什么是内存管理机制
python中创建的对象的时候,首先会去申请内存地址,然后对对象进行初始化,所有对象都会维护在一
个叫做refchain的双向循环链表中,每个数据都保存如下信息:
1. 链表中数据前后数据的指针
2. 数据的类型
3. 数据值
4. 数据的引用计数
5. 数据的长度(list,dict..)
一、引用计数机制
引用计数增加:
1.1 对象被创建
1.2 对象被别的变量引用(另外起了个名字)
1.3 对象被作为元素,放在容器中(比如被当作元素放在列表中)
1.4 对象被当成参数传递到函数中
import sys a = [11,22] # 对象被创建 b = a # 对象被别的变量引用 c = [111,222,333,a] # 对象被作为元素,放在容器中 # 获取对象的引用计数 print(sys.getrefcount(a)) # 对象被当成参数传递到函数中
最后的执行结果是,a 这个变量被引用了4次

引用计数减少:
- 对象的别名被显式的销毁
- 对象的一个别名被赋值给其他对象 (例:比如原来的a=10,被改成a=100,此时10的引用计数就减少了)
- 对象从容器中被移除,或者容器被销毁(例:对象从列表中被移除,或者列表被销毁)
- 一个引用离开了它的作用域(调用函数的时候传进去的参数,在函数运行结束后,该参数的引用即被销毁)
import sys del b # 对象的别名被显式的销毁 b = 999 # 对象的一个别名被赋值给其他对象 del c # 列表被销毁(容器被销毁) c.pop() # 把列表数据最后一个删除掉(对象从容器中被移除)
二、数据池和缓存
数据池分为两种:小整数池 和 大整数池
小整数池(-5到256之间的数据)
运行机制:Python自动将 -5~256 的整数进行了缓存到一个小整数池中,当你将这些整数赋值给变量时,并不会重新
创建对象,而是使用已经创建好的缓存对象,当删除这些数据的引用时,也不会进行回收
超出-5到256的整数将不会在在缓存,会重新创建对象
例如:
对于超出-5到256的整数将不会在在缓存,Python会重新创建对象,返回id
# 场景1:数据为列表,不在-5~256 的范围 >>> a = [11] >>> b = [11] >>> id(a),id(b) (1693226918600, 1693231858248) ========》 id 不一样 # 场景二: 数据为整数,在-5~256 的范围 >>> aa = 11 >>> bb = 11 >>> id(aa),id(bb) (140720470385616, 140720470385616) id 一样 # 场景三: 数据不在-5~256的范围 >>> bb = -7 >>> aa = -7 >>> id(aa),id(bb) (1843518717904, 1843518717776) id 不一样 # 场景四: 数据不在-5~256的范围 >>> a = 257 >>> b = 257 >>> id(a),id(b) (2092420910928, 2092420911056) id 不一样
大整数池(字符串驻留池 / intern机制)
优点:在创建新的字符串对象时,会先在缓存池里面找是否有已经存在的值相同的对象(标识符,即只包含数字、字母、下划线的字符串),如果有,则直接拿过来用(引用),避免频繁的创建和销毁内存,提升效率
例如:
对于不在标识符内的数据将不会在在缓存,Python会重新创建对象,返回id
# 场景1: >>> a = '123adsf_' >>> b = '123adsf_' >>> id(a),id(b) (61173296, 61173296) ========》 id 一样 # 场景二: >>> b1 = '123adsf_?' >>> b2 = '123adsf_?' >>> id(b1),id(b2) (61173376, 61173416) id 不一样
缓存机制
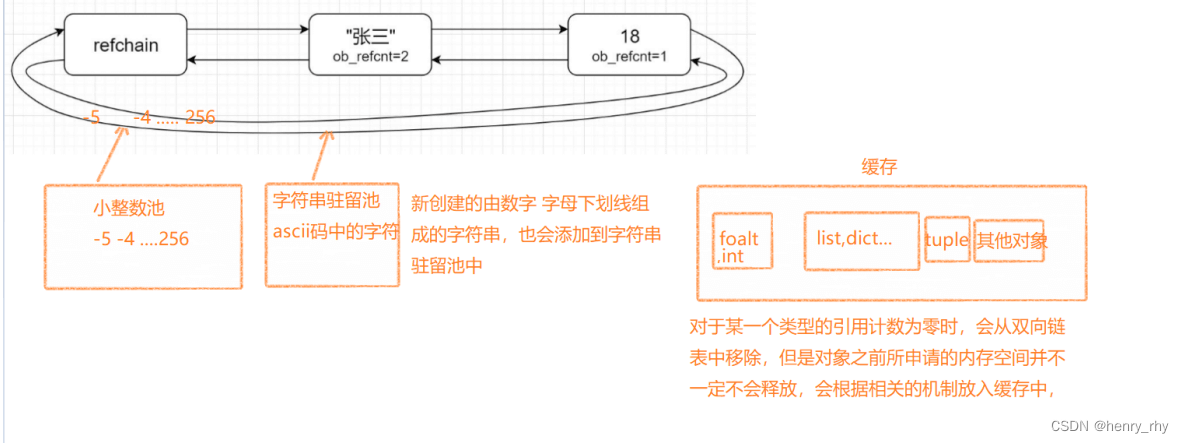
对于python中常用内置数据类型的缓存:
float:缓存100个对象
list: 80个对象
dict: 80个对象
set: 80个对象
元组:会根据元组数据的长度,分别缓存元组长度为0-20的对象
到此这篇关于Python超详细讲解内存管理机制的文章就介绍到这了,更多相关Python内存管理内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!