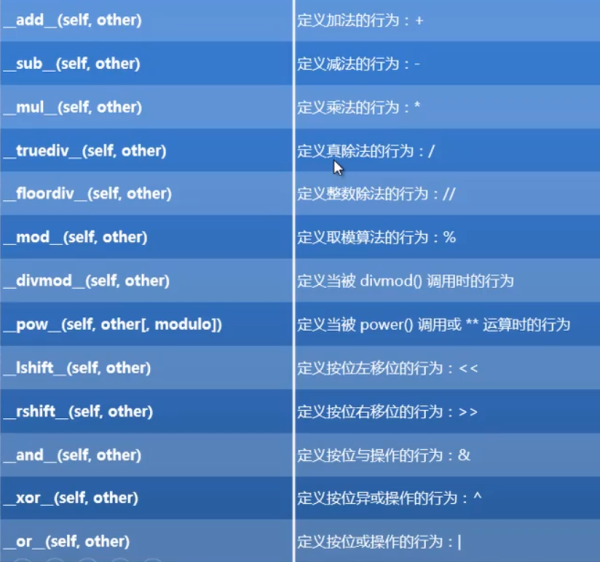
与此形成鲜明对比的是另一位巨星——葡萄牙队的c罗。上赛季他虽说有42个进球,但经统计,他的效率不到10%。在这个习惯统计学的社会,c罗的42球从深层分析充满了水分。此外,他的球场道德也属于低劣派,假摔贯穿全场,无处不在,江湖人送外号 "跳水运动员 ",桃色风波更是五花八门,而两者后果呢?看看吧:梅西凭借着08—09赛季带领巴萨取得西甲、国王杯、欧洲冠军联赛三冠王,取得433分,获得金球奖,而c罗只有他的一半不到!
查了很多很多的资料无果,果然知乎牛逼,完美解决。
爬取网站时,最终得到list内容,编码为unicode,想让其转换为汉字并输出。
需要提取的为下图中unicode部分:
保存为列表,然后使用for循环:
text为获取的网页。
pat = '"group": {"text": "(.*?)"'
text_list = re.compile(pat).findall(text)
for i in text_list:
print(i.encode('latin-1').decode('unicode_escape'))
输出结果为:
以上这篇python3 unicode列表转换为中文的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。