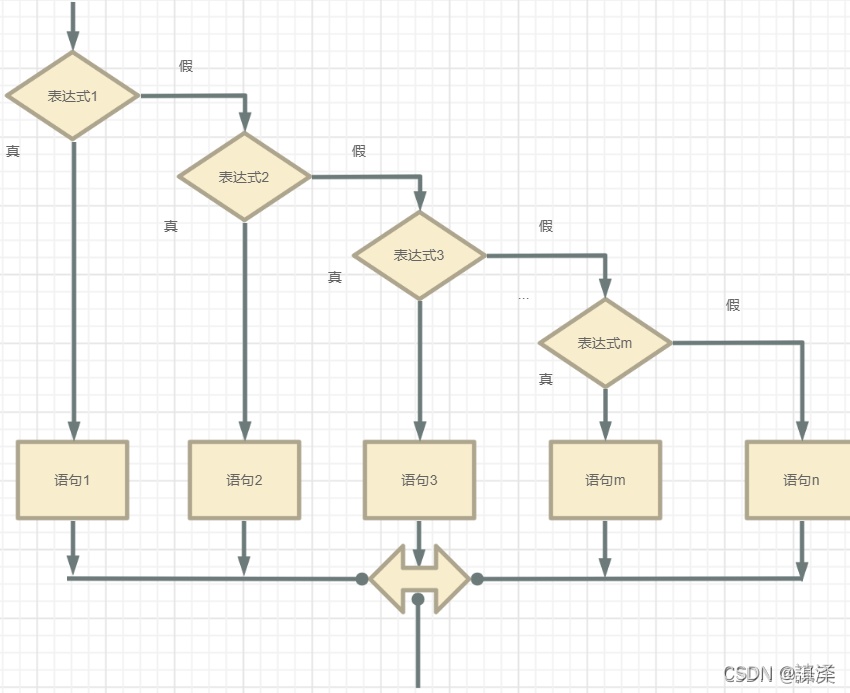
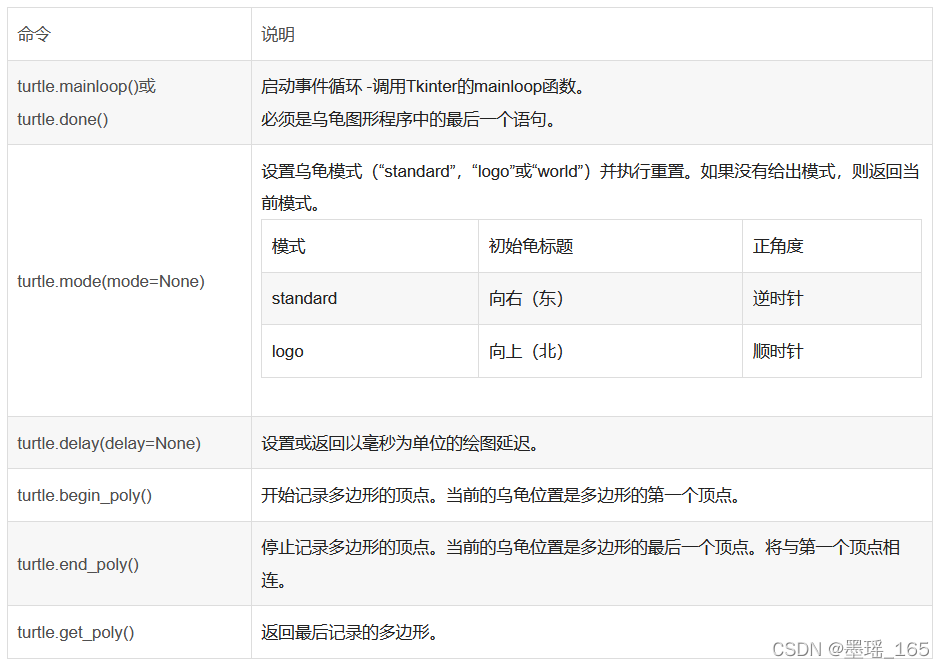
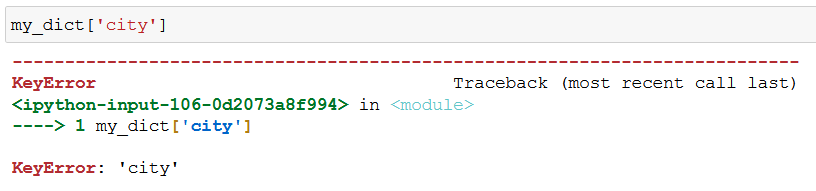
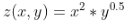python合并文本文件示例代码。
python实现两个文本合并
employee文件中记录了工号和姓名
cat employee.txt:
100 Jason Smith 200 John Doe 300 Sanjay Gupta 400 Ashok Sharma
bonus文件中记录工号和工资
cat bonus.txt:
100 $5,000 200 $500 300 $3,000 400 $1,250
要求把两个文件合并并输出如下, 处理结果:
400 ashok sharma $1,250 100 jason smith $5,000 200 john doe $500 300 sanjay gupta $3,000
这个应该是要求用shell来写的,但我的shell功底不怎么样,就用python来实现了
注意,按题目的意思,在输出文件中还需要按照姓名首字母来排序的
#! /usr/bin/env python
#coding=utf-8
fp01=open("bonus.txt","r")
a=[]
for line01 in fp01:
a.append(line01)
fp02=open("employee.txt","r")
fc02=sorted(fp02,key=lambda x:x.split()[1])
for line02 in fc02:
i=0
while line02.split()[0]!=a[i].split()[0]:
i+=1
print "%s %s %s %s" % (line02.split()[0],line02.split()[1],line02.split()[2],a[i].split()[1])
fp01.close()
fp02.close()
我们再来看一段同样功能的 代码
# coding gbk
#
# author: GreatGhoul
# email : greatghoul@gmail.com
# blog : http://greatghoul.javaeye.com
import sys,os,msvcrt
def join(in_filenames, out_filename):
out_file = open(out_filename, 'w+')
err_files = []
for file in in_filenames:
try:
in_file = open(file, 'r')
out_file.write(in_file.read())
out_file.write('\n\n')
in_file.close()
except IOError:
print 'error joining', file
err_files.append(file)
out_file.close()
print 'joining completed. %d file(s) missed.' % len(err_files)
print 'output file:', out_filename
if len(err_files) > 0:
print 'missed files:'
print '--------------------------------'
for file in err_files:
print file
print '--------------------------------'
if __name__ == '__main__':
print 'scanning...'
in_filenames = []
file_count = 0
for file in os.listdir(sys.path[0]):
if file.lower().endswith('[all].txt'):
os.remove(file)
elif file.lower().endswith('.txt'):
in_filenames.append(file)
file_count = file_count + 1
if len(in_filenames) > 0:
print '--------------------------------'
print '\n'.join(in_filenames)
print '--------------------------------'
print '%d part(s) in total.' % file_count
book_name = raw_input('enter the book name: ')
print 'joining...'
join(in_filenames, book_name + '[ALL].TXT')
else:
print 'nothing found.'
msvcrt.getch()
最后我们再来看一个小编遇到的情况:
今天汇编的时候在阿甘的博客里面看到了一部小说《疯狂的程序员》,于是网上搜了下准备放到手机里闲时看看,无奈下载后发现是分章节的txt文本,一共有87个文件,考虑到阅读起来不是很方便,于是想找个现成的工具合并txt文本。
结果尝试了几个工具后觉得合并效果都不给力啊,于是打算自己动手。其实cmd的命令"type *.txt >> crazy-programmer.txt"还是很有效果的,然而合并后的txt文件却十分庞大,所以我还是自己写了一个脚本完成了合并。
说明:由于我下载的87个txt文件的字符编码格式都不统一,所以我用chardet模块判断字符编码类型后再用codecs模块的codecs.open功能解决了编码问题。如果直接用file的open打开txt文件的话,在UCS-2 Little Endian的编码情况下,file.read()遇到中文的冒号(即“:”)后会无法读取冒号以后的内容,所以需要用codecs.open(path,'r',encoding)来解决。
如果还有问题可以留言,代码如下:
#!coding: cp936
import codecs, chardet
def fileopen(filename):
f = open(filename, 'r')
s = f.read()
if(chardet.detect(s)['encoding'] == 'UTF-16LE'):
f.close()
f = codecs.open(filename, 'r', 'utf-16-le')
data = f.read().encode('gb2312', 'ignore')
f.close()
elif(chardet.detect(s)['encoding'] == 'GB2312'):
data = s
f.close()
return data
i = 1
while i <=87:
if(i < 10):
filename = '0'+str(i)+'.txt'
else:
filename = str(i)+'.txt'
text = fileopen(filename)
file('crazy-p.txt', 'a+').write(text)
i = i+1
其中,chardet模块需要下载安装,脚本还可以改进以适应更多种情况,我就懒了。
本文python实现文本文件合并到此结束。激流勇进者方能领略江河源头的奇观胜景。小编再次感谢大家对我们的支持!