Linux awk命令基本使用
awk命令是一种处理文本的语言,是一个强大的文本分析工具,比较适用于文本的格式化。awk命令结构:
awk BEGIN{com
Linux awk命令基本使用
awk命令是一种处理文本的语言,是一个强大的文本分析工具,比较适用于文本的格式化。awk命令结构:
awk 'BEGIN{commands} pattern{command} END{command}'awk工作流程可以分为三个部分:
- 读取输入文件之前执行的代码段(由BEGIN关键字标识)
- 主循环执行输入文件的代码段
- 读取输入文件之后的代码段(由END关键字 标识)
基本用法
用法一:
awk '{[pattern] action}' {filename}
#行匹配语句 awk ' '这里只能用单引号。实例:
1、创建一个测试文本文件如下;

2、输出test1.txt第一列、第三列和第四列,并且按空格分隔;
awk '{print $1,$3,$4}' test1.txt
格式化输出,列对齐;
awk '{printf "%-5s %-5s\n",$3,$4}' test1.txt
#这里%-5s的数字可以更改用来调整列之间的间隔
用法二:
awk -F #这里的-F相当于内置变量FS,指定分割字符
awk -F, '{print $1,$2,$3}' test1.txt
#将文本中的逗号替换成空格,进行分割
awk 'BEGIN{FS=","}{print $1,$2,$3}' test1.txt
#相当于内置变量FS
awk -F '[ ,]' '{print $1,$2,$3}' test1.txt
#使用多个分隔符,先使用空格分割,然后对分割结果在使用都好分割用法三:
awk -v #设置变量
awk -va=1 '{print $1,$1+a}' test1.txt
awk -vb=s '{print $1,$1b}' test1.txt
用法四:
awk -f {awk脚本} {filename}awk -f cal.awk test1.txt
使用运算符
用法五:
awk '$1>2 {print $0}' test1.txt
#输出第一列大于2的行
awk '$1==3 {print $0}' test1.txt
#输出第一列等于3的行
awk '$1>2 && $2=="carl"{print $0}' test1.txt
#输出第一列大于2,第二列等于carl的行
使用内置变量:
内置变量有如下多种:
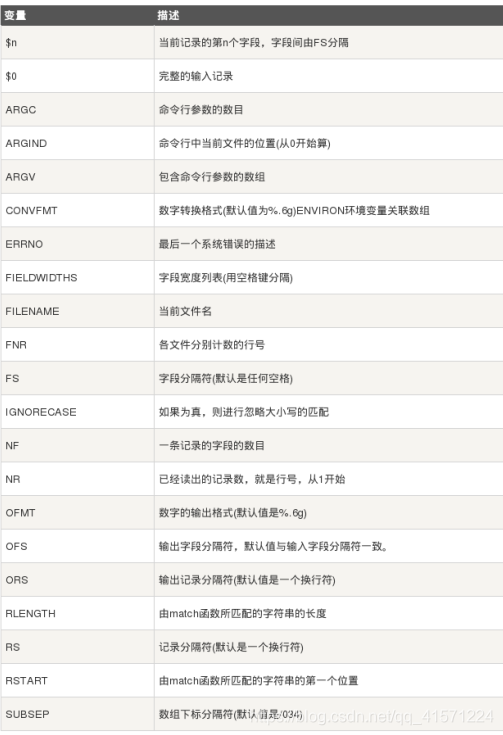
awk '{print NR,FNR,$3}' test1.txt
#输出顺序号NR,匹配文本行号;
指定输出分割符OFS:
awk '{print $1,$2,$3,$4}' OFS="," test1.txt
使用正则,进行字符串匹配
awk '$3~/a/ {print $0}' test1.txt
#输出第三列包含a的所有行,~表示模式开始,//中是模式
awk '/a/' test1.txt
#输出包含a的行
忽略匹配字符的大小写:
awk 'BEGIN{IGNORECASE=1} /a/' test1.txt
#即可以匹配包含A 或 a的行模式取反:
awk '$3!~/a/ {print $0}' test1.txt
#输出第三列不包含a的所有行,~表示模式开始,//中是模式
awk '!/a/' test1.txt
#输出不包含a的行
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持好代码网。