在互联网上,随处可见的搜索框。背后所用的技术大多数就是全文检索。 在全文检索领域,常见的库/组件有:Lucene、Solr、Sphinx、ElasticSearch等。
简单对比几种全文引擎的区别
- Lucene是一个基于Java开发的全文检索基础包,使用起来繁杂,且默认不支持分布式检索
- Solr是基于Lucene开发的一个搜索工具。抽象度更高,使用更简单,且提供一个控制面板。
- ElasticSearch也是基于Lucene开发的。同样是高度抽象,并提供了一个非常强大的DSL检索功能,可以很方便的检索出数据。
- Solr和ES的区别主要在于:ES有强大的实时检索能力而不怎么掉速,Solr创建索引的同时,检索速度会下降。如果不考虑实时检索,Solr的速度更快。Solr社区更成熟。ES使用更方便更现代化。
- Sphinx是俄罗斯人开发的一个全文检索引擎,使用C++开发。性能比Java开发的es和solr高,但是在社区繁荣度上,比ES和solr差很多。比如中文分词器,sphinx的coreseek插件已经停更了。sphinx有个非常好的地方就是可以作为MySQL插件使用。
环境搭建
随着容器化的发展,我们大部分环境都切换到Docker上了。本篇博文的环境通过Docker搭建。
ES在Docker中搭建
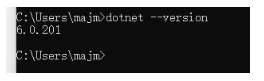
我使用的是ES7.4.2
docker run --name es -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e "ES_JAVA_OPTS=-Xms128m -Xmx128m" -v d:/elasticsearch/es7.4.2/data:/usr/share/elasticsearch/data -v d:/elasticsearch/es7.4.2/plugins:/usr/share/elasticsearch/plugins elasticsearch:7.4.2
我这里把Docker中的es数据目录和插件目录映射到本机,方便操作。实际线上部署也应该映射数据目录到宿主机,防止数据丢失。
搭建Kibana可视化环境
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.31.115:9200 -p 5601:5601 -e "I18N_LOCALE=zh-CN" -d kibana:7.4.2
运行成功后,在Docker控制面板上,就可以看到两个正在运行的容器了。
在本机浏览器访问 http://localhost:5601/ 即可打开Kibana仪表盘。
ElasticSearch基本概念
用数据库的概念来对比ES的概念
| 数据库 | ElasticSearch |
|---|---|
| database 库 | index 索引 |
| table 表 | type 类型 7.x已经废除 |
| row 行 | document 文档 |
| column 列 | field 字段 |
| chema 表结构 | mapping 映射 |
| SQL | DSL |
| select | GET |
| update | PUT |
| delete | delete |
上手ElasticSearch的DSL
ES有两种方式操作:1.url方式,2.http请求中的body提交json dsl
创建一个索引
PUT /qingcheng
删除一个索引
DELETE /qingcheng
创建mapping
PUT /qingcheng
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"createtime": {
"type": "date"
}
}
}
}
响应
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "qingcheng"
}
在ES7中已经不支持映射mapping的时候,指定_doc名称了。ES会给一个默认的_doc名称
新增字段
PUT /qingcheng/_mapping
{
"properties":{
"sex":{
"type":"integer"
}
}
}
在ES中只能新增字段,无法修改已有字段。如果需要需改已有字段,只能重新创建索引,然后使用reindex迁移数据到新的索引。
查看索引
GET /qingcheng/_mapping
结果
{
"qingcheng" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"createtime" : {
"type" : "date"
},
"name" : {
"type" : "text"
},
"sex" : {
"type" : "integer"
}
}
}
}
}
插入以及数据
多次put同一个id到es,那就是更新了
POST /qingcheng/_doc/1
{
"name":"青城",
"age":30,
"createtime":"2021-03-21",
"sex":1
}
使用Post请求,在_doc的type中插入id为1的一条数据。id可以自定义格式,可以为数字以及自定义字符串
查看数据
GET /qingcheng/_doc/1
数据检索的格式为 GET /索引名称/_search + json格式的body
基本搜索
GET /qingcheng/_search
{
"query": {
"query_string": {
"default_field": "name",
"query": "青城"
}
}
}
范围搜索
GET /qingcheng/_search
{
"query": {
"range": {
"age": {
"gte": 10,
"lte": 50
}
}
}
}
分页搜索
GET /qingcheng/_search
{
"query": {
"match": {
"name": "青"
}
},
"from": 0, //从多少条开始
"size": 20 //取多少条
}
排序
GET /qingcheng/_search
{
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
复杂搜索
在ES搜索中,一般会存在多个条件,类似于sql的and or等操作。在ES中使用bool操作来连接多个条件,must 必须满足,should:满足最好,不满足也没关系(如果满足,es的搜索评分会更高,结果更靠前)
GET /qingcheng/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "青"
}
},
{
"range": {
"age": {
"gte": 10,
"lte": 50
}
}
}
],
"should": [
{
"range": {
"age": {
"gte": 10,
"lte": 50
}
}
}
]
}
}
}
聚合
在ES中,聚合使用eggs来操作。可快速求出最大、平均、等值。
GET /qingcheng/_search
{
"aggs": {
"平均值": {
"avg": {
"field": "age"
}
}
}
}
配置中文分词器
ES默认的分词器是中文分词是按单个汉字分割。所以使用起来搜索结果不太准确。在ES的分词插件中,中文分词用的比较多的是IK分词器
github地址:https://github.com/medcl/elasticsearch-analysis-ik
下载好ES对应版本的插件,解压出来,放到ES的插件目录。重启ES,即可启用插件。
我们对比一下使用ES默认分词器和IK分词器的结果
默认分词器
使用IK分词器
IK分词器支持两种分词模式 1. ik_smart 2.ik_max_word
ik_smart模式
ik_max_word
两种分词模式的区别在于分词粒度的粗细问题。而standard分词直接按单个字符分割。
使用.NET Core的NEST客户端
ES的.NET客户端分为两个,一个是ElasticSearch.NET一个是NEST,NEST是高级的客户端库,提供更符合.NET程序员的操作api。ElasticSearch.NET更适合喜欢写DSL的程序员。一般我们都使用NEST。
创建索引
[ElasticsearchType(RelationName = "estest")]
class ESTest
{
[Number(NumberType.Integer, Name = "id")]
public int Id { get; set; }
[Text(Name = "name")]
public string Name { get; set; }
[Number(NumberType.Integer, Name = "age")]
public int Age { get; set; }
[Text(Name = "info", Analyzer = "ik_smart")]
public string Info { get; set; }
[Date(Name = "createtime", Format = "yyyy-MM-dd||yyyy-MM-dd HH:mm:ss")]
public DateTime CreateTime { get; set; }
}
var node = new Uri("http://localhost:9200");
var settings = new ConnectionSettings(node);
var client = new ElasticClient(settings);
//创建索引
var resp = client.Indices.Create("test", opt =>
{
return opt.Map<ESTest>(m => m.AutoMap());
});
Console.WriteLine("创建索引结果:" + resp.Acknowledged);
Console.WriteLine(resp.DebugInformation);
插入数据
var model = new ESTest()
{
Name = "青城1",
Age = 20,
Info = "顺其自然,不代表我们可以不努力,而是努力之后有勇气接受成败。",
Id = 2,
CreateTime = DateTime.Now
};
var indexResp = client.Index(model, i => i.Index("test"));
if (indexResp.IsValid)
{
}
检索数据
var res = client.Search<ESTest>(a => a.Index("test")
.Query(a =>
a.Match(m =>
m.Field(f => f.Info).Query("顺其自然"))));
foreach (var item in res.Documents)
{
Console.WriteLine(item.Name + " " + item.Info);
}
检索数据的写法基本上和DSL语法结构一致。学会DSL,用C#也可以写出正确的查询语句。
学会以上的基本操作,就可以算是对ES有一个基本的了解了。更多深入的知识点可以去ES官方文档学习。
NEST库地址:https://github.com/elastic/elasticsearch-net
官方文档:https://www.elastic.co/guide/en/elasticsearch/client/net-api/current/introduction.html
到此这篇关于时间轻松学会.NET Core操作ElasticSearch7的方法的文章就介绍到这了,更多相关.NET Core操作ElasticSearch 7内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!