如果您想跟随并尝试示例查询(我们建议这样做,这样更有趣),可以使用来自Kaggle的Wikipedia电影情节数据集执行代码示例。要导入它,请下载CSV文件,然后创建以下表格:
CREATE TABLE movies( ReleaseYear int, Title text, Origin text, Director text, Casting text, Genre text, WikiPage text, Plot text);
并像这样导入 CSV 文件:
\COPY movies(ReleaseYear, Title, Origin, Director, Casting, Genre, WikiPage, Plot) FROM 'wiki_movie_plots_deduped.csv' DELIMITER ',' CSV HEADER;
该数据集包含 34,000 个电影标题,CSV 格式大小约为 81 MB。
PostgreSQL全文搜索原语
PostgreSQL的全文搜索方法提供了一些基础组件,您可以将它们组合起来创建自己的搜索引擎。这种方法非常灵活,但也意味着与Elasticsearch、Typesense或Mellisearch等搜索引擎相比,它通常感觉更低级,因为全文搜索并非主要用例。
主要的基础组件,我们将通过示例进行介绍,包括:
- tsvector和tsquery数据类型
- match运算符@@,用于检查tsquery是否与tsvector匹配
- 用于对每个匹配进行排名的函数(ts_rank、ts_rank_cd)
- GIN索引类型,用于高效查询tsvector的倒排索引
我们将从这些基础组件开始,然后深入研究更高级的主题,包括相关性提升、容错处理和分面搜索。
tsvector
tsvector数据类型存储了一个排序后的词元列表。词元是一个字符串,就像一个标记,但它已被规范化,以便生成不同形式的同一个词。例如,规范化通常包括将大写字母转换为小写字母,并经常涉及去除后缀(例如英语中的s或ing)。下面是一个示例,使用to_tsvector函数将一个英语短语解析为tsvector。
'I''m going to make him an offer he can''t refuse. Refusing is not an option.'));
lexeme | positions | weights
--------+-----------+---------
go | {3} | {D}
m | {2} | {D}
make | {5} | {D}
offer | {8} | {D}
option | {17} | {D}
refus | {12,13} | {D,D}
(6 rows)正如您所见,停用词(例如"I"、"to"或"an")被移除,因为它们在搜索中没有太大用处。这些词被规范化并缩减到它们的词根形式(例如"refuse"和"Refusing"都被转换为"refus")。标点符号被忽略。对于每个词,记录了它在原始短语中的位置(例如"refus"是文本中的第12和第13个词),以及权重(在后面我们将讨论它们在排名中的用途)。
在上面的示例中,词到词元的转换规则是基于英语搜索配置的。使用简单搜索配置运行相同的查询将导致包含所有单词的tsvector,这些单词与文本中找到的单词一致。
'I''m going to make him an offer he can''t refuse. Refusing is not an option.'));
lexeme | positions | weights
----------+-----------+---------
an | {7,16} | {D,D}
can | {10} | {D}
going | {3} | {D}
he | {9} | {D}
him | {6} | {D}
i | {1} | {D}
is | {14} | {D}
m | {2} | {D}
make | {5} | {D}
not | {15} | {D}
offer | {8} | {D}
option | {17} | {D}
refuse | {12} | {D}
refusing | {13} | {D}
t | {11} | {D}
to | {4} | {D}
(16 rows)正如您所见,"refuse"和"refusing"现在生成了不同的词元。简单配置在包含标签或标记的列中非常有用。
PostgreSQL内置了一套相当不错的语言配置。您可以运行以下命令查看列表:
SELECT cfgname FROM pg_ts_config;
值得注意的是,目前没有适用于CJK(中日韩)语言的配置,如果您需要在这些语言中创建搜索查询,这一点值得记住。虽然简单配置在实践中对不支持的语言应该工作得很好,但我不确定对于CJK语言是否足够。
tsquery tsquery数据类型用于表示规范化的查询。tsquery包含搜索术语,这些术语必须是已经规范化的词元,并且可以使用AND、OR、NOT和FOLLOWED BY等运算符组合多个术语。有一些函数(如to_tsquery、plainto_tsquery和websearch_to_tsquery)可帮助将用户编写的文本转换为正确的tsquery,主要是通过对文本中出现的单词进行规范化。
为了对tsquery有所了解,让我们通过websearch_to_tsquery看几个示例:
SELECT websearch_to_tsquery('english', 'the dark vader');
websearch_to_tsquery
----------------------
'dark' & 'vader'这是一个逻辑上的AND,意味着文档需要同时包含“quick”和“dog”才能匹配。您也可以进行逻辑上的OR操作:
SELECT websearch_to_tsquery('english', 'quick OR dog');
websearch_to_tsquery
----------------------
'dark' | 'vader'您还可以排除某些单词:
SELECT websearch_to_tsquery('english', 'dark vader -wars');
websearch_to_tsquery
---------------------------
'dark' & 'vader' & !'war'此外,您还可以表示短语搜索:
SELECT websearch_to_tsquery('english', '"the dark vader son"');
websearch_to_tsquery
------------------------------
'dark' <-> 'vader' <-> 'son'这意味着:“dark”后面是“vader”,然后是“son”。
然而,请注意,“the”一词被忽略了,因为它是根据英文搜索配置的停用词。这可能会在像这样的短语中引发问题:
SELECT websearch_to_tsquery('english', '"do or do not, there is no try"');
websearch_to_tsquery
----------------------
'tri'
(1 row)糟糕,几乎整个短语都消失了。使用简单配置可以得到预期的结果:
SELECT websearch_to_tsquery('simple', '"do or do not, there is no try"');
websearch_to_tsquery
--------------------------------------------------------------------------
'do' <-> 'or' <-> 'do' <-> 'not' <-> 'there' <-> 'is' <-> 'no' <-> 'try'您可以使用匹配操作符@@来检查tsquery是否与tsvector匹配。
SELECT websearch_to_tsquery('english', 'dark vader') @@
to_tsvector('english',
'Dark Vader is my father.');
?column?
----------
t虽然下面的例子不匹配:
SELECT websearch_to_tsquery('english', 'dark vader -father') @@
to_tsvector('english',
'Dark Vader is my father.');
?column?
----------
fGIN
既然我们已经看到了 tsvector 和 tsquery 的工作原理,现在让我们来看另一个关键构建块:GIN 索引类型是使其快速运行的关键。GIN 代表广义倒排索引(Generalized Inverted Index)。GIN 专门用于处理需要对复合值进行索引的情况,以及需要在索引中搜索出现在复合项内的元素值的查询。这意味着 GIN 不仅可以用于文本搜索,还可以用于 JSON 查询等其他用途。
您可以在一组列上创建 GIN 索引,或者您可以首先创建一个 tsvector 类型的列,以包括所有可搜索的列。例如:
ALTER TABLE movies ADD search tsvector GENERATED ALWAYS AS
(to_tsvector('english', Title) || ' ' ||
to_tsvector('english', Plot) || ' ' ||
to_tsvector('simple', Director) || ' ' ||
to_tsvector('simple', Genre) || ' ' ||
to_tsvector('simple', Origin) || ' ' ||
to_tsvector('simple', Casting)
) STORED;然后创建实际的索引:
CREATE INDEX idx_search ON movies USING GIN(search);
现在您可以执行如下简单的搜索测试:
SELECT title FROM movies WHERE search @@ websearch_to_tsquery('english','dark vader');
title
--------------------------------------------------
Star Wars Episode IV: A New Hope (aka Star Wars)
Return of the Jedi
Star Wars: Episode III – Revenge of the Sith
(3 rows)为了看到索引的效果,您可以比较上述查询的计时情况,包括有索引和无索引的情况。在我的计算机上,使用GIN索引的时间从200毫秒左右减少到约4毫秒。
ts_rank
到目前为止,我们已经看到了如何使用ts_vector和ts_query来匹配搜索查询。然而,为了获得良好的搜索体验,重要的是首先显示最佳结果,这意味着结果需要按相关性进行排序。
直接从文档中摘录:
PostgreSQL提供了两个预定义的排名函数,它们考虑了词汇、接近度和结构信息;也就是说,它们考虑查询词在文档中出现的频率、词项在文档中的接近程度以及它们出现的文档部分的重要性。然而,"相关性"的概念是模糊的,并且非常应用程序特定。不同的应用可能需要额外的信息来进行排名,例如文档的修改时间。内置的排名函数只是示例。您可以编写自己的排名函数和/或将它们的结果与其他因素结合起来,以适应您的特定需求。
这两个提到的排名函数是ts_rank和ts_rank_cd。它们之间的区别在于,虽然它们都考虑了词项的频率,但ts_rank_cd还考虑了匹配词项之间的接近程度。
要在查询中使用它们,可以这样做:
SELECT title,
ts_rank(search, websearch_to_tsquery('english', 'dark vader')) rank
FROM movies
WHERE search @@ websearch_to_tsquery('english','dark vader')
ORDER BY rank DESC
LIMIT 10;
title | rank
--------------------------------------------------+------------
Return of the Jedi | 0.21563873
Star Wars: Episode III – Revenge of the Sith | 0.12592985
Star Wars Episode IV: A New Hope (aka Star Wars) | 0.05174401关于ts_rank需要注意的一点是它需要访问每个结果的搜索列。这意味着如果WHERE条件匹配了很多行,PostgreSQL需要访问它们所有以进行排名,这可能会很慢。举个例子,上面的查询在我的计算机上返回时间为5-7毫秒。如果我修改查询以搜索dark OR vader,返回时间约为80毫秒,因为现在有1000多个匹配结果需要进行排名和排序。
相关性调整
尽管基于词频的相关性对于搜索排序来说是一个很好的默认设置,但数据通常包含比简单的频率更重要的指标。
以下是一些电影数据集的示例:
- 标题中的匹配应该比描述或剧情中的匹配更重要。
- 更受欢迎的电影可以根据评级和/或收到的投票数进行推广。
- 考虑到用户偏好,某些类别可以得到更大的提升。例如,如果某个用户喜欢喜剧片,那么这些电影可以优先考虑。
- 在对搜索结果进行排名时,较新的标题可以被认为比非常老的标题更相关。
这就是为什么专用的搜索引擎通常提供使用不同的列或字段来影响排名的方法。这里是来自Elastic、Typesense和Meilisearch的调优示例指南。
数字、日期和精确值增强器
虽然PostgreSQL没有直接支持基于其他列进行提升的功能,但排名实际上只是一个排序表达式,因此您可以向其中添加自定义信号。
例如,如果您想根据投票数量添加提升,可以执行以下操作:
SELECT title,
ts_rank(search, websearch_to_tsquery('english', 'jedi'))
-- numeric booster example
+ log(NumberOfVotes)*0.01
FROM movies
WHERE search @@ websearch_to_tsquery('english','jedi')
ORDER BY rank DESC LIMIT 10;对数函数用于平滑影响,而0.01因子使得提升与排名得分具有可比性。
您还可以设计更复杂的增强器,例如,只有在排名有一定数量的投票时才提升评级。为此,您可以创建以下函数:
create function numericBooster(rating numeric, votes numeric, voteThreshold numeric)
returns numeric as $$
select case when votes < voteThreshold then 0 else rating end;
$$ language sql;然后可以这样使用它:
SELECT title,
ts_rank(search, websearch_to_tsquery('english', 'jedi'))
-- numeric booster example
+ numericBooster(Rating, NumberOfVotes, 100)*0.005
FROM movies
WHERE search @@ websearch_to_tsquery('english','jedi')
ORDER BY rank DESC LIMIT 10;让我们再举一个例子。假设我们想提高喜剧的排名。你可以创建一个类似下面的 valueBooster 函数:
create function valueBooster (col text, val text, factor integer) returns integer as $$ select case when col = val then factor else 0 end;$$ language sql;
如果列的值与特定值匹配,则该函数返回一个因子;否则返回 0。可以像这样在查询中使用它:
SELECT title, genre,
ts_rank(search, websearch_to_tsquery('english', 'jedi'))
-- value booster example
+ valueBooster(Genre, 'comedy', 0.05) rank
FROM movies
WHERE search @@ websearch_to_tsquery('english','jedi') ORDER BY rank DESC LIMIT 10;
title | genre | rank
--------------------------------------------------+------------------------------------+---------------------
The Men Who Stare at Goats | comedy | 0.1107927106320858
Clerks | comedy | 0.1107927106320858
Star Wars: The Clone Wars | animation | 0.09513916820287704
Star Wars: Episode I – The Phantom Menace 3D | sci-fi | 0.09471701085567474
Star Wars: Episode I – The Phantom Menace | space opera | 0.09471701085567474
Star Wars: Episode II – Attack of the Clones | science fiction | 0.09285612404346466
Star Wars: Episode III – Revenge of the Sith | science fiction, action | 0.09285612404346466
Star Wars: The Last Jedi | action, adventure, fantasy, sci-fi | 0.0889768898487091
Return of the Jedi | science fiction | 0.07599088549613953
Star Wars Episode IV: A New Hope (aka Star Wars) | science fiction | 0.07599088549613953
(10 rows)列权重
记得我们谈到过 tsvector 词元可以附带权重吗?PostgreSQL 支持 4 种权重,它们分别是 A、B、C 和 D。A 是最高的权重,而 D 是最低的,默认权重。您可以通过 setweight 函数来控制权重,通常在构建 tsvector 列时调用该函数:
ALTER TABLE movies ADD search tsvector GENERATED ALWAYS AS
(setweight(to_tsvector('english', Title), 'A') || ' ' ||
to_tsvector('english', Plot) || ' ' ||
to_tsvector('simple', Director) || ' ' ||
to_tsvector('simple', Genre) || ' ' ||
to_tsvector('simple', Origin) || ' ' ||
to_tsvector('simple', Casting)
) STORED;让我们看看这个的效果。如果没有使用 setweight,搜索 dark vader OR jedi 的结果是:
SELECT title, ts_rank(search, websearch_to_tsquery('english', 'jedi')) rank
FROM movies
WHERE search @@ websearch_to_tsquery('english','jedi')
ORDER BY rank DESC;
title | rank
--------------------------------------------------+-------------
Star Wars: The Clone Wars | 0.09513917
Star Wars: Episode I – The Phantom Menace | 0.09471701
Star Wars: Episode I – The Phantom Menace 3D | 0.09471701
Star Wars: Episode III – Revenge of the Sith | 0.092856124
Star Wars: Episode II – Attack of the Clones | 0.092856124
Star Wars: The Last Jedi | 0.08897689
Return of the Jedi | 0.075990885
Star Wars Episode IV: A New Hope (aka Star Wars) | 0.075990885
Clerks | 0.06079271
The Empire Strikes Back | 0.06079271
The Men Who Stare at Goats | 0.06079271
How to Deal | 0.06079271
(12 rows)而使用标题列上的 setweight 后,结果为:
SELECT title, ts_rank(search, websearch_to_tsquery('english', 'jedi')) rank
FROM movies
WHERE search @@ websearch_to_tsquery('english','jedi')
ORDER BY rank DESC;
title | rank
--------------------------------------------------+-------------
Star Wars: The Last Jedi | 0.6361112
Return of the Jedi | 0.6231253
Star Wars: The Clone Wars | 0.09513917
Star Wars: Episode I – The Phantom Menace | 0.09471701
Star Wars: Episode I – The Phantom Menace 3D | 0.09471701
Star Wars: Episode III – Revenge of the Sith | 0.092856124
Star Wars: Episode II – Attack of the Clones | 0.092856124
Star Wars Episode IV: A New Hope (aka Star Wars) | 0.075990885
The Empire Strikes Back | 0.06079271
Clerks | 0.06079271
The Men Who Stare at Goats | 0.06079271
How to Deal | 0.06079271
(12 rows)容忍错别字/模糊搜索
PostgreSQL 在使用 tsvector 和 tsquery 时不直接支持模糊搜索或容忍错别字。然而,基于以下假设,我们可以实现以下思路:
- 在单独的表中索引内容中的所有词元
- 对查询中的每个单词,使用相似度或Levenshtein距离在此表中进行搜索
- 修改查询以包括找到的任何单词
- 执行搜索
以下是其工作原理。首先,使用 ts_stats 获取所有单词并存储在一个物化视图中:
CREATE MATERLIAZED VIEW unique_lexeme AS
SELECT word FROM ts_stat('SELECT search FROM movies');现在,对于查询中的每个单词,检查它是否在 unique_lexeme 视图中。如果不存在,则在该视图中进行模糊搜索,以找到可能的拼写错误:
SELECT * FROM unique_lexeme WHERE levenshtein_less_equal(word, 'pregant', 2) < 2; word ---------- premant pregrant pregnant paegant
在上面的代码中,我们使用了Levenshtein距离,因为这是像Elasticsearch这样的搜索引擎在模糊搜索中使用的算法。
一旦你有了候选词列表,你需要调整查询以包含它们所有。
分面搜索
分面搜索在电子商务网站上很受欢迎,特别是因为它帮助客户逐步缩小他们的搜索范围。以下是来自amazon.com的一个示例:
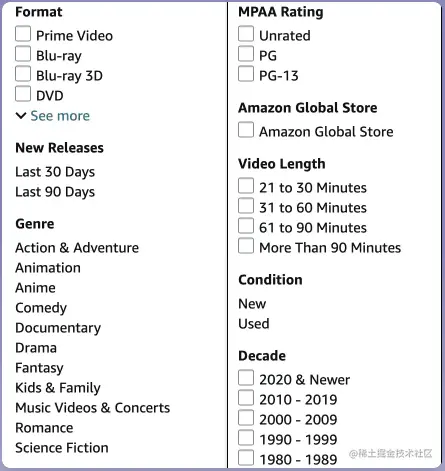
上述方法可以通过手动定义分类并将其作为搜索的 WHERE 条件添加来实现。另一种方法是根据现有数据以算法方式创建分类。例如,您可以使用以下代码创建一个“年代”分面:
SELECT ReleaseYear/10*10 decade, count(Title) cnt FROM movies
WHERE search @@ websearch_to_tsquery('english','star wars')
GROUP BY decade ORDER BY cnt DESC;
decade | cnt
--------+-----
2000 | 39
2010 | 31
1990 | 29
1950 | 28
1940 | 26
1980 | 22
1930 | 13
1960 | 11
1970 | 7
1910 | 3
1920 | 3
(11 rows)这还提供了每个年代的匹配计数,您可以在括号中显示出来。
如果您想在单个查询中获取多个分面,可以将它们组合起来,例如使用公共表表达式(CTEs):
WITH releaseYearFacets AS (
SELECT 'Decade' facet, (ReleaseYear/10*10)::text val, count(Title) cnt
FROM movies
WHERE search @@ websearch_to_tsquery('english','star wars')
GROUP BY val ORDER BY cnt DESC),
genreFacets AS (
SELECT 'Genre' facet, Genre val, count(Title) cnt FROM movies
WHERE search @@ websearch_to_tsquery('english','star wars')
GROUP BY val ORDER BY cnt DESC LIMIT 5)
SELECT * FROM releaseYearFacets UNION SELECT * FROM genreFacets;
facet | val | cnt
--------+---------+-----
Decade | 1910 | 3
Decade | 1920 | 3
Decade | 1930 | 13
Decade | 1940 | 26
Decade | 1950 | 28
Decade | 1960 | 11
Decade | 1970 | 7
Decade | 1980 | 22
Decade | 1990 | 29
Decade | 2000 | 39
Decade | 2010 | 31
Genre | comedy | 21
Genre | drama | 35
Genre | musical | 9
Genre | unknown | 13
Genre | war | 15
(16 rows)上述方法在小到中等规模的数据集上应该能够很好地工作,但在非常大的数据集上可能会变得较慢。
结论
我们已经了解了PostgreSQL的全文搜索基础知识,以及如何将它们组合起来创建一个相当高级的全文搜索引擎,这个引擎还支持诸如连接和ACID事务等功能。换句话说,它具有其他搜索引擎通常没有的功能。
作者:Tudor Golubenco
更多技术干货请关注公号“云原生数据库”
squids.cn,目前可体验全网zui低价云数据库RDS,免费的数据库迁移工具DBMotion、备份工具、SQL开发工具等。
以上就是使用PostgreSQL创建高级搜索引擎的代码示例的详细内容,更多关于PostgreSQL创建高级搜索引擎的资料请关注好代码网其它相关文章!