前言
网传的七天学Python的路线如下,我觉得可以在学过此表中前几天的内容后,就可以回头来学习一下
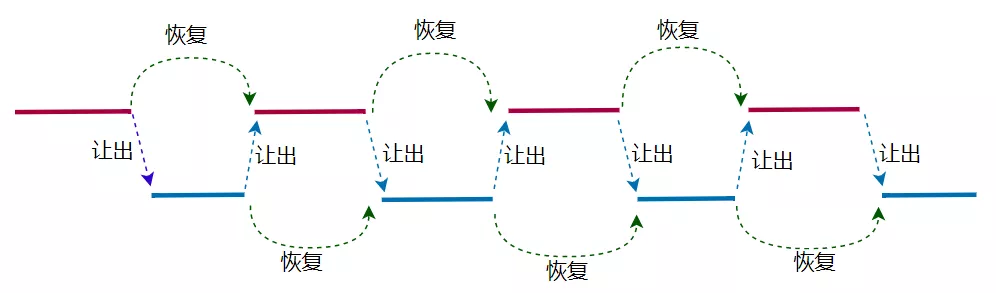
列表推导式:它综合了列表、for循环和条件语句。
第一天:基本概念(4小时) : print,变量,输入,条件语句。
第二天:基本概念(5小时) :列表,for循环,while循环,函数,导入模块。
第三天:简单编程问题(5小时) :交换两个变量值,将摄氏度转换为华氏温度,求数字中各位数之和, 判断某数是否为素数, 生成随机数,删除列表中的重复项等等。
第四天:中级编程问题(6小时) :反转-个字符串(回文检测),计算最大公约数,合并两个有序数组,猜数字游戏,计算年龄等等。
第五天:数据结构(6小时) :栈,队列,字典,元组,树,链表。
第六天:面向对象编程(OOP) (6小时) :对象,类,方法和构造函数,面向对象编程之继承。
第七天:算法(6小时) :搜索(线性和二分查找)、 排序(冒泡排序、 选择排序)、递归函数(阶乘、斐波那契数列)时间复杂度(线性、二次和常量)。
列表推导式
- list comprehension或译为列表解析式,是一种创建列表的简洁语法;
- 也可认为它是一个简版的for循环,但执行效率高于for循环。
- python 2.7+ 开始又引入了集合推导式、字典推导式,原理与列表推导式相近。
语法规范:
out_list = [out_express for out_express in input_list if out_express_condition]
其中,
- if 条件可有可无;
- for 循环可以嵌套多层,内外层循环的变量不可以同名;
- 推导式中也可以嵌套推导式,内外层推导式的变量互不影响,可以同名;
- 推导表达式out_express尽可能用内置函数,省得import或def function()。
进阶实例
乘法口诀表
>>> lst=['%sx%s=%s'%(j,i,i*j) for i in range(1,10) for j in range(1,i+1)] >>> lst ['1x1=1', '1x2=2', '2x2=4', '1x3=3', '2x3=6', '3x3=9', '1x4=4', '2x4=8', '3x4=12', '4x4=16', '1x5=5', '2x5=10', '3x5=15', '4x5=20', '5x5=25', '1x6=6', '2x6=12', '3x6=18', '4x6=24', '5x6=30', '6x6=36', '1x7=7', '2x7=14', '3x7=21', '4x7=28', '5x7=35', '6x7=42', '7x7=49', '1x8=8', '2x8=16', '3x8=24', '4x8=32', '5x8=40', '6x8=48', '7x8=56', '8x8=64', '1x9=9', '2x9=18', '3x9=27', '4x9=36', '5x9=45', '6x9=54', '7x9=63', '8x9=72', '9x9=81']
列印时,要注意它的项数通项公式是: An=n(n+1)/2+1
>>>
for i in range(9):
for j in range(i+1):
print(lst[i*(i+1)//2+j],end='\t' if i!=j else '\n')
1x1=1
1x2=2 2x2=4
1x3=3 2x3=6 3x3=9
1x4=4 2x4=8 3x4=12 4x4=16
1x5=5 2x5=10 3x5=15 4x5=20 5x5=25
1x6=6 2x6=12 3x6=18 4x6=24 5x6=30 6x6=36
1x7=7 2x7=14 3x7=21 4x7=28 5x7=35 6x7=42 7x7=49
1x8=8 2x8=16 3x8=24 4x8=32 5x8=40 6x8=48 7x8=56 8x8=64
1x9=9 2x9=18 3x9=27 4x9=36 5x9=45 6x9=54 7x9=63 8x9=72 9x9=81
>>> 或者用join()直接把 \t \n 插入列表拼接成字符串,然后输出:
>>> print('\n'.join(['\t'.join([f'{j}x{i}={i*j}' for j in range(1,i+1)]) for i in range(1,10)]))
1x1=1
1x2=2 2x2=4
1x3=3 2x3=6 3x3=9
1x4=4 2x4=8 3x4=12 4x4=16
1x5=5 2x5=10 3x5=15 4x5=20 5x5=25
1x6=6 2x6=12 3x6=18 4x6=24 5x6=30 6x6=36
1x7=7 2x7=14 3x7=21 4x7=28 5x7=35 6x7=42 7x7=49
1x8=8 2x8=16 3x8=24 4x8=32 5x8=40 6x8=48 7x8=56 8x8=64
1x9=9 2x9=18 3x9=27 4x9=36 5x9=45 6x9=54 7x9=63 8x9=72 9x9=81
>>>
>>> # f'{j}x{i}={i*j}' 等价于 '%sx%s=%s'%(j,i,i*j)求100以内的质数(或称素数)
>>> [k[0] for k in [(j,sum([j%i==0 for i in range(2,j)])) for j in range(2,100)] if k[1]==0] [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97] >>> >>> # 等价于: >>> [k[0] for k in [(j,sum([0 if j%i else 1 for i in range(2,j)])) for j in range(2,100)] if k[1]==0] [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97] >>>
上面两种方法都是累加sum布尔值bool的个数来计算的,可以用any() all()函数代替:
>>> [k[0] for k in [(j,[j%i==0 for i in range(2,j)]) for j in range(2,100)] if not any(k[1])] [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97] >>> >>> # 等价于: >>> [k[0] for k in [(j,[j%i!=0 for i in range(2,j)]) for j in range(2,100)] if all(k[1])] [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97] >>>
使用filter()和map()函数:
[i for i in filter(lambda x:all(map(lambda p:x%p,range(2,x))), range(2,100))] [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97] >>>
条件反过来就是100以内的合数:
>>> [k[0] for k in [(j,[j%i==0 for i in range(2,j)]) for j in range(2,100)] if any(k[1])] [4, 6, 8, 9, 10, 12, 14, 15, 16, 18, 20, 21, 22, 24, 25, 26, 27, 28, 30, 32, 33, 34, 35, 36, 38, 39, 40, 42, 44, 45, 46, 48, 49, 50, 51, 52, 54, 55, 56, 57, 58, 60, 62, 63, 64, 65, 66, 68, 69, 70, 72, 74, 75, 76, 77, 78, 80, 81, 82, 84, 85, 86, 87, 88, 90, 91, 92, 93, 94, 95, 96, 98, 99] >>> [k[0] for k in [(j,[j%i!=0 for i in range(2,j)]) for j in range(2,100)] if not all(k[1])] [4, 6, 8, 9, 10, 12, 14, 15, 16, 18, 20, 21, 22, 24, 25, 26, 27, 28, 30, 32, 33, 34, 35, 36, 38, 39, 40, 42, 44, 45, 46, 48, 49, 50, 51, 52, 54, 55, 56, 57, 58, 60, 62, 63, 64, 65, 66, 68, 69, 70, 72, 74, 75, 76, 77, 78, 80, 81, 82, 84, 85, 86, 87, 88, 90, 91, 92, 93, 94, 95, 96, 98, 99] >>> [i for i in filter(lambda x:not all(map(lambda p:x%p,range(2,x))), range(2,100))] [4, 6, 8, 9, 10, 12, 14, 15, 16, 18, 20, 21, 22, 24, 25, 26, 27, 28, 30, 32, 33, 34, 35, 36, 38, 39, 40, 42, 44, 45, 46, 48, 49, 50, 51, 52, 54, 55, 56, 57, 58, 60, 62, 63, 64, 65, 66, 68, 69, 70, 72, 74, 75, 76, 77, 78, 80, 81, 82, 84, 85, 86, 87, 88, 90, 91, 92, 93, 94, 95, 96, 98, 99] >>>
求1000以内的质回文数(即是质数又是回文数)
>>> Pr=[str(k[0]) for k in [(j,[j%i!=0 for i in range(2,j)]) for j in range(2,1000)] if all(k[1])] >>> [int(p) for p in Pr if p[::-1] in Pr] [2, 3, 5, 7, 11, 101, 131, 151, 181, 191, 313, 353, 373, 383, 727, 757, 787, 797, 919, 929]
求1000以内的数,满足本身和它的回文数同是质数
>>> pstr=[str(k[0]) for k in [(j,[j%i!=0 for i in range(2,j)]) for j in range(2,1000)] if all(k[1])] >>> [int(p) for p in pstr if p[::-1] in pstr] [2, 3, 5, 7, 11, 13, 17, 31, 37, 71, 73, 79, 97, 101, 107, 113, 131, 149, 151, 157, 167, 179, 181, 191, 199, 311, 313, 337, 347, 353, 359, 373, 383, 389, 701, 709, 727, 733, 739, 743, 751, 757, 761, 769, 787, 797, 907, 919, 929, 937, 941, 953, 967, 971, 983, 991] >>>
分解质因数(N<2022)
>>> P = [k[0] for k in [(j,sum([j%i==0 for i in range(2,j)])) for j in range(2,2022)] if k[1]==0]
>>>
def func(n):
res=[]
t=P[::-1]
m=t[-1]
while n>=m:
if n%m==0:
n//=m
res.append(m)
else:
t.pop()
m=t[-1]
return res
>>> i = 2021
>>> print(i,'=','x'.join([str(j) for j in func(i)]))
2021 = 43x47
>>>
>>> func(2000)
[2, 2, 2, 2, 5, 5, 5]
>>> func(3999)
[3, 31, 43]
>>> 求出字符串的所有字串(可推广到所有可切片数据类型)
>>> L='abcd' >>> [L[i:j] for i in range(len(L)) for j in range(i+1,len(L)+1)] ['a', 'ab', 'abc', 'abcd', 'b', 'bc', 'bcd', 'c', 'cd', 'd'] >>>
注:凡是可以用[i:j]来切片的“容器类”数据类型都可用此推导式。
如:
>>> L=[1,2,3,4] >>> [L[i:j] for i in range(len(L)) for j in range(i+1,len(L)+1)] [[1], [1, 2], [1, 2, 3], [1, 2, 3, 4], [2], [2, 3], [2, 3, 4], [3], [3, 4], [4]] >>>
(1)找出字符串s='aaabcddcbddba'中最长的回文字串
>>> s='aaabcddcbddba'
>>> {s[i:j] for i in range(len(s)) for j in range(i+1,len(s)+1)}
{'bcddcbdd', 'ddcbddb', 'abcddcbdd', 'aabcddc', 'aabcddcbdd', 'cbddba', 'aaa',
'cddcbd', 'cbddb', 'a', 'cdd', 'bcdd', 'aabcddcbddba', 'aabcd', 'abcddcbddb',
'aaabc', 'ab', 'cbdd', 'cddcbdd', 'aaabcddcb', 'aabcddcbd', 'aaabcdd', 'ba',
'ddcbddba', 'dba', 'db', 'cddcbddba', 'cbd', 'aaabcddcbddb', 'aaabcd', 'ddb',
'dcbdd', 'abcddc', 'abcd', 'abcdd', 'bcddcb', 'aaabcddcbdd', 'abcddcbddba',
'aabc', 'bcddc', 'bdd', 'cb', 'bcddcbddba', 'c', 'dcbddb', 'ddba', 'dcbd',
'b', 'aaab', 'dd', 'd', 'ddcbd', 'bcd', 'aa', 'abcddcbd', 'bcddcbddb',
'aaabcddcbd', 'cddc', 'ddcb', 'dc', 'abc', 'bddb', 'ddc', 'bcddcbd', 'bc',
'aabcdd', 'aab', 'aaabcddcbddba', 'cddcb', 'abcddcb', 'cd', 'bddba', 'aabcddcbddb',
'bd', 'ddcbdd', 'aaabcddc', 'dcb', 'dcbddba', 'aabcddcb', 'cddcbddb'}
>>> # 使用字典推导式可去掉相同子串
>>>
>>> [i for i in {s[i:j] for i in range(len(s)) for j in range(i+1,len(s)+1)} if i==i[::-1]]
['aaa', 'a', 'bcddcb', 'c', 'b', 'dd', 'd', 'aa', 'cddc', 'bddb']
>>>
>>> [(len(i),i) for i in {i for i in [s[i:j] for i in range(len(s)) for j in range(i+1,len(s)+1)} if i==i[::-1]]]
[(3, 'aaa'), (1, 'a'), (6, 'bcddcb'), (1, 'c'), (1, 'b'), (2, 'dd'), (1, 'd'),
(2, 'aa'), (4, 'cddc'), (4, 'bddb')]
>>>
>>> max([(len(i),i) for i in [i for i in {s[i:j] for i in range(len(s)) for j in range(i+1,len(s)+1)} if i==i[::-1]]])[1]
'bcddcb'
>>>(2)给定 L=[2, -3, 3, 50, 5, 0, -1],输出其子序列中各元素合计数最大的子序列
>>> L = [2, -3, 3, 50, 5, 0, -1] >>> [L[i:j] for i in range(len(L)) for j in range(i+1,len(L)+1)] [[2], [2, -3], [2, -3, 3], [2, -3, 3, 50], [2, -3, 3, 50, 5], [2, -3, 3, 50, 5, 0], [2, -3, 3, 50, 5, 0, -1], [-3], [-3, 3], [-3, 3, 50], [-3, 3, 50, 5], [-3, 3, 50, 5, 0], [-3, 3, 50, 5, 0, -1], [3], [3, 50], [3, 50, 5], [3, 50, 5, 0], [3, 50, 5, 0, -1], [50], [50, 5], [50, 5, 0], [50, 5, 0, -1], [5], [5, 0], [5, 0, -1], [0], [0, -1], [-1]] >>> [sum(j) for j in [L[j:i] for i in range(len(L),0,-1) for j in range(len(L))]] [56, 54, 57, 54, 4, -1, -1, 57, 55, 58, 55, 5, 0, 0, 57, 55, 58, 55, 5, 0, 0, 52, 50, 53, 50, 0, 0, 0, 2, 0, 3, 0, 0, 0, 0, -1, -3, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0] >>> # 合并为一行代码: >>> max(sum(j) for j in [L[j:i] for i in range(len(L),0,-1) for j in range(len(L))]) 58 >>> >>> # 和最大的子序列为: >>> l = [L[i:j] for i in range(len(L)) for j in range(i+1,len(L)+1)] >>> m = max(sum(j) for j in [L[j:i] for i in range(len(L),0,-1) for j in range(len(L))]) >>> [i for i in l if sum(i)==m] [[3, 50, 5], [3, 50, 5, 0]] >>>
根据方程式画出字符图
略:见相关文章《探究“一行代码画爱心”的秘密,去向心爱的人表白吧》
EXCEL表格列号字串转整数
>>> ExcelCol2Int = lambda s:sum([(ord(n)-64)*26**i for i,n in enumerate(list(s)[::-1])])
>>> ExcelCol2Int('A')
1
>>> ExcelCol2Int('AA')
27
>>> ExcelCol2Int('AX')
50
>>> ExcelCol2Int('CV')
100
>>> ExcelCol2Int('AAA')
703
>>> ExcelCol2Int('XFD')
16384
>>>打印Gray格雷码序列
什么是格雷码,什么是卡诺图?不懂的问度娘吧
Gray = lambda n:[(i>>1)^i for i in range(2**n)] GrayB = lambda n:[bin((i>>1)^i)[2:].rjust(n,'0') for i in range(2**n)] ''' Gray(0) [0] Gray(1) [0, 1] Gray(2) [0, 1, 3, 2] Gray(3) [0, 1, 3, 2, 6, 7, 5, 4] Gray(4) [0, 1, 3, 2, 6, 7, 5, 4, 12, 13, 15, 14, 10, 11, 9, 8] >>> GrayB(3) # 把输出排成矩阵,即三变量卡诺图 ['000', '001', '011', '010', '110', '111', '101', '100'] >>> GrayB(4) # 把输出排成方阵,即四变量卡诺图 ['0000', '0001', '0011', '0010', '0110', '0111', '0101', '0100', '1100', '1101', '1111', '1110', '1010', '1011', '1001', '1000'] '''
注:上面代码中的 (i>>1)^i 可以写成: i^i>>1 或 i^i//2,因为右移或整除的运算级别都比异或要高。验证代码如下:
>>> any([(i>>1)^i == i^i>>1 == i^i//2 for i in range(323)]) True >>>
另外,观察到Gray()输出的整数序列的规律,就想到用迭代法也能实现,并且只要2行代码:
# 用迭代法实现: def iGray(n): if n==0: return [0] return iGray(n-1)+[i+2**(n-1) for i in iGray(n-1)[::-1]]
高阶实例
杨辉三角形
方法一:公式递推
>>> def func(i): t=L=[1] while(i>1): i-=1 t=L+[t[n]+t[n+1] for n in range(len(t)-1)]+L return t >>> func(1) [1] >>> func(3) [1, 2, 1] >>> func(8) [1, 7, 21, 35, 35, 21, 7, 1] >>> >>> for i in range(1,10):print(func(i)) [1] [1, 1] [1, 2, 1] [1, 3, 3, 1] [1, 4, 6, 4, 1] [1, 5, 10, 10, 5, 1] [1, 6, 15, 20, 15, 6, 1] [1, 7, 21, 35, 35, 21, 7, 1] [1, 8, 28, 56, 70, 56, 28, 8, 1] >>>
方法二:组合公式的自定义函数
>>> def Combin(n,i):
m,t=min(i,n-i),1
for j in range(0,m):
t*=(n-j)/(m-j)
return t
>>> [Combin(8,i) for i in range(9)]
[1, 8.0, 28.0, 55.99999999999999, 70.0, 55.99999999999999, 28.0, 8.0, 1]
>>> [round(Combin(8,i)) for i in range(9)]
[1, 8, 28, 56, 70, 56, 28, 8, 1]
>>> [[round(Combin(j,i)) for i in range(j+1)] for j in range(10)]
[[1], [1, 1], [1, 2, 1], [1, 3, 3, 1], [1, 4, 6, 4, 1], [1, 5, 10, 10, 5, 1],
[1, 6, 15, 20, 15, 6, 1], [1, 7, 21, 35, 35, 21, 7, 1], [1, 8, 28, 56, 70, 56,
28, 8, 1], [1, 9, 36, 84, 126, 126, 84, 36, 9, 1]]
>>>根据组合公式用阶乘来计算:
C(m,n)=math.factorial(n)//(math.factorial(m)*math.factorial(n-m))
递归法,虽然没有小数精度的问题,但也有递归次数不能太大即n值有限制的缺点:
>>> def Comb(n,i):
if i in [0,n]:
return 1
elif i==1:
return n
else:
return Comb(n-1,i-1)+Comb(n-1,i)
>>> [Comb(8,i) for i in range(9)]
[1, 8, 28, 56, 70, 56, 28, 8, 1]
>>> print('\n'.join(['\t'.join([str(Comb(j,i)) for i in range(j+1)]) for j in range(10)]))
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
1 6 15 20 15 6 1
1 7 21 35 35 21 7 1
1 8 28 56 70 56 28 8 1
1 9 36 84 126 126 84 36 9 1
>>>方法三:使用现成的库函数
(1). itertools库combinations函数
>>> from itertools import combinations as comb
>>> [[len(list(comb(range(j),i))) for i in range(j+1)] for j in range(10)]
[[1], [1, 1], [1, 2, 1], [1, 3, 3, 1], [1, 4, 6, 4, 1], [1, 5, 10, 10, 5, 1],
[1, 6, 15, 20, 15, 6, 1], [1, 7, 21, 35, 35, 21, 7, 1], [1, 8, 28, 56, 70, 56,
28, 8, 1], [1, 9, 36, 84, 126, 126, 84, 36, 9, 1]]
>>> print('\n'.join(['\t'.join([str(len(list(comb(range(j),i)))) for i in range(j+1)]) for j in range(10)]))
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
1 6 15 20 15 6 1
1 7 21 35 35 21 7 1
1 8 28 56 70 56 28 8 1
1 9 36 84 126 126 84 36 9 1
>>>(2). scipy库comb函数
>>> from scipy.special import comb
>>> [[round(comb(j,i)) for i in range(j+1)] for j in range(10)]
[[1], [1, 1], [1, 2, 1], [1, 3, 3, 1], [1, 4, 6, 4, 1], [1, 5, 10, 10, 5, 1],
[1, 6, 15, 20, 15, 6, 1], [1, 7, 21, 35, 35, 21, 7, 1], [1, 8, 28, 56, 70, 56,
28, 8, 1], [1, 9, 36, 84, 126, 126, 84, 36, 9, 1]]
>>> print('\n'.join(['\t'.join([str(round(comb(j,i))) for i in range(j+1)]) for j in range(10)]))
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
1 6 15 20 15 6 1
1 7 21 35 35 21 7 1
1 8 28 56 70 56 28 8 1
1 9 36 84 126 126 84 36 9 1
>>>斐波那契数列
(1). 引入自定义函数或lambda表达式:
>>> f=lambda n:n<3 and 1 or f(n-1)+f(n-2) >>> [f(i) for i in range(1,30)] [1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, 196418, 317811, 514229] >>>
注:这个lambda函数用了递归法,在项数大于40后速度超慢。
另:类似【n<3 and 1 or 2】这种表达式中,逻辑与、或有这样的特性:
and 两边都对取后面一个表达式, or 两边都对取前面一个表达式。
>>> n=5 >>> 1 and n 5 >>> n and 1 1 >>> 0 and n 0 >>> n and 0 0 >>> 1 or n 1 >>> n or 1 5 >>> 0 or n 5 >>> n or 0 5 >>>
(2). 引入临时推导表达式:
>>> N=50 # 项数=50 >>> f=[1,1] >>> [f.append(f[n-2]+f[n-1]) for n in range(2,N)] [None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None] >>> f [1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, 196418, 317811, 514229, 832040, 1346269, 2178309, 3524578, 5702887, 9227465, 14930352, 24157817, 39088169, 63245986, 102334155, 165580141, 267914296, 433494437, 701408733, 1134903170, 1836311903, 2971215073, 4807526976, 7778742049, 12586269025] >>> ###合成一行,临时变量接收[None]*n列表### >>> f=[1,1];t=[f.append(f[n-2]+f[n-1]) for n in range(2,N)] >>> f [1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, 196418, 317811, 514229, 832040, 1346269, 2178309, 3524578, 5702887, 9227465, 14930352, 24157817, 39088169, 63245986, 102334155, 165580141, 267914296, 433494437, 701408733, 1134903170, 1836311903, 2971215073, 4807526976, 7778742049, 12586269025] >>>
真的一行代码:
>>> N=50 # 项数=50 >>> t=[(f[n][0], f.append((f[n][1],f[n][0]+f[n][1]))) for f in ([[1,1]],) for n in range(N)] >>> t [(1, None), (1, None), (2, None), (3, None), (5, None), (8, None), (13, None), (21, None), (34, None), (55, None), (89, None), (144, None), (233, None), (377, None), (610, None), (987, None), (1597, None), (2584, None), (4181, None), (6765, None), (10946, None), (17711, None), (28657, None), (46368, None), (75025, None), (121393, None), (196418, None), (317811, None), (514229, None), (832040, None), (1346269, None), (2178309, None), (3524578, None), (5702887, None), (9227465, None), (14930352, None), (24157817, None), (39088169, None), (63245986, None), (102334155, None), (165580141, None), (267914296, None), (433494437, None), (701408733, None), (1134903170, None), (1836311903, None), (2971215073, None), (4807526976, None), (7778742049, None), (12586269025, None)] >>> [f[0] for f in t] [1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, 196418, 317811, 514229, 832040, 1346269, 2178309, 3524578, 5702887, 9227465, 14930352, 24157817, 39088169, 63245986, 102334155, 165580141, 267914296, 433494437, 701408733, 1134903170, 1836311903, 2971215073, 4807526976, 7778742049, 12586269025] >>> ###合并成一行### >>> [f[0] for f in [(f[n][0], f.append((f[n][1],f[n][0]+f[n][1]))) for f in ([[1,1]],) for n in range(N)]] [1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, 196418, 317811, 514229, 832040, 1346269, 2178309, 3524578, 5702887, 9227465, 14930352, 24157817, 39088169, 63245986, 102334155, 165580141, 267914296, 433494437, 701408733, 1134903170, 1836311903, 2971215073, 4807526976, 7778742049, 12586269025] >>>
曼德勃罗集(Mandelbrot Set)分形
>>> print('\n'.join([''.join(['*'if abs((lambda a:lambda z,c,n:a(a,z,c,n))(lambda s,z,c,n:s(s,z*z+c,c,n-1) if n else z)(0,0.02*x+0.05j*y,40))<2 else ' ' for x in range(-78,20)]) for y in range(-20,21)]))
*
**
***********
************
*********
* * ************ * *
****** * *************************** *
*************************************** *****
*******************************************
*** ******************************************** *
**************************************************
*******************************************************
* * *****************************************************
**** ******* * *******************************************************
***************** *******************************************************
*********************** *********************************************************
*********************** ********************************************************
**** ********************************************************************************
*******************************************************************************************
**** ********************************************************************************
*********************** ********************************************************
*********************** *********************************************************
***************** *******************************************************
**** ******* * *******************************************************
* * *****************************************************
*******************************************************
**************************************************
*** ******************************************** *
*******************************************
*************************************** *****
****** * *************************** *
* * ************ * *
*********
************
***********
**
*
>>>附录
到此这篇关于Python之列表推导式最全汇总(下篇)的文章就介绍到这了,关于Python之列表推导式最全汇总的所有内容也全部结束了,其他两个部分的内容(上、中篇)请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!