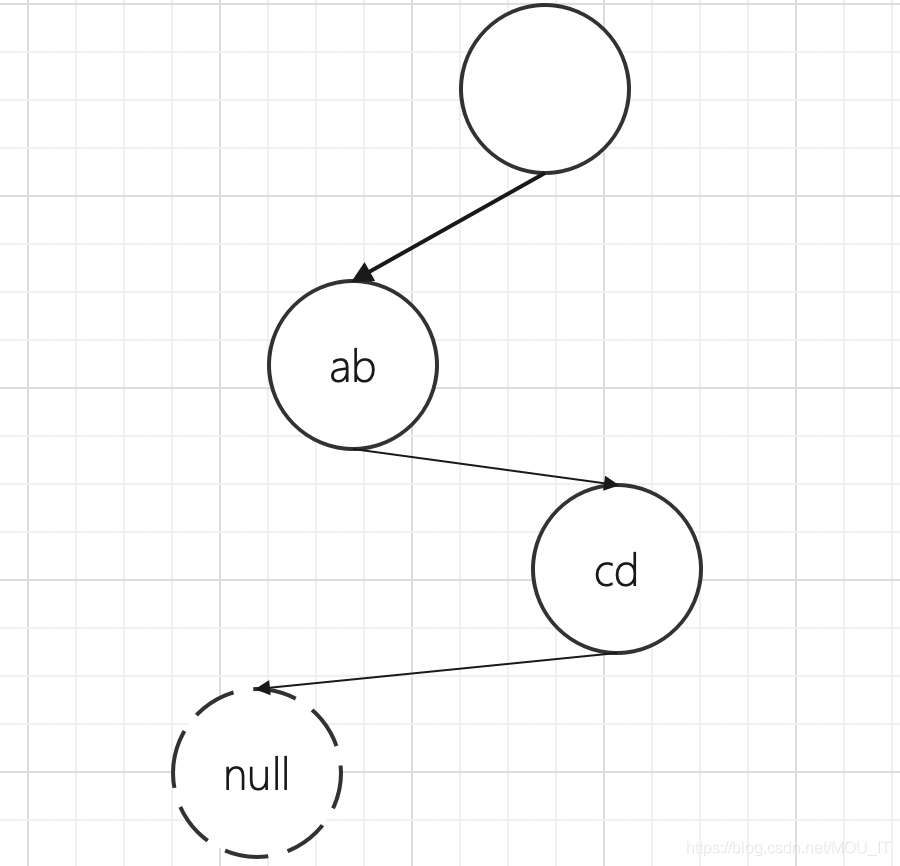
(4)场景四:在abcd之后插入abABC

abcABC在abcd中只找到了ab这个前缀,即i < len(abcABC),j < len(abcd)。这个步骤有点复杂,分解一下:
- step 1:将abcd从ab之后拆分,拆分成ab、c、d 三个节点。
- step 2:c节点是一个非压缩的节点,c挂在ab子节点上。
- step 3:d节点只有一个字符,所以也是一个非压缩节点,挂在c子节点上。
- step 4:将ABC 拆分成了A和BC, A挂在ab子节点上,和c节点属于同一个节点,这样A就和c同属于父节点ab。
- step 5:将BC作为一个压缩前缀的节点,挂在A子节点下。
- step 6:d节点和BC节点都挂一个空子节点分别标识abcd和abcABC这两个key。
节点图为:
(5)场景五:在abcd之后插入Aabc
abcd和Aabc没有前缀匹配,i = 0,j = 0。
- 将abcd拆分成a、bcd两个节点,a节点是一个非压缩前缀节点。
- 将Aabc拆分成A、abc两个节点,A节点也是一个非压缩前缀节点。
- 将A节点挂在和a相同的父节点上。
- 同上,在bcd和abc这两个节点下挂空子节点来分别表示两个key。
节点图为:

4.3 Rax Remove
(1)删除
删除一个key的流程比较简单,找到iskey的节点后,向上遍历父节点删除非iskey的节点。如果是非压缩的父节点并且size > 1,表示还有其他非相关的路径存在,则需要按删除子节点的模式去处理这个父节点,主要是做memove和realloc。
(2)合并
删除一个key之后需要尝试做一些合并,以收敛树的高度。合并的条件是:
- iskey = 1的节点不能合并
- 子节点只有一个字符
- 父节点只有一个子节点(如果父节点是压缩前缀的节点,那么只有一个子节点,满足条件。如果父节点是非压缩前缀的节点,那么只能有一个字符路径才能满足条件)
5. 消息队列Stream的实现
5.1 Stream的数据结构
/* 消息ID */
typedef struct streamID {
uint64_t ms; /* Unix 时间(ms) */
uint64_t seq; /* 序列号,该毫秒下产生的第几个消息队列 */
} streamID;
/* 消息队列 */
typedef struct stream {
rax *rax; /* 该消息队列指向的基数树,保存键值对 */
uint64_t length; /* 此消息队列里面的元素个数 */
streamID last_id; /* 上一次访问的消息ID,如果没有元素则为0 */
rax *cgroups; /* 消费者组字典: name -> streamCG */
} stream;
/* 消费者组 */
typedef struct streamCG {
streamID last_id; /* 上一次分发还未确认的消息 */
rax *pel; /* 这个消费者组中未确认的消息列表 */
rax *consumers; /* 该消息者组中的所有消费者 */
} streamCG;
/* 消费者组中的一个消费者 */
typedef struct streamConsumer {
mstime_t seen_time; /* 该消费者上次激活的时间 */
sds name; /* 消费者的名字 */
rax *pel; /* 该消费者待处理的未确认的消息列表 */
} streamConsumer;(1)消息ID(streamID)
消息ID的形式是timestampInMillis-sequence,例如1527846880572-5,它表示当前的消息在毫米时间戳1527846880572时产生,并且是该毫秒内产生的第5条消息。消息ID可以由服务器自动生成,也可以由客户端自己指定,但是形式必须是整数-整数,而且必须是后面加入的消息的ID要大于前面的消息ID。
(2)消息内容
一条消息内容就是一系列的key/value组成,使用基数树进行保存。
(3)last_id
游标,每个消费组会有个游标 last_id,任意一个消费者读取了消息都会使游标 last_id 往前移动。
(4)pel
消费者(Consumer)的状态变量,作用是维护消费者的未确认的 id。 pel记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)。
5.2 Stream的API函数
stream *streamNew(void); // 新建一个消息队列stream
void freeStream(stream *s); // 释放一个消息队列stream
unsigned long streamLength(const robj *subject); // 返回消息队列的消息个数
/* 把stream中从start到end的消息发送给客户端c,如果conut不为0,则发送conut个消息,返回发出的消息个数 */
size_t streamReplyWithRange(client *c, stream *s, streamID *start, streamID *end, size_t count, int rev,
streamCG *group, streamConsumer *consumer, int flags, streamPropInfo *spi);
/* 根据迭代器获取消息的key和value */
void streamIteratorGetField(streamIterator *si, unsigned char **fieldptr, unsigned char **valueptr,
int64_t *fieldlen, int64_t *valuelen);
int streamIteratorGetID(streamIterator *si, streamID *id, int64_t *numfields);// 根据迭代器获取消息ID
streamCG *streamCreateCG(stream *s, char *name, size_t namelen, streamID *id); // 创建一个消费者组
streamCG *streamLookupCG(stream *s, sds groupname); // 根据消费者组名查询消费者组
/* 根据消费者名在消费者组中进行查询 */
streamConsumer *streamLookupConsumer(streamCG *cg, sds name, int flags, int *created);
void streamIteratorRemoveEntry(streamIterator *si, streamID *current); // 删除消息队列中的一个消息
/* 添加一条消息到消息队列中 */
int streamAppendItem(stream *s, robj **argv, int64_t numfields, streamID *added_id, streamID *use_id);
/* 从消息队列中删除一条消息 */
int streamDeleteItem(stream *s, streamID *id);
/* 根据长度删除消息队列中消息的条数 */
int64_t streamTrimByLength(stream *s, long long maxlen, int approx);
/* 根据最小的消息ID删除消息队列中消息的条数 */
int64_t streamTrimByID(stream *s, streamID minid, int approx);参考:1)https://cloud.tencent.com/developer/article/1597128
2)http://mysql.taobao.org/monthly/2019/04/03/
到此这篇关于一文弄懂Redis Stream消息队列的文章就介绍到这了,更多相关Redis Stream消息队列内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!