杜鹃啼血染花红,山后山前一画中。旅行的意义不在于浏览风景,而是到一个完全陌生的环境,放空自己,感受享受孤独!
数据准备
假设我们目前有两个数据表:
① 一个数据表是关于三个人他们的id以及其他的几列属性信息
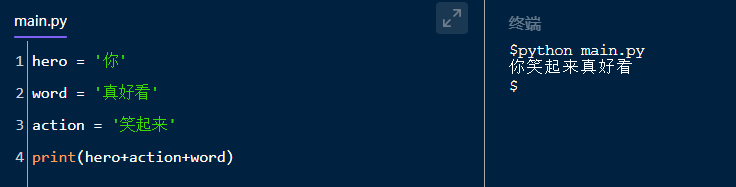
import pandas as pd import numpy as np data = pd.DataFrame(np.random.randint(low=1,high=20,size=(3,4))) data['id'] = range(1,4) # 输出:其中,最左边的0 1 2 为其索引
② 另外一个数据表是3个用户的app操作日志信息,一个人会有多条app操作记录
sample = pd.DataFrame(np.random.randint(low=1,high=9,size=(7,1)),columns=['hhh']) sample['id'] = [1,1,2,2,3,3,3] # 输出:
问题描述
① 首先我们需要统计每个用户app操作记录数,比如上表可以看出用户id为1的用户有2条操作记录,用户id为3的用户有3条操作记录
s = sample.groupby('id').count()
# 输出:
② 此时,S是一个以id为索引,count出来的记录数为value的Series结构。因为考虑到后面我们需要id列进行merge,所以我们需要让id列从索引列变成真实的一列。
s = s.reset_index() # 输出:
③ 将S与最上的data表进行merge,我们不想要看到重复的id列,甚至我们也可以将问题延伸为S与data表不止是id列的重复,还有好多条其他的列的重复,那么如何保证将它们merge之后没有重复列呢?
解决方案
第一想法是用 DataFrame.drop(‘列名') 或者用 del DataFrame[‘列名']
但是如果用该方法,会删除掉所有的重复列,而达不到我们的要求。
办法是: 参考StackOverflow解答
cols_to_use = s.columns.difference(data.columns) # pandas版本在0.15及之上的都可以用这种方法,该方法找出S和data表的不同列,然后再进行merge pd.merge(data, s[cols_to_use], left_index=True, right_index=True, how='outer')
以上就是pandas去除重复列的实现方法。高尚的理想是人生的指路明灯。有了它,生活就有了方向;有了它,内心就感到充实。我的理想是………为了这个理想,我会努力奋斗,迈开坚定的步伐,走向既定的目标吧!更多关于pandas去除重复列的实现方法请关注haodaima.com其它相关文章!