前言
如果你要在代码里读取一个文件,那么你首先要知道这个文件的路径。如果只有一个文件,那么很简单,直接复制这个文件所在的文件夹路径及其文件名即可。而在很多情况下,我们会处理大量的文件,这些文件一般都会按一定的规则存放在一个或几个文件夹里。本文便是简单讲一下怎么应对这种情况,将以Python为例,但其中的理念是通用的。
1 什么是文件路径
文件路径简单地说就是文件的存放位置,它包含具体的盘符号,也就是位于电脑上哪个磁盘分区、哪个文件夹(目录)和最终这个文件的名称+文件类型扩展名。
文件的路径表示用户在磁盘上寻找文件时,所历经的文件夹线路;路径分为绝对路径和相对路径;绝对路径是从根文件夹开始的路径;相对路径是从当前文件夹开始的路径。
1.1 绝对路径
不同操作系统下绝对路径的表现形式是不一样的,以Windows系统为例,一个文件的路径可能是这样的:
D:\files\data\ndvi.tif
其中:
D:\:表示根文件夹,是文件所在的盘符,即D盘。D:\files\data:表示文件所在的文件夹的路径,即D盘的files文件夹的子文件夹data。ndvi.tif:表示文件名,其中ndvi是基本名,用来标识这个文件;tif是扩展名,用来反映文件的类型,二者用.分开。
Linux和MacOS下的绝对路径和Windows系统不同,主要区别如下:
- 根文件夹不同,Windows的根文件夹是盘符,如D:\、C:\;而在Linux和MacOS中,根文件夹是/,你可以理解为所有的文件都在一个盘下,自然不需要用C、D这样的字符去区分了。
- 分隔符不同,在Windows 上,路径书写使用倒斜杠\作为文件夹之间的分隔符。但在MacOS和Linux上,使用正斜杠/作为它们的路径分隔符。
- 大小写区分不同,文件夹名称和文件名在Windows和MacOS上是不区分大小写的,但在Linux上是区分大小写的。
附加卷的路径:
附加卷,诸如DVD驱动器或USB闪存驱动器,在不同的操作系统上显示也不同。在Windows上,它们表示为新的、带字符的根驱动器。诸如
D:\或E:\。在MacOS上,它们表示为新的文件夹,在/Volumes文件夹下。在Linux上,它们表示为新的文件夹,在/mnt文件夹下。
1.2 相对路径
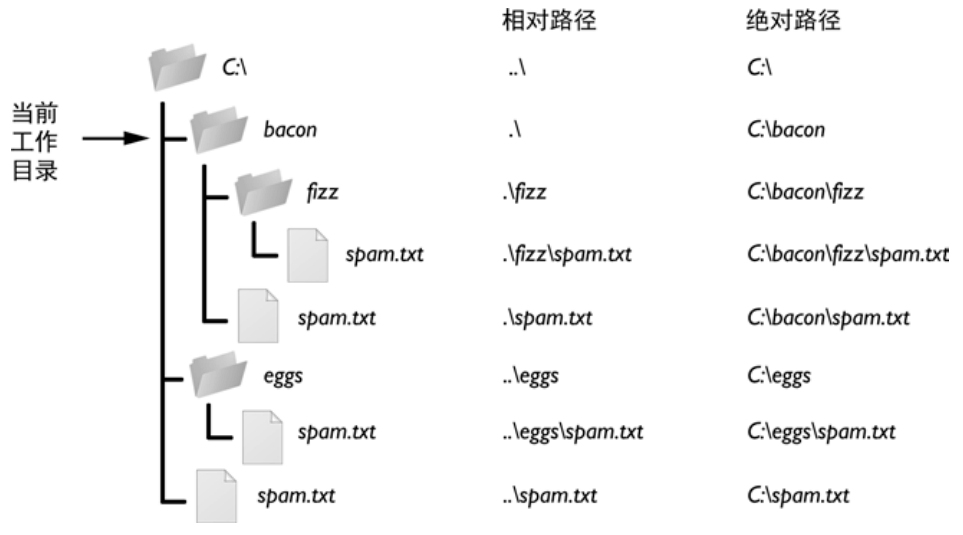
相对路径是指以当前工作目录为参照基础,链接到目标文件资源(或文件夹)的路径。
相对路径的表示符号如下:
- 以
./开头,代表当前目录和文件目录在同一个目录里,./也可以省略不写; - 以
../开头:向上走一级,代表目标文件在当前文件所在的上一级目录; - 以
../../开头:向上走两级,代表父级的父级目录,也就是上上级目录,再说明白点,就是上一级目录的上一级目录; - 以
/开头,代表根目录。
相对路径使用示例:
2 Python对路径的操作
2.1 在Python中怎么表示文件路径
在Python中,一般使用字符串存储文件路径。但需要注意的是,字符反斜杠\在Python中表示转义字符。因此,在表示Windows系统下的文件路径(Windows系统的分隔符是\)时需注意以下要点:
- 以路径D:\files\data\ndvi.tif为例;
- 在字符串前加个字符r,表示该字符串为原始字符串,会完全忽略所有的转义字符。例如,r"D:\files\data\ndvi.tif";
- 对转义字符进行转义,例如,"D:\\files\\data\\ndvi.tif";
- 将分隔符替换为/,是的,在Windows系统下,将分隔符替换为/Python也能正确识别。例如,"D:/files/data/ndvi.tif"。
Linux和MacOS下,直接将路径放到单引号或者双引号里就行。
2.2 创建新文件夹
可以用os.mkdir()函数创建新文件夹(目录),使用os.path.isdir()函数判断一个路径是不是文件夹,如下所示:
import os path = "D:/files/data" if os.path.isdir(path): os.mkdir(path)
需要注意的是,os.mkdir()函数只能创建单级目录。如上面的代码所示,只有"D:/files"目录存在,才能在其下创建data目录。要想创建多级目录,则要使用os.makedirs()函数,例如:
import os path = "D:/files/data" if os.path.isdir(path): os.makedirs(path)
os.listdir()方法用于返回指定的文件夹包含的文件或文件夹的名字的列表,只支持在 Unix, Windows 下使用,例如:
>>> import os
>>> os.listdir("D:/files/data")
['ndvi.tif', 'ndvi_2023_01.tif']
2.3 拼接和拆分文件夹
os.path.join()函数用于路径拼接文件路径,可以传入多个路径,它会根据操作系统的不同自动确定分隔符。
>>> import os
>>> os.path.join(r'D:\files\data', 'ndvi_2023_01.tif')
'D:\\files\\data\\ndvi_2023_01.tif'
>>> os.path.join('D:/files/data', 'ndvi_2023_01.tif')
'D:/files/data\\ndvi_2023_01.tif'
>>> os.path.join('./data', 'ndvi_2023_01.tif')
'./data\\ndvi_2023_01.tif'
>>> os.path.join('files', 'data', 'ndvi_2023_01.tif')
'files\\data\\ndvi_2023_01.tif'os.path.split()函数可以把一个路径拆分为两部分,后一部分总是最后级别的目录或文件名。os.path.splitext()函数同样可以把一个路径拆分为两部分,后一部分总是最后的文件扩展名。
>>> os.path.split("D:/files/data/ndvi.tif")
('D:/files/data', 'ndvi.tif')
>>> os.path.split("D:/files/data")
('D:/files', 'data')
>>> os.path.splitext("D:/files/data/ndvi.tif")
('D:/files/data/ndvi', '.tif')
>>> os.path.splitext("D:/files/data")
('D:/files/data', '')此外,os.path.basename()函数用于获取路径最后的文件名或文件夹名,os.path.dirname()函数用于去掉最后的文件名或文件夹名,返回余下的文件夹路径。
>>> os.path.basename("D:/files/data/ndvi.tif")
'ndvi.tif'
>>> os.path.basename("D:/files/data")
'data'
>>> os.path.dirname("D:/files/data/ndvi.tif")
'D:/files/data'
>>> os.path.dirname("D:/files/data")
'D:/files'2.4 处理绝对路径和相对路径
os.path模块提供了一些函数,返回一个相对路径的绝对路径,以及检查给定的路径是否为绝对路径。
- os.getcwd():获取当前工作目录;
- os.path.abspath(path):返回参数的绝对路径的字符串,以当前工作目录为基准。这是将相对路径转换为绝对路径的简便方法;
- os.path.isabs(path):如果参数是一个绝对路径,就返回True,如果参数是一个相对路径,就返回 False;
- os.path.relpath(path, start):将返回从start路径到path的相对路径的字符串。如果没有提供start,就使用当前工作目录作为开始路径。
代码示例:
>>> os.getcwd()
'C:\\Python34'
>>> os.path.abspath('.')
'C:\\Python34'
>>> os.path.abspath('.\\Scripts')
'C:\\Python34\\Scripts'
>>> os.path.isabs('.')
False
>>> os.path.isabs(os.path.abspath('.'))
True
>>> os.path.relpath('C:\\Windows', 'C:\\')
'Windows'
>>> os.path.relpath('C:\\Windows', 'C:\\spam\\eggs')
'..\\..\\Windows'2.4 使用glob查找文件夹或文件
glob模块用来查找文件目录和文件,并将搜索的到的结果返回到一个列表中。
在使用glob模块之前,需要先了解一下它的三个通配符,即*、?和[],其具体含义如下:
*:代表0个或多个字符;?:代表一个字符;[]:匹配指定范围内的字符,如[0-9]匹配数字;[a-c]匹配字母a、b或c,不区分大小写;[12a]匹配字母1、2或a。
下面通过一个例子详细讲一下这三个通配符怎么使用,假如你有如下所示的目录结构:
+-- D:/
| +-- data1
| | +-- readme.md
| | +-- ndvi.tif
| | +-- buliding.tif
| +-- data2
| | +-- ndvi.tif
| | +-- water.tif
| +-- picture
| | +-- mm.tif
|
假如你要查找data1下的所有以.tif结尾的文件,你可以这样写:
>>> from glob import glob
>>> glob('D:/data1/*.tif')
['D:/data1/ndvi.tif', 'D:/data1/buliding.tif']假如你要查找data开头的目录下的所有名为ndvi.tif的文件,你可以这样写:
>>> glob('D:/data*/ndvi.tif')
['D:/data1/ndvi.tif', 'D:/data2/ndvi.tif']
>>> glob('D:/data?/ndvi.tif')
['D:/data1/ndvi.tif', 'D:/data2/ndvi.tif']
>>> glob('D:/data[1-2]/ndvi.tif')
['D:/data1/ndvi.tif', 'D:/data2/ndvi.tif']3 多个文件的路径操作示例
在数据处理中,很多时候我们都会有这样的要求,处理多个文件,并且要按照一定的顺序。最常见的就是按照时间顺序排列各个文件的路径,比如按年、月、日等,下面详细介绍几个例子。
3.1 年尺度数据
假如你有如下目录结构:
+-- D:/
| +-- data
| | +-- 2000.tif
| | +-- 2001.tif
... ... ... ... ...
| | +-- 2019.tif
| | +-- 2020.tif
|
如果你要读取data目录下2000-2020年所有文件的路径(按时间顺序排列),你可以这样写:
import os
from glob import glob
# glob会自动排序这些文件路径,排序的规则为文件名
paths = glob('D:/data/*.tif*')
# 或者这样写,可以指定开始和结束年份
paths = []
root_dir = 'D:/data'
start_year, end_year = 2000, 2020
for year in range(start_year, end_year):
path = os.path.join(root_dir, f'{year}.tif')
paths.append(path)
3.2 月尺度数据
假如你有如下目录结构:
+-- D:/
| +-- data
| | +-- 200001.tif
| | +-- 200002.tif
... ... ... ... ...
| | +-- 200012.tif
| | +-- 200101.tif
... ... ... ... ...
| | +-- 202012.tif
|
假如你要读取data目录下某一年或某几年所有月的tif数据,你可以这样写:
import os
from glob import glob
# 读取2015年所有月的数据
year = 2015
paths = glob(f'D:/data/{year}*.tif*')
# 读取2015-2020年所有月的数据
paths = []
root_dir = 'D:/data'
start_year, end_year = 2015, 2020
for year in range(start_year, end_year):
path += os.path.join(root_dir, f'{year}*.tif')假如你要读取data目录特定年在某个季节的tif数据,你可以这样写:
import os
from glob import glob
# 假设一年的冬季为当年的1月、2月以及上一年的12月
season_months = {'spring': ['03', '04', '05'], 'summer': ['06', '07', '08'],
'autumn': ['09', '10', '11'], 'winter': ['01', '02']}
paths = []
root_dir = 'D:/data'
season = 'spring'
years = [2014, 2015, 2016]
for year in years:
months = season_months[season]
for month in months:
path = os.path.join(root_dir, 'f{year}{month}.tif')
assert path
paths.append(path)
if season == 'winter':
path = os.path.join(root_dir, 'f{year-1}{12}.tif')
assert path
paths.append(path)3.3 日尺度数据
假如你有如下目录结构,如文件名中的1982001表示数据拍摄时间为1982年的第1天。
./ndvi/AVH13C1.A1982001.N07.005.2017161044559.NDVI.tif —— 1982001 —— 1982年第1天
./ndvi/AVH13C1.A1982002.N07.005.2017161050433.NDVI.tif —— 1982002 —— 1982年第2天
./ndvi/AVH13C1.A1982003.N07.005.2017161052408.NDVI.tif —— 1982003 —— 1982年第3天
./ndvi/AVH13C1.A1982004.N07.005.2017161054145.NDVI.tif —— 1982004 —— 1982年第4天
./ndvi/AVH13C1.A1982005.N07.005.2017161055856.NDVI.tif —— 1982005 —— 1982年第5天
./ndvi/AVH13C1.A1982006.N07.005.2017161061328.NDVI.tif —— 1982006 —— 1982年第6天
假如你要读取某一年年某一月中所有天的数据的路径,你可以这样写:
import os
import calendar
from glob import glob
from datetime import datetime
def get_year_month_paths(root_path, year, month):
'''获取某年某月所有NDVI文件的路径'''
paths = []
# 用于glob函数的通配符字符串,可视作文件名模板
fmt = '*{}{:03}*.tif'
# 计算该年该月共有多少天
month_days = calendar.monthrange(year, month)[1]
# 计算该年该月的第一天是一年中的第几天
month_start_day = (datetime(year, month, 1) - datetime(year, 1, 1)).days + 1
for i in range(month_days):
day_num = month_start_day + i
month_day_path = glob(os.path.join(root_path, fmt.format(year, day_num)))
if not month_day_path:
print('{}年{}月的数据缺失,编号为{}{:03}'.format(year, month, year, day_num))
paths += month_day_path
return paths
3.4 文件的时间顺序隐藏在文件内
有些文件你下载时的默认文件名是一堆无意义的字符,而你知道这些文件里存储的有时间信息,所以就没有对这些文件一一命名。当你要用时你就会发现很麻烦,要按时间顺序读取这些文件,靠文件名没法做到,而文件太多,一个个打开看一下时间再重命名又太慢了。这样只能在代码里一个个打开文件,读取其时间,并依据这些时间对文件的路径进行排序。这种情况常见于.nc或.hdf格式的数据,其内部会存储时间信息,而有些网站下载文件时文件名有没有时间信息。
假如你有如下目录结构:
./RH/ked.nc
./RH/mmm.nc
./RH/dii.nc
./RH/jkd.nc
./RH/zex.nc
./RH/xyz.nc
每个nc文件下都有一个名为time的变量,类型为数组,用于记录时间。以ERA5数据为例,其小时尺度的数据记录的当前时间距格里尼治时间1900-01-01-00:00的小时数,若要将其转为东八区的字符串格式的时间,可以这么做:
import datetime
import netCDF4 as nc
ds = nc.Dataset('./RH/ked.nc')
time = ds['time'][...].data
origin_date = datetime.datetime(1900, 1, 1, 0, 0)
start_date = origin_date+datetime.timedelta(hours=int(times[0])+8)
start_date = start_date.strftime('%Y-%m-%d-%H')
而如果我们不需要对这些nc文件重命名,只是要在代码里对这些文件的路径进行排序,只需要这么做:
from glob import glob
nc_paths = glob(os.path.join('./RH', '*.nc'))
times = []
for nc_path in nc_paths:
# 提取各站点的温度
ds = nc.Dataset(nc_path)
time = ds.variables['time']
times.append(int(time[0].data))
_, nc_paths = (list(t) for t in zip(*sorted(zip(times, nc_paths))))
最后,对文件路径进行操作的可能性有无数种,掌握这些基本知识,学会举一反三,多动手尝试,只有这样在数据处理中才能游刃有余。
总结
到此这篇关于Python文件路径操作的文章就介绍到这了,更多相关Python文件路径操作内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!