秋天,稻田里的稻谷已经成熟了,一眼看去,好像铺了一地的金子,而农民伯伯们一个接一个到自己的田里捡金子。微风吹过,金色的海洋掀起一层层麦浪。
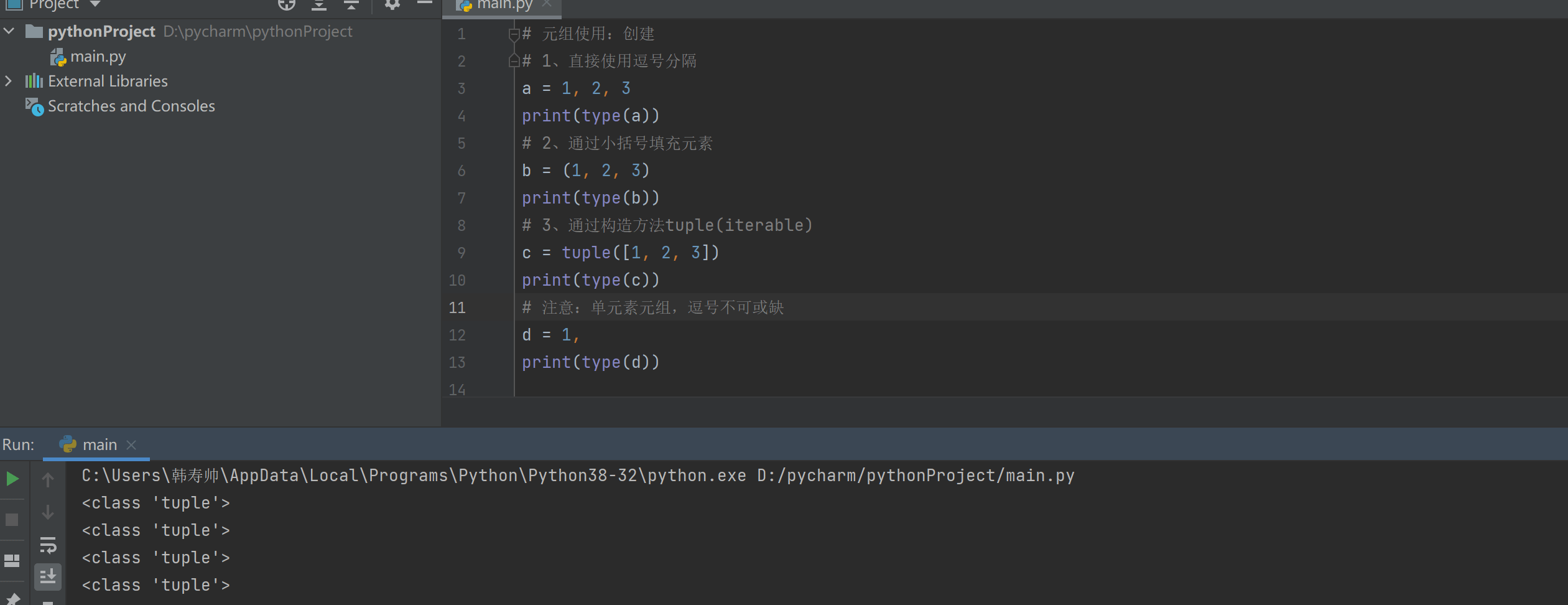
1、通过requests.get方法
r = requests.get("http://200.20.3.20:8080/job/Compile/job/aaa/496/artifact/bbb.iso")
with open(os.path.join(os.path.dirname(os.path.abspath("__file__")),"bbb.iso"),"wb") as f:
f.write(r.content)
2、urllib2方法
import urllib2
print "downloading with urllib2"
url = '"http://200.21.1.22:8080/job/Compile/job/aaa/496/artifact/bbb.iso"'
f = urllib2.urlopen(url)
data = f.read()
with open(os.path.join(os.path.dirname(os.path.abspath("__file__")),"bbb.iso"),"wb") as f:
f.write(data)
以上就是python通过http下载文件的方法详解。有记者问:“你在企业中应当是什么角色?”张瑞敏答:“第一,应是设计师;第二,应是牧师。”更多关于python通过http下载文件的方法详解请关注haodaima.com其它相关文章!