与此形成鲜明对比的是另一位巨星——葡萄牙队的c罗。上赛季他虽说有42个进球,但经统计,他的效率不到10%。在这个习惯统计学的社会,c罗的42球从深层分析充满了水分。此外,他的球场道德也属于低劣派,假摔贯穿全场,无处不在,江湖人送外号 "跳水运动员 ",桃色风波更是五花八门,而两者后果呢?看看吧:梅西凭借着08—09赛季带领巴萨取得西甲、国王杯、欧洲冠军联赛三冠王,取得433分,获得金球奖,而c罗只有他的一半不到!
如下所示:
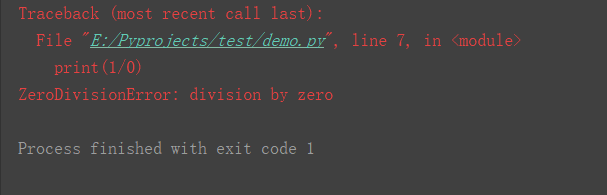
p1 = r'(?<=<div class="ds_cr">)(.*?)(?=<div id="pageurl">)' #这样采集html时出错,采集不到数据,正则中 . 是不能匹配换行符,改成如下: p1 = r'(?<=<div class="ds_cr">)([\s\S]*?)(?=<div id="pageurl">)' # 这是我们写的正则表达式规则,你现在可以不理解啥意思
[\s\S]
\s
匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
\S
匹配任何非空白字符。等价于[^ \f\n\r\t\v]。
以上这篇浅谈Python采集网页时正则表达式匹配换行符的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。