缓存穿透
缓存穿透是指在使用缓存系统时,频繁查询一个不存在于缓存中的数据,导致这个查询每次都要通过缓存层去查询数据源,无法从缓存中获得结果。
这种情况下,大量的请求会直接穿透缓存层,直接访问数据源,从而增加了系统的负载,降低了系统的性能。
通常情况下,当一个查询发现所需数据不存在于缓存中时,它会从数据源中获取数据,并将数据存储到缓存中,以便后续查询可以直接从缓存中获取数据。
然而,当不断查询不存在于缓存中的数据时,缓存层会无法起到预期的性能提升作用,因为每次查询都必须去访问数据源。
缓存穿透可能由恶意攻击、系统设计问题或数据变更等原因引起。
为了防止缓存穿透,可以在缓存层添加缓存不存在的数据的标记,当查询到缓存中有这个标记时,可以避免不必要的访问数据源,从而提高系统的性能。
另外,使用布隆过滤器等技术可以对查询进行预处理,过滤掉一些明显不存在的查询,进一步减轻系统压力。
缓存击穿
缓存击穿是指当一个热点数据在缓存中过期或被删除时,同时有大量的并发请求访问该数据,导致这些请求都无法从缓存中获取到数据,而需要直接从数据源中获取。
这种情况下,大量的请求会直接访问数据源,给数据源带来很大的压力,可能导致数据源崩溃或性能下降。
在正常情况下,缓存会存储常用的数据,以提高系统的性能和响应速度。
当一个查询发现所需的数据不存在于缓存中时,它会从数据源中获取数据,并将数据存储到缓存中,以便后续查询可以直接从缓存中获取数据。
然而,当一个热点数据在某一时刻过期或被删除时,大量的请求会同时涌入,这些请求无法从缓存中获取数据,导致缓存层无法起到预期的性能提升作用。
为了防止缓存击穿,可以采取以下策略:
- 设置合适的缓存过期时间:确保缓存数据在合适的时间内过期,避免在同一时间大量数据过期导致缓存击穿。
- 使用互斥锁或分布式锁:当缓存过期时,使用锁机制保证只有一个请求可以从数据源中获取数据,其他请求等待获取到数据后再从缓存中获取。
- 预加载热点数据:在系统启动或数据源更新时,提前加载热点数据到缓存中,避免在热点数据过期时出现缓存击穿。
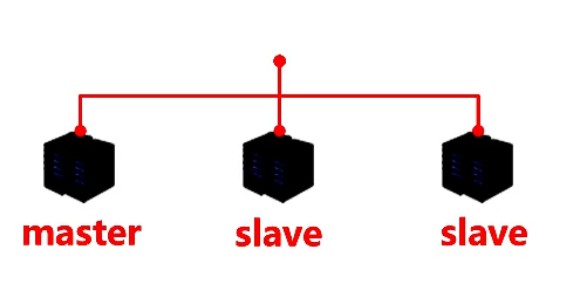
- 使用高可用的缓存方案:使用多级缓存或分布式缓存系统,确保缓存的高可用性,避免单点故障导致缓存击穿。
缓存雪崩
缓存雪崩指的是当缓存系统中的大量数据同时失效或过期,导致大量的请求直接访问数据源,给数据源和系统带来巨大的压力,从而导致系统性能下降甚至崩溃。
正常情况下,缓存系统会设置合理的过期时间,以使被缓存的数据在一段时间内有效。
当一个查询发现所需数据不存在于缓存中时,它会从数据源中获取数据,并将数据存储到缓存中,以便后续查询可以直接从缓存中获取数据。
然而,当大量的缓存数据在同一时间失效或过期时,如果没有有效的缓存更新机制,系统中的请求就会直接访问数据源。
由于大量请求同时涌入数据源,可能会导致数据源的性能下降、响应时间延长甚至崩溃。
这种情况下,系统会经历一段时间的高负载压力,如同雪崩一般,被称为缓存雪崩。
为了避免缓存雪崩,可以采取以下策略:
- 合理设置缓存的过期时间:缓存过期时间应随机分散,避免大量缓存在同一时间失效。
- 使用缓存的自动过期机制:例如,使用Redis的过期机制,设置缓存的过期时间,并自动更新缓存,避免过期数据的同时失效。
- 设置热点数据的永久缓存或手动刷新机制:重要的热点数据可以设置为永久缓存,或者手动进行缓存更新,避免热点数据过期导致缓存雪崩。
- 引入多级缓存:使用多级缓存,例如将热点数据存储在内存缓存中,冷数据存储在持久化缓存或数据库中,以降低缓存雪崩的风险。
- 监控和预警机制:监控缓存系统的状态和性能,设置预警机制,在发现异常情况时及时采取措施,避免缓存雪崩的发生。
到此这篇关于浅谈一下Redis缓存穿透、击穿和雪崩的文章就介绍到这了,更多相关缓存穿透、击穿和雪崩内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!