如何用Python爬取出HTML指定标签内的文本?
最新回答

蔚蓝的心
2024-04-23 04:07:21
你好!
可以通过lxml来获取指定标签的内容。
#安装lxml
pip install lxml
import requests
from lxml import html
def getHTMLText(url):
....
etree = html.etree
root = etree.HTML(getHTMLText(url))
#这里得到一个表格内tr的集合
trArr = root.xpath("//div[@class='news-text']/table/tbody/tr");
#循环显示tr里面的内容
for tr in trArr:
rank = tr.xpath("./td[1]/text()")[0]
name = tr.xpath("./td[2]/div/text()")[0]
prov = tr.xpath("./td[3]/text()")[0]
strLen = 22-len(name.encode('GBK'))+len(name)
print('排名:{:<3}, 学校名称:{:<{}}\t, 省份:{}'.format(rank,name,strLen,prov))
希望对你有帮助!
追问
这个可以用!谢谢啦!
季沫怡
2024-04-23 08:02:25
这种情况用xpath啊,什么re和bs4都弱爆了。
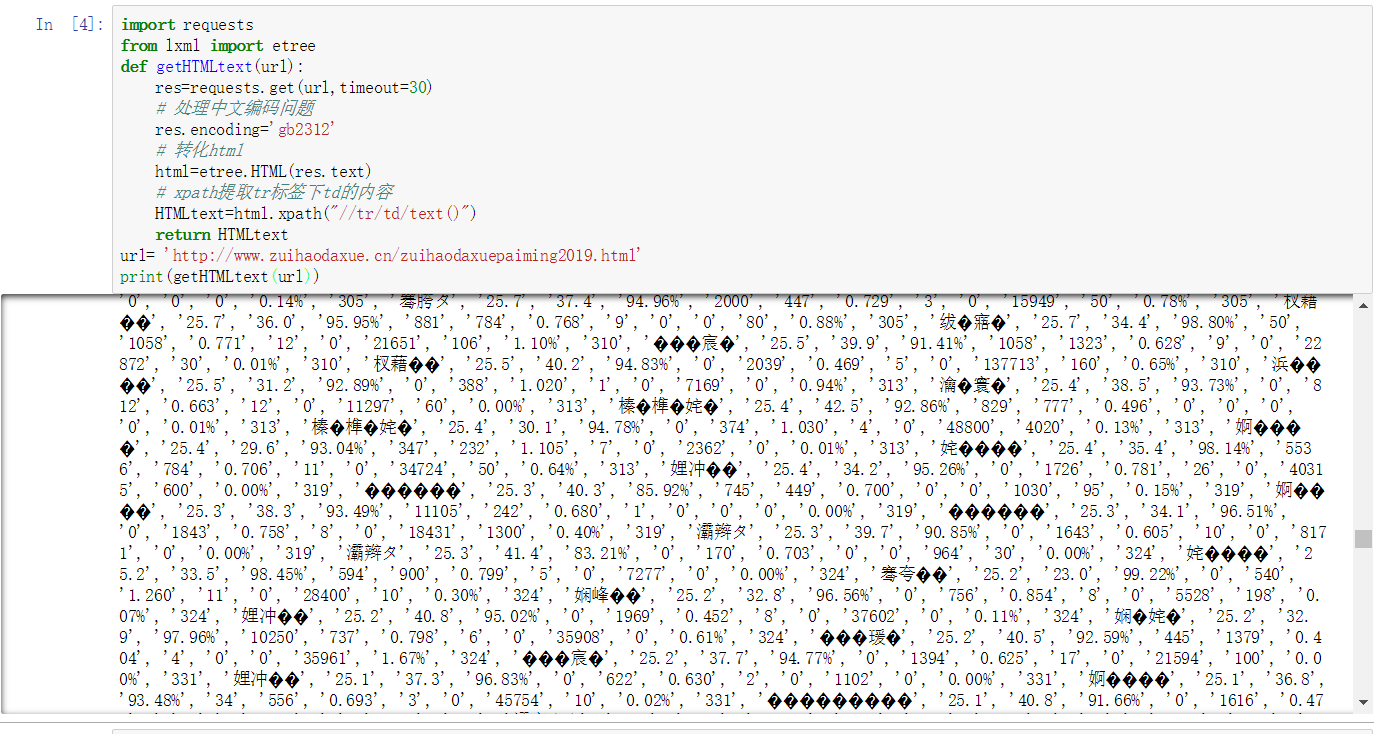
import requests
from lxml import etree
def getHTMLtext(url):
res=requests.get(url,timeout=30)
# 处理中文编码问题
res.encoding='gb2312'
# 转化html
html=etree.HTML(res.text)
# xpath提取tr标签下td的内容
HTMLtext=html.xpath("//tr/td/text()")
return HTMLtext
追问
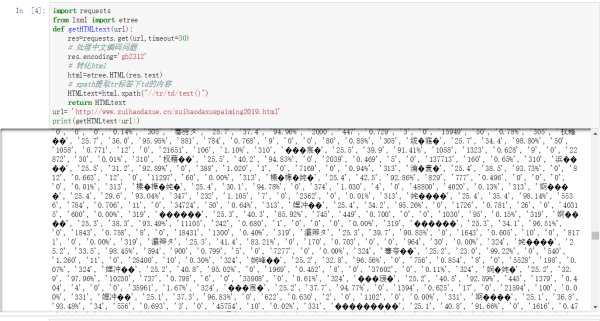
会乱码哦!
追答
这是中文编码问题,跟提取没有关系,通过res.apparent_encoding查看真实编码,然后把gb2312改成真实编码
容嬷嬷的春天
2024-04-23 12:03:02
当然还可以查下类似xml解析的方法将HTML转化为数组,然后取值
爱在千年梦
2024-04-23 19:00:30
追问
能给代码吗?我看到网上很多都说用正则表达式,但是那些代码复制来都报错。
一只哀伤的猫
2024-04-23 17:31:09
想要提取全部标签<h4></h4>内的文本,可使用如下Python代码:
import re
with open("html.html",'rU') as strf:
....str = strf.read()
res = r'(?<=<h4>).*?(?=</h4>)'
li = re.findall(res,str)
with open("new.txt","w") as wstr:
....for s in li:
........wstr.write(s)
........wstr.write(" ")
........print(s,' ')
正则表达式r'(?<=<h4>).*?(?=</h4>)中括号部分属于向后向前查找,相当于字符串作为边界进行查找。
运行后会将标签<h4></h4>内的文本提取到文件new.txt
热门标签
