本文实例讲述了python爬虫框架scrapy实现模拟登录操作。分享给大家供大家参考,具体如下:
一、背景:
初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML、json数据,但是忽略了很多的一个问题,有很多的网站为了反爬虫,除了需要高可用代理IP地址池外,还需要登录。例如知乎,很多信息都是需要登录以后才能爬取,但是频繁登录后就会出现验证码(有些网站直接就让你输入验证码),这就坑了,毕竟运维同学很辛苦,该反的还得反,那我们怎么办呢?这不说验证码的事儿,你可以自己手动输入验证,或者直接用云打码平台,这里我们介绍一个scrapy的登录用法。
测试登录地址:http://example.webscraping.com/places/default/user/login
测试主页:http://example.webscraping.com/user/profile
1、这里不在叙述如何创建scrapy项目和spider,可以看前面的相关文章
二、快速登录方法
我们在这里做了一个简单的介绍,我们都知道scrapy的基本请求流程是start_request方法遍历start_urls列表,然后make_requests_from_url方法,里面执行Request方法,请求start_urls里面的地址,但是这里我们用的不再是GET方法,而用的是POST方法,也就常说的登录。
1、首先我们改写start_reqeusts方法,直接GET登录页面的HTML信息(有些人说你不是POST登录么,干嘛还GET,别着急,你得先GET到登录页面的登录信息,才知道登录的账户、密码等怎么提交,往哪里提交)
2、start_request方法GET到数据后,用callback参数,执行拿到response后要接下来执行哪个方法,然后在login方法里面写入登录用户名和密码(还是老样子,一定要用dict),然后只用Request子类scrapy.FormRequest这个方法提交数据,这我一个的是FormRequest.from_response方法。
有些人会问,这个from__response的基本使用是条用是需要传入一个response对象作为第一个参数,这个方法会从页面中form表单中,帮助用户创建FormRequest对象,最最最最重要的是它会帮你把隐藏的input标签中的信息自动跳入表达,使用这个中方法,我们直接写用户名和密码即可,我们在最后面再介绍传统方法。
3、parse_login方法是提交完表单后callback回调函数指定要执行的方法,为了验证是否成功。这里我们直接在response中搜索Welcome Liu这个字眼就证明登录成功。这个好理解,重点是yield from super().start_resquests(),这个代表着如果一旦登录成功后,就直接带着登录成功后Cookie值,方法start_urls里面的地址。这样的话登录成功后的response可以直接在parse里面写。
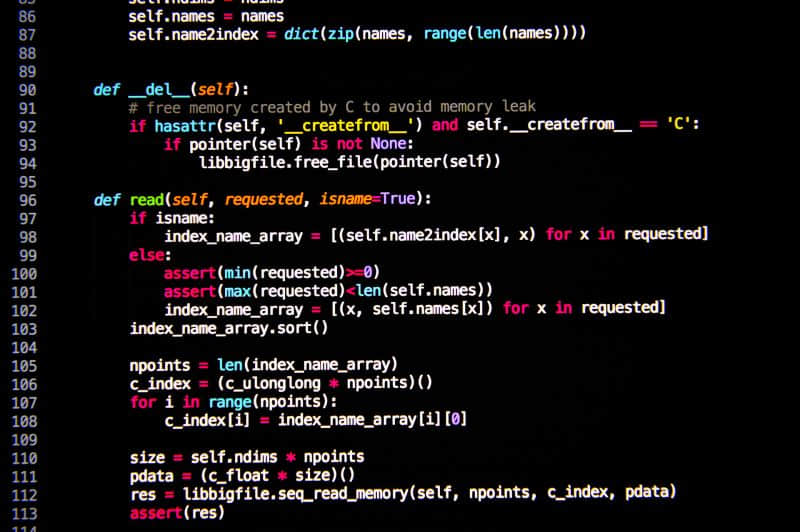
# -*- coding: utf-8 -*-
import scrapy
from scrapy import FormRequest,Request
class ExampleLoginSpider(scrapy.Spider):
name = "login_"
allowed_domains = ["example.webscraping.com"]
start_urls = ['http://example.webscraping.com/user/profile']
login_url = 'http://example.webscraping.com/places/default/user/login'
def parse(self, response):
print(response.text)
def start_requests(self):
yield scrapy.Request(self.login_url,callback=self.login)
def login(self,response):
formdata = {
'email':'liushuo@webscraping.com','password':'12345678'}
yield FormRequest.from_response(response,formdata=formdata,
callback=self.parse_login)
def parse_login(self,response):
# print('>>>>>>>>'+response.text)
if 'Welcome Liu' in response.text:
yield from super().start_requests()
有的同学可能问了,login方法里面不是应该写reture 么,其实上面的写法跟下面的这种写法是一样效果,如果再有个CSRF的话,也可以直接在login里面写拿到CSRF信息,写入到formdata里面跟用户名和密码一起提交。
return [FormRequest.from_response(response,formdata=formdata,callback=self.parse_login)]
登录成功
三、传统登录方法:
1、首先要明确一件事情,一般情况下需要登录的网站,不只需要登录用户和密码,接下来我们聊聊上面说的传统登录模式。用户在登录的时候并不是只需要登录账户信息,除了常见直观的验证码和CSRF信息外,也有可能需要提交其它信息,我们必须把它们都提取到一起提交给服务器。
2、我们在form表单下面找到了一个display:none的div标签,里面的input标签的value值正好是我们要提交的数据,那我们就提取到他。
希望本文所述对大家Python程序设计有所帮助。
以上就是python爬虫框架scrapy实现模拟登录操作示例。挺过这段难熬的时间,相信糟糕的日子熬过去了,剩下的就是好运气 。更多关于python爬虫框架scrapy实现模拟登录操作示例请关注haodaima.com其它相关文章!