我就废话不多说了,大家还是直接看代码吧~
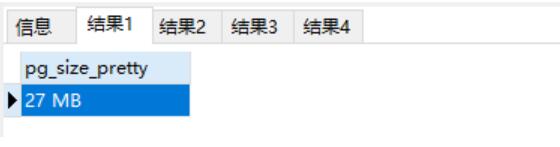
select pg_size_pretty(pg_relation_size('cuiyonghua.top_iqiyi_info'));
select pg_size_pretty(pg_relation_size('cuiyonghua.top_mgtv_info'));
select pg_size_pretty(pg_relation_size('cuiyonghua.top_tencent_info'));
select pg_size_pretty(pg_relation_size('cuiyonghua.top_zhihu_info'));
补充:PostgreSQL 配置内存参数
对于任何数据库软件,内存配置项都是很重要的配置项。在 PostgreSQL 主要有以下几个内存配置参数。
shared_buffers: integer 类型,设置数据库服务器将使用的共享内存缓冲区数量,此缓冲区为缓冲数据块所用。此缓冲区是放在共享内存中的。每个缓冲区大小的典型值是 8K 字节,默认值通常是 4000,对于 8KB 的数据块则共享内存缓冲区大小为 400*8KB=32MB。这个数值必须大于 16,并且至少是 max_connections 数值的两倍。通常都会把此值设置的大一些,这样可以改进性能。一般设置为物理内存的 25%,若把 shared_buffers 设置的更大,如超过物理内存的 40%,就会发现缓冲的效果并不明显了,这是因为 PostgreSQL 是运行文件系统之上的,若文件系统也有缓存,将导致双缓存过多,造成负面影响。
temp_buffers: integer 类型,设置每个数据库会话使用的临时缓冲区的最大数目。此本地缓冲区只用于访问临时表。临时缓冲区是在某个连接会话的服务进程中分配的,属于本地内存。临时缓冲区的大小也是按数据块大小分配的,默认是 1000,对于 8K 的数据块大小为 8MB。
work_mem: integer 类型,声明内部排序操作和 Hash 表在开始使用临时磁盘文件之前可使用的内存数目。这个内存也是本地内存,默认是 1MB。请注意对于复杂的查询,可能会同时并发运行好几个排序或散列(hash)操作;每个排序或散列操作都会分配这个参数声明的内存来存储中间数据,只有存不下才会使用临时文件。同样,好几个正在运行的会话可能会同时进行排序操作,因此使用的总内存量可能是 work_mem 的好几倍。 ORDER BY、DISTINCT 和 MERGE JOINS 都要用到排序操作。Hash 表在以 Hash join、Hash 为基础的聚集、以 Hash 为基础的 IN 子查询处理中都要用到。
maintenance_work_mem: integer 类型,声明在维护性操作(比如 CACUUM、CREATE INDEX、ALTER TABLE ADD FOREIGN KEY等)中使用的最大内存数。默认是 16 MB。在一个数据库会话里,只有一个这样的操作可以执行行,并且一个数据库实例通常不会有太多这样的工作并发执行,把这个数值设置得比 work_mem 大一些通常是合适的。更大的设置可以提高上述操作的速度。
max_stack_depth: integer 类型,声明服务器执行堆栈的最大安全深度。默认值 2MB。如果发现不能运行复杂的函数,可以适当提高此配置的值,不过通常情况下保持默认值就够了。
把 max_stack_depth 参数设置得大于实际的操作系统内核限制值时,意味着一个正在运行的递归函数可能会导致 PostgreSQL 后台服务进程奔溃。在一些操作系统平台上,PG 能够检测出内核限制,这时它将不允许将其设置为一个不安全的值。但PG并不能在所有操作系统的平台都检测它的限制值,所以还是建议设置一个明确的值。
总结:
shared_buffers:共享内存的大小,主要用于共享内存数据块。
work_mem:单个 SQL 执行时,排序、hash join 所使用的内存,SQL 运行完成后,内存就释放了。
shared_buffers 默认值为 32 MB,work_mem 为 1MB,如果你的机器上有足够的内存,可以把这个参数改得大一些,
这样数据库就可以缓存更多的数据块,当读取数据时,就可以从共享内存中读,而不需要再从文件上去读取。
work_mem 设置大一些,会让排序操作快一些。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持好代码网。如有错误或未考虑完全的地方,望不吝赐教。