请问一下PostgreSQL什么意思 请详述 谢谢
substring(
substring(information FROM
': &' || substring(information from E':step_1: \\*([0-9]+)') ||
'.*:step_1:'
) from E'loan_purpose: ([^\n]+)'
)
最好能举个例子 谢谢各位大神
最新回答

弥枳
2021-07-03 08:29:56
首先知道substring函数在PostgreSQL中的作用。在这段SQ语句中,substring是使用的substring(txt from reg)的形式,其中, txt是要进行正则匹配的源字符串,reg是匹配的正则表达式。如此,我们大概可以知道:这段代码的then其实就是用information进行一些正则表达式的匹配,然后获取匹配后的那段字符串。
这段代码中一共有3个substring函数调用,而执行的顺序则与它们出现的顺序相反,首先执行的是:
substring(information from E':step_1: \\*([0 -9]+)' )
它获得匹配step_1: *后面所跟的数字;假设information为:step_1: *1234a, 那么获得的就是1234;
接下来为第二substring, 它是用information来匹配上面获得的数字嵌入":&"和".*:step_1:"的那段内容;
而最后一个substring,则是匹配第二个获得的字串,其中前为“loan_purpose: ”接下来为非换行符号的那部分字串(即获得以“loan_purpose: ”开始的所有非换行字符,遇到换行符就终止,不包括"loan_purpose: ")。
一个例子:
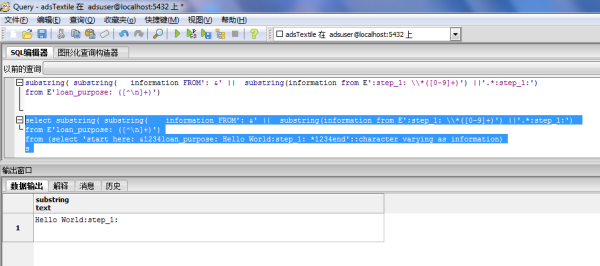
select substring( substring( information FROM': &' || substring(information from E':step_1:
\\*([0-9]+)'
) ||'.*:step_1:')
from E'loan_purpose: ([^\n]+)')
from (select 'start here: &1234loan_purpose: Hello World:step_1: *1234end'::character varying as information)
s
运行结果如图,
追问
您好
您回答的我还有些不明白
如果按照您的例子来说 在第一个substring 假设information为:step_1: *1234a, 那么获得的就是1234;那么现在 第二个substring就应该是 information for :&1234.*:step_1:吗?
||'.*:step_1:'里的.* 是不是代表从&1234到:step_1:之间的所有非/n字符?
追答
关于PostgreSQL中正则表达式有关的资料可以参考其文档(如果你使用的是Windows的安装版的话,在开始菜单中就有;也可以直接在PostgreSQL官方网站上浏览). 具体在"Functions and Operators"章下的"Pattern Matching"中有详细叙述。
你叙述的基本正确。这里再说明几个关键的地方:
1) 正则表达式中有圆括号时,得到匹配的结果将只限于圆括号内的内容;
2) *(星号)代表匹配前面的字符任意次数,如果前有转义字符\\则转义为*字符本身;
3) .(逗点)匹配的是任意一个字符,.*则是匹配任意长度的任意字符;
第一个执行的substring匹配的正则表达式为E':step_1: \\*([0 -9]+)',其中有括号,那么匹配得到的将只是匹配括号中的内容,另外*前有2个转义字符\\,这里\\*就代表匹配的是正常的字符*,所以这里获得的匹配内容将是: 前置为step_1: *开头的所有数字,但是不包括开头额step_1 *;
就举例而说,第二个执行的substring,正则表达式则是:&1234.*:step_1:,则很好理解匹配就是&1234后跟任意长度任意字符再接着为.step_1的字串;
最后一个执行的substring因为有圆括号,则匹配得到的是"loan_purpose: "后续的任意长度的非换行字符组成的字串(就是“loan_purpose: ”开始但不包括,后续的字符一直到换行符之间的所有字符组成的字串)。
最简便的理解方式就是将3个substring一个个按执行顺序拆解下来执行,看看每步都得到什么结果。
干净好听的昵称
2020-11-27 22:06:20
数据来源于百度百科,你可以在百度百科里面看想尽资料
热门标签
