1 分布式的三种模式 2 Hadoop集群的运行模式Hadoop的运行模式分为3种:
本地运行模式(独立模式,单机模式),
伪分布运行模式,
集群运行模式(完全
1.分布式的三种模式

2.Hadoop集群的运行模式
Hadoop的运行模式分为3种:
本地运行模式(独立模式,单机模式),
伪分布运行模式,
集群运行模式(完全分布式模式)
伪分布模式就是在一台服务器上面模拟集群环境,但仅仅是机器数量少,其通信机制与运行过程与真正的集群模式是一样的,hadoop的伪分布运行模式可以看做是集群运行模式的特殊情况。
3.cloudera提供哪几种安装CDH方法
· Cloudera manager
· Tarball
· Yum
· Rpm
其中Yum及Rpm安装可以算作一种安装方式
4.Hadoop的模块有哪些

5.Zookeeper的作用

6.Shuffle在MapReduce指的是什么?

7. resourceManager在YARN中的作用

8. 将打好的jar包,提交给YARA运行,请写出命令

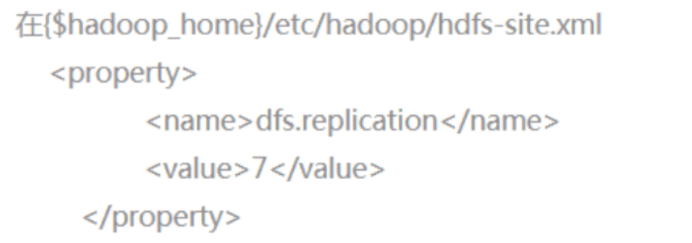
9. 在完全分布式中,将副本数设置为7,在哪个配置文件中,如何配置
10. 如何确定map个数

11. MapReduce在hadoop中的作用

12. MapReduce分为哪两个阶段

13. Hadoop的序列化接口是什么

14. 自定义的MapReduce如何向yarn提交运行

15. 自定义MapReduce的模型

16. 简述HDFS的作用

17. 在HDFS的主从架构中,谁是“主”

18. 简述namenode和DataNode的区别及关系

19. 如何将用户hadoop家目录下的1.log,上传到HDFS的 /input目录下,请写出命令

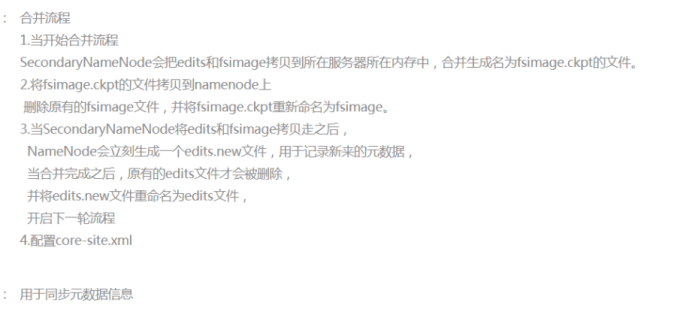
20. 请回答secondaryNameNode在HDFS的作用
21. 把下面的语句用hive方式实现


22. Hive的特点是什么?Hive和rdbms的异同?

23. metastore是什么

24. Hive有哪些方式保存数据,各有哪些特点

25. Hive的本质是什么

====================================================================
1. 搭建伪分布式hadoop开发环境
1、Linux环境
2、Jdk安装
3、 关闭防火墙
4、配置hadoop
5、格式化namenode(不需要重复)
6、启动hdfs 守护进程
7、Web 访问界面 50070
8、配置YARN任务调度
9、启动hdfs YARA进程
10、检查YARN状态
11、向YARN提交任务
2. 编写代码测试HDFS API


3. 编写MapReduce程序,实现wordcount的功能




4. 实现编程测试数据的统计




5. 搭建hadoop完全分布式简单步骤
1、虚拟机装备
2、网络配置完好
3、JDK安装
4、Ssh 配置
5、同步服务器时间
6、Hadoop集群配置
A:环境变量
B:hadoop文件配置,修改
7、启动hadoop集群
8、Web端口访问。
6. 编写MR统计分省PV及脏数据




7. hive的安装和使用

8. Hive架构,分三个部分来讲解,最好通过画图理解


9. 为什么说hive是hadoop的数据仓库,从【数据存储和分析】方面理解

10. Hive能做什么,与MapReduce相比较优势在哪(对于开发者)