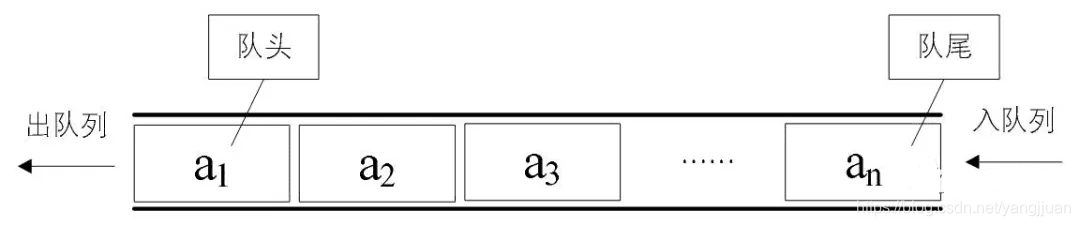
一天,当你走过蔓草荒烟,我便在那里向你轻声呼喊,以风声,以水响。斩断自己的退路,才能更好地赢得出路。
本文实例讲述了Python使用scrapy采集时伪装成HTTP/1.1的方法。分享给大家供大家参考。具体如下:
添加下面的代码到 settings.py 文件
DOWNLOADER_HTTPCLIENTFACTORY = 'myproject.downloader.HTTPClientFactory'
保存以下代码到单独的.py文件
from scrapy.core.downloader.webclient import ScrapyHTTPClientFactory, ScrapyHTTPPageGetter
class PageGetter(ScrapyHTTPPageGetter):
def sendCommand(self, command, path):
self.transport.write('%s %s HTTP/1.1\r\n' % (command, path))
class HTTPClientFactory(ScrapyHTTPClientFactory):
protocol = PageGetter
希望本文所述对大家的Python程序设计有所帮助。
到此这篇关于Python使用scrapy采集时伪装成HTTP/1.1的方法就介绍到这了。爱给予的只是它自己,取走的也只从它自己,爱不占有,也不能被占有。爱就在爱中满足。更多相关Python使用scrapy采集时伪装成HTTP/1.1的方法内容请查看相关栏目,小编编辑不易,再次感谢大家的支持!