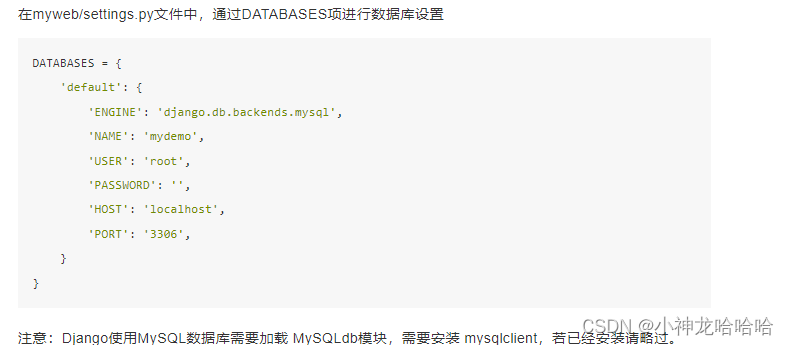
一、说明
本文主要讲述采集猫眼电影用户评论进行分析,相关爬虫采集程序可以爬取多个电影评论。
运行环境:Win10/Python3.5。
分析工具:jieba、wordcloud、pyecharts、matplotlib。
基本流程:下载内容 ---> 分析获取关键数据 ---> 保存本地文件 ---> 分析本地文件制作图表
注意:本文所有图文和源码仅供学习,请勿他用,转发请注明出处!
本文主要参考:https://mp.weixin.qq.com/s/mTxxkwRZPgBiKC3Sv-jo3g
二、开始采集
2.1、分析数据接口:
为了健全数据样本,数据直接从移动端接口进行采集,连接如下,其中橙色部分为猫眼电影ID,修改即可爬取其他电影。
链接地址:http://m.maoyan.com/mmdb/comments/movie/1208282.json?v=yes&offset=15&startTime=
接口返回的数据如下,主要采集(昵称、城市、评论、评分和时间),用户评论在 json['cmts'] 中:
2.2、爬虫程序核心内容(详细可以看后面源代码):
>启动脚本需要的参数如下(脚本名+猫眼电影ID+上映日期+数据保存的文件名):.\myMovieComment.py 1208282 2016-11-16 myCmts2.txt
>下载html内容:download(self, url),通过python的requests模块进行下载,将下载的数据转成json格式
def download(self, url):
"""下载html内容"""
print("正在下载URL: "+url)
# 下载html内容
response = requests.get(url, headers=self.headers)
# 转成json格式数据
if response.status_code == 200:
return response.json()
else:
# print(html.status_code)
print('下载数据为空!')
return ""
>然后就是对已下载的内容进行分析,就是取出我们需要的数据:
def parse(self, content):
"""分析数据"""
comments = []
try:
for item in content['cmts']:
comment = {
'nickName': item['nickName'], # 昵称
'cityName': item['cityName'], # 城市
'content': item['content'], # 评论内容
'score': item['score'], # 评分
'startTime': item['startTime'], # 时间
}
comments.append(comment)
except Exception as e:
print(e)
finally:
return comments
>将分析出来的数据,进行本地保存,方便后续的分析工作:
def save(self, data):
"""写入文件"""
print("保存数据,写入文件中...")
self.save_file.write(data)
> 爬虫的核心控制也即爬虫的程序启动入口,管理上面几个方法的有序执行:
def start(self):
"""启动控制方法"""
print("爬虫开始...\r\n")
start_time = self.start_time
end_time = self.end_time
num = 1
while start_time > end_time:
print("执行次数:", num)
# 1、下载html
content = self.download(self.target_url + str(start_time))
# 2、分析获取关键数据
comments = ''
if content != "":
comments = self.parse(content)
if len(comments) <= 0:
print("本次数据量为:0,退出爬取!\r\n")
break
# 3、写入文件
res = ''
for cmt in comments:
res += "%s###%s###%s###%s###%s\n" % (cmt['nickName'], cmt['cityName'], cmt['content'], cmt['score'], cmt['startTime'])
self.save(res)
print("本次数据量:%s\r\n" % len(comments))
# 获取最后一条数据的时间 ,然后减去一秒
start_time = datetime.strptime(comments[len(comments) - 1]['startTime'], "%Y-%m-%d %H:%M:%S") + timedelta(seconds=-1)
# start_time = datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
# 休眠3s
num += 1
time.sleep(3)
self.save_file.close()
print("爬虫结束...")
2.3 数据样本,最终爬取将近2万条数据,每条记录的每个数据使用 ### 进行分割:
三、图形化分析数据
3.1、制作观众城市分布热点图,(pyecharts-geo):
从图表可以轻松看出,用户主要分布地区,主要以沿海一些发达城市群为主:
def createCharts(self):
"""生成图表"""
# 读取数据,格式:[{"北京", 10}, {"上海",10}]
data = self.readCityNum()
# 1 热点图
geo1 = Geo("《无名之辈》观众位置分布热点图", "数据来源:猫眼,Fly采集", title_color="#FFF", title_pos="center", width="100%", height=600, background_color="#404A59")
attr1, value1 = geo1.cast(data)
geo1.add("", attr1, value1, type="heatmap", visual_range=[0, 1000], visual_text_color="#FFF", symbol_size=15, is_visualmap=True, is_piecewise=False, visual_split_number=10)
geo1.render("files/无名之辈-观众位置热点图.html")
# 2 位置图
geo2 = Geo("《无名之辈》观众位置分布", "数据来源:猫眼,Fly采集", title_color="#FFF", title_pos="center", width="100%", height=600,
background_color="#404A59")
attr2, value2 = geo1.cast(data)
geo2.add("", attr2, value2, visual_range=[0, 1000], visual_text_color="#FFF", symbol_size=15,
is_visualmap=True, is_piecewise=False, visual_split_number=10)
geo2.render("files/无名之辈-观众位置图.html")
# 3、top20 柱状图
data_top20 = data[:20]
bar = Bar("《无名之辈》观众来源排行 TOP20", "数据来源:猫眼,Fly采集", title_pos="center", width="100%", height=600)
attr, value = bar.cast(data_top20)
bar.add('', attr, value, is_visualmap=True, visual_range=[0, 3500], visual_text_color="#FFF", is_more_utils=True, is_label_show=True)
bar.render("files/无名之辈-观众来源top20.html")
print("图表生成完成")
3.2、制作观众人数TOP20的柱形图,(pyecharts-bar):
3.3、制作评论词云,(jieba、wordcloud):
生成词云核心代码:
def createWordCloud(self):
"""生成评论词云"""
comments = self.readAllComments() # 19185
# 使用 jieba 分词
commens_split = jieba.cut(str(comments), cut_all=False)
words = ''.join(commens_split)
# 给词库添加停止词
stopwords = STOPWORDS.copy()
stopwords.add("电影")
stopwords.add("一部")
stopwords.add("无名之辈")
stopwords.add("一部")
stopwords.add("一个")
stopwords.add("有点")
stopwords.add("觉得")
# 加载背景图片
bg_image = plt.imread("files/2048_bg.png")
# 初始化 WordCloud
wc = WordCloud(width=1200, height=600, background_color='#FFF', mask=bg_image, font_path='C:/Windows/Fonts/STFANGSO.ttf', stopwords=stopwords, max_font_size=400, random_state=50)
# 生成,显示图片
wc.generate_from_text(words)
plt.imshow(wc)
plt.axis('off')
plt.show()
四、修改pyecharts源码
4.1、样本数据的城市简称与数据集完整城市名匹配不上:
使用位置热点图时候,由于采集数据城市是一些简称,与pyecharts的已存在数据的城市名对不上,所以对源码进行一些修改,方便匹配一些简称。
黔南 =>黔南布依族苗族自治州
模块自带的全国主要市县经纬度在:[python安装路径]\Lib\site-packages\pyecharts\datasets\city_coordinates.json
由于默认情况下,一旦城市名不能完全匹配就会报异常,程序会停止,所以对源码修改如下(报错方法为 Geo.add()),其中添加注析为个人修改部分:
def get_coordinate(self, name, region="中国", raise_exception=False):
"""
Return coordinate for the city name.
:param name: City name or any custom name string.
:param raise_exception: Whether to raise exception if not exist.
:return: A list like [longitude, latitude] or None
"""
if name in self._coordinates:
return self._coordinates[name]
coordinate = get_coordinate(name, region=region)
# [ 20181204 添加
# print(name, coordinate)
if coordinate is None:
# 如果字典key匹配不上,尝试进行模糊查询
search_res = search_coordinates_by_region_and_keyword(region, name)
# print("###",search_res)
if search_res:
coordinate = sorted(search_res.values())[0]
# 20181204 添加 ]
if coordinate is None and raise_exception:
raise ValueError("No coordinate is specified for {}".format(name))
return coordinate
相应的需要对 __add()方法进行如下修改:
五、附录-源码
*说明:源码为本人所写,数据来源为猫眼,全部内容仅供学习,拒绝其他用途!转发请注明出处!
5.1 采集源码
# -*- coding:utf-8 -*-
import requests
from datetime import datetime, timedelta
import os
import time
import sys
class MaoyanFilmReviewSpider:
"""猫眼影评爬虫"""
def __init__(self, url, end_time, filename):
# 头部
self.headers = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
}
# 目标URL
self.target_url = url
# 数据获取时间段,start_time:截止日期,end_time:上映时间
now = datetime.now()
# 获取当天的 零点
self.start_time = now + timedelta(hours=-now.hour, minutes=-now.minute, seconds=-now.second)
self.start_time = self.start_time.replace(microsecond=0)
self.end_time = datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
# 打开写入文件, 创建目录
self.save_path = "files/"
if not os.path.exists(self.save_path):
os.makedirs(self.save_path)
self.save_file = open(self.save_path + filename, "a", encoding="utf-8")
def download(self, url):
"""下载html内容"""
print("正在下载URL: "+url)
# 下载html内容
response = requests.get(url, headers=self.headers)
# 转成json格式数据
if response.status_code == 200:
return response.json()
else:
# print(html.status_code)
print('下载数据为空!')
return ""
def parse(self, content):
"""分析数据"""
comments = []
try:
for item in content['cmts']:
comment = {
'nickName': item['nickName'], # 昵称
'cityName': item['cityName'], # 城市
'content': item['content'], # 评论内容
'score': item['score'], # 评分
'startTime': item['startTime'], # 时间
}
comments.append(comment)
except Exception as e:
print(e)
finally:
return comments
def save(self, data):
"""写入文件"""
print("保存数据,写入文件中...")
self.save_file.write(data)
def start(self):
"""启动控制方法"""
print("爬虫开始...\r\n")
start_time = self.start_time
end_time = self.end_time
num = 1
while start_time > end_time:
print("执行次数:", num)
# 1、下载html
content = self.download(self.target_url + str(start_time))
# 2、分析获取关键数据
comments = ''
if content != "":
comments = self.parse(content)
if len(comments) <= 0:
print("本次数据量为:0,退出爬取!\r\n")
break
# 3、写入文件
res = ''
for cmt in comments:
res += "%s###%s###%s###%s###%s\n" % (cmt['nickName'], cmt['cityName'], cmt['content'], cmt['score'], cmt['startTime'])
self.save(res)
print("本次数据量:%s\r\n" % len(comments))
# 获取最后一条数据的时间 ,然后减去一秒
start_time = datetime.strptime(comments[len(comments) - 1]['startTime'], "%Y-%m-%d %H:%M:%S") + timedelta(seconds=-1)
# start_time = datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
# 休眠3s
num += 1
time.sleep(3)
self.save_file.close()
print("爬虫结束...")
if __name__ == "__main__":
# 确保输入参数
if len(sys.argv) != 4:
print("请输入相关参数:[moveid]、[上映日期]和[保存文件名],如:xxx.py 42962 2018-11-09 text.txt")
exit()
# 猫眼电影ID
mid = sys.argv[1] # "1208282" # "42964"
# 电影上映日期
end_time = sys.argv[2] # "2018-11-16" # "2018-11-09"
# 每次爬取条数
offset = 15
# 保存文件名
filename = sys.argv[3]
spider = MaoyanFilmReviewSpider(url="http://m.maoyan.com/mmdb/comments/movie/%s.json?v=yes&offset=%d&startTime=" % (mid, offset), end_time="%s 00:00:00" % end_time, filename=filename)
# spider.start()
spider.start()
# t1 = "2018-11-09 23:56:23"
# t2 = "2018-11-25"
#
# res = datetime.strptime(t1, "%Y-%m-%d %H:%M:%S") + timedelta(days=-1)
# print(type(res))
MaoyanFilmReviewSpider.py
5.2 分析制图源码
# -*- coding:utf-8 -*-
from pyecharts import Geo, Bar, Bar3D
import jieba
from wordcloud import STOPWORDS, WordCloud
import matplotlib.pyplot as plt
class ACoolFishAnalysis:
"""无名之辈 --- 数据分析"""
def __init__(self):
pass
def readCityNum(self):
"""读取观众城市分布数量"""
d = {}
with open("files/myCmts2.txt", "r", encoding="utf-8") as f:
row = f.readline()
while row != "":
arr = row.split('###')
# 确保每条记录长度为 5
while len(arr) < 5:
row += f.readline()
arr = row.split('###')
# 记录每个城市的人数
if arr[1] in d:
d[arr[1]] += 1
else:
d[arr[1]] = 1 # 首次加入字典,为 1
row = f.readline()
# print(len(comments))
# print(d)
# 字典 转 元组数组
res = []
for ks in d.keys():
if ks == "":
continue
tmp = (ks, d[ks])
res.append(tmp)
# 按地点人数降序
res = sorted(res, key=lambda x: (x[1]),reverse=True)
return res
def readAllComments(self):
"""读取所有评论"""
comments = []
# 打开文件读取数据
with open("files/myCmts2.txt", "r", encoding="utf-8") as f:
row = f.readline()
while row != "":
arr = row.split('###')
# 每天记录长度为 5
while len(arr) < 5:
row += f.readline()
arr = row.split('###')
if len(arr) == 5:
comments.append(arr[2])
# if len(comments) > 20:
# break
row = f.readline()
return comments
def createCharts(self):
"""生成图表"""
# 读取数据,格式:[{"北京", 10}, {"上海",10}]
data = self.readCityNum()
# 1 热点图
geo1 = Geo("《无名之辈》观众位置分布热点图", "数据来源:猫眼,Fly采集", title_color="#FFF", title_pos="center", width="100%", height=600, background_color="#404A59")
attr1, value1 = geo1.cast(data)
geo1.add("", attr1, value1, type="heatmap", visual_range=[0, 1000], visual_text_color="#FFF", symbol_size=15, is_visualmap=True, is_piecewise=False, visual_split_number=10)
geo1.render("files/无名之辈-观众位置热点图.html")
# 2 位置图
geo2 = Geo("《无名之辈》观众位置分布", "数据来源:猫眼,Fly采集", title_color="#FFF", title_pos="center", width="100%", height=600,
background_color="#404A59")
attr2, value2 = geo1.cast(data)
geo2.add("", attr2, value2, visual_range=[0, 1000], visual_text_color="#FFF", symbol_size=15,
is_visualmap=True, is_piecewise=False, visual_split_number=10)
geo2.render("files/无名之辈-观众位置图.html")
# 3、top20 柱状图
data_top20 = data[:20]
bar = Bar("《无名之辈》观众来源排行 TOP20", "数据来源:猫眼,Fly采集", title_pos="center", width="100%", height=600)
attr, value = bar.cast(data_top20)
bar.add('', attr, value, is_visualmap=True, visual_range=[0, 3500], visual_text_color="#FFF", is_more_utils=True, is_label_show=True)
bar.render("files/无名之辈-观众来源top20.html")
print("图表生成完成")
def createWordCloud(self):
"""生成评论词云"""
comments = self.readAllComments() # 19185
# 使用 jieba 分词
commens_split = jieba.cut(str(comments), cut_all=False)
words = ''.join(commens_split)
# 给词库添加停止词
stopwords = STOPWORDS.copy()
stopwords.add("电影")
stopwords.add("一部")
stopwords.add("无名之辈")
stopwords.add("一部")
stopwords.add("一个")
stopwords.add("有点")
stopwords.add("觉得")
# 加载背景图片
bg_image = plt.imread("files/2048_bg.png")
# 初始化 WordCloud
wc = WordCloud(width=1200, height=600, background_color='#FFF', mask=bg_image, font_path='C:/Windows/Fonts/STFANGSO.ttf', stopwords=stopwords, max_font_size=400, random_state=50)
# 生成,显示图片
wc.generate_from_text(words)
plt.imshow(wc)
plt.axis('off')
plt.show()
if __name__ == "__main__":
demo = ACoolFishAnalysis()
demo.createWordCloud()
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对的支持。