java微服务面试题
Q:为什么要用微服务?微服务有哪些优势?
单体应用把所有功能都堆放在一起,改动影响大,风险高。
微服务具有以下优势:
针对特定服务发布,影响小,风险小,成本低。
频繁发布版本,快速交付需求。
低成本扩容,弹性伸缩,适应云环境。
Q:怎么解决服务调用闭环(循环依赖)?
服务分层,设定groupId。比如分为上层服务,中间层服务,底层服务。
上层服务可以调用中间层、底层服务,底层服务不允许调用上层服务。
Q:如何拆分微服务?
按功能模块拆分。按DDD(领域驱动设计)拆分。
Q:你们的服务划分了几个模块?分别是哪些模块?
十几个模块。
DDD面试题
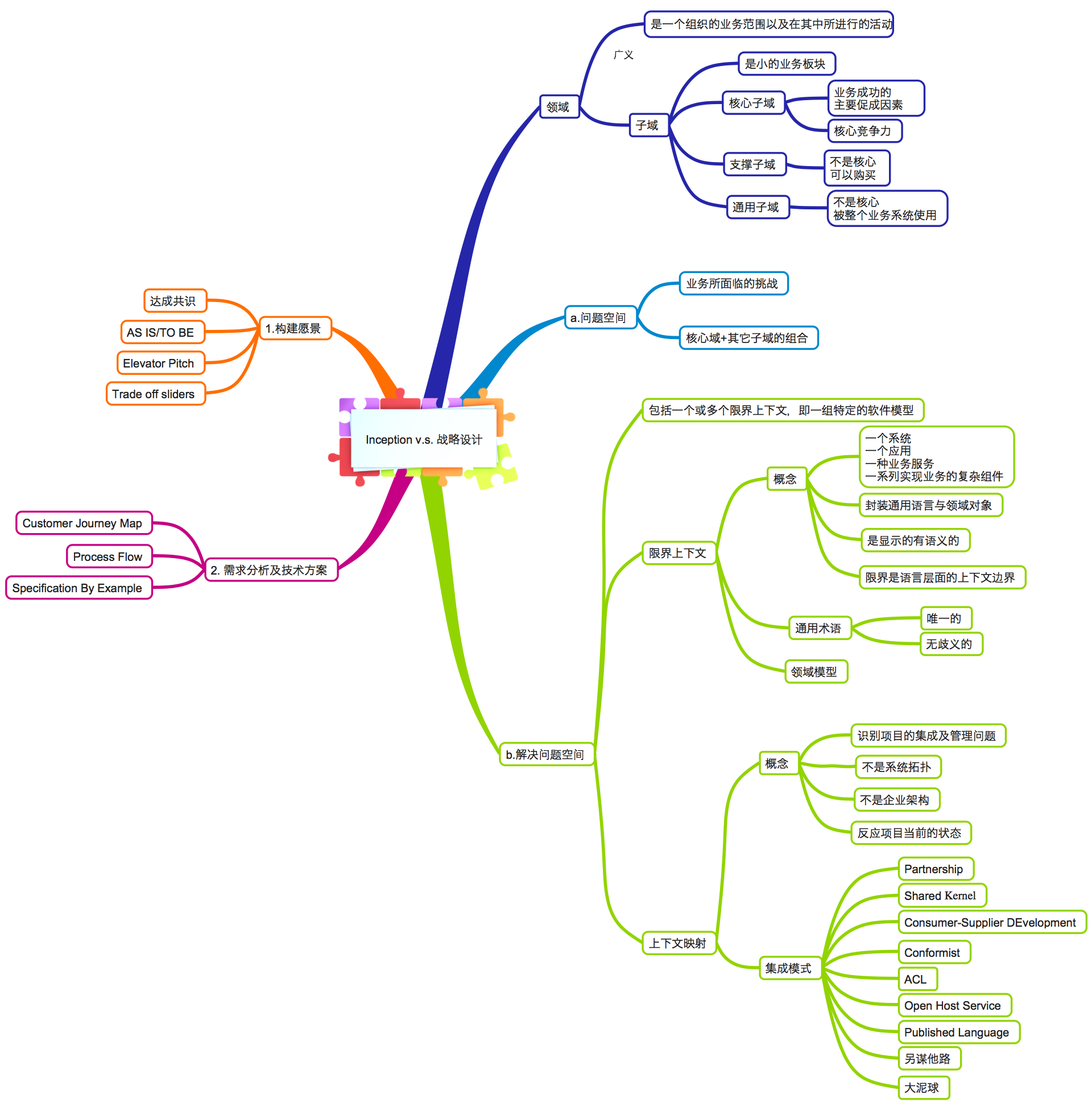
Q:DDD的聚合根,实体,值对象的区别和联系是什么?
参见: https://www.cnblogs.com/netfocus/p/5145345.html
Rpc面试题
Q:RPC和Restful分别有哪些优劣性?
RPC协议性能要高的多,吞吐量比http大。响应也更快。
RPC常见的序列化协议包括json、xml、hession、protobuf、thrift、text、bytes等;
Restful使用http协议。http相对更规范,更标准,更通用,无论哪种语言都支持http协议
Q:为什么Rpc的性能比RestFul好一些?
RESTful是基于HTTP协议进行交互的,HTTP协议包含大量的请求头、响应头信息。
而Rpc(比如dubbo)是基于(dubbo)自定义的二进制协议进行传输,基于TCP长连接,消息体比较简单,传输数据要小很多。
Q:如果想实现一个Rpc框架,需要考虑哪些东西?
动态代理、反射、序列化、反序列化、网络通信(netty)、编解码、服务发现和注册、心跳与链路检测。
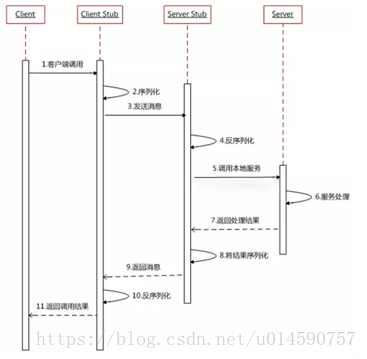
参考资料:https://www.cnblogs.com/flzs/p/12174686.html
Q:服务端如何确定客户端要调用的函数?
在远程调用中,客户端和服务端分别维护一个【ID->函数】的对应表, ID在所有进程中都是唯一确定的。客户端在做远程过程调用时,附上这个ID,服务端通过查表,来确定客户端需要调用的函数,然后执行相应函数的代码。(如果自己去设计一个RPC,可以使用一个Map去保存这些键值对)
Q:讲一下Rpc的整个过程。
两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。
比如说,A服务器想调用B服务器上的一个方法:
1、建立通信
首先要解决通讯的问题:即A机器想要调用B机器,首先得建立起通信连接。
主要是通过在客户端和服务器之间建立TCP连接,远程过程调用的所有交换的数据都在这个连接里传输。连接可以是按需连接,调用结束后就断掉,也可以是长连接,多个远程过程调用共享同一个连接。
通常这个连接可以是按需连接(需要调用的时候就先建立连接,调用结束后就立马断掉),也可以是长连接(客户端和服务器建立起连接之后保持长期持有,不管此时有无数据包的发送,可以配合心跳检测机制定期检测建立的连接是否存活有效),多个远程过程调用共享同一个连接。
2、服务寻址
要解决寻址的问题,也就是说,A服务器上的应用怎么告诉底层的RPC框架,如何连接到B服务器(如主机或IP地址)以及特定的端口,方法的名称名称是什么。
通常情况下我们需要提供B机器(主机名或IP地址)以及特定的端口,然后指定调用的方法或者函数的名称以及入参出参等信息,这样才能完成服务的一个调用。
可靠的寻址方式(主要是提供服务的发现)是RPC的实现基石,比如可以采用Zookeeper来注册服务等等。
2.1、从服务提供者的角度看:
当服务提供者启动的时候,需要将自己提供的服务注册到指定的注册中心,以便服务消费者能够通过服务注册中心进行查找;
当服务提供者由于各种原因致使提供的服务停止时,需要向注册中心注销停止的服务;
服务的提供者需要定期向服务注册中心发送心跳检测,服务注册中心如果一段时间未收到来自服务提供者的心跳后,认为该服务提供者已经停止服务,则将该服务从注册中心上去掉。
2.2、从调用者的角度看:
服务的调用者启动的时候根据自己订阅的服务向服务注册中心查找服务提供者的地址等信息;
当服务调用者消费的服务上线或者下线的时候,注册中心会告知该服务的调用者;服务调用者下线的时候,则取消订阅。
3、网络传输
3.1、序列化
当A机器上的应用发起一个RPC调用时,调用方法和其入参等信息需要通过底层的网络协议如TCP传输到B机器,由于网络协议是基于二进制的,所有我们传输的参数数据都需要先进行序列化(Serialize)或者编组(marshal)成二进制的形式才能在网络中进行传输。然后通过寻址操作和网络传输将序列化或者编组之后的二进制数据发送给B机器。
3.2、反序列化
当B机器接收到A机器的应用发来的请求之后,又需要对接收到的参数等信息进行反序列化操作(序列化的逆操作),即将二进制信息恢复为内存中的表达方式,然后再找到对应的方法(寻址的一部分)进行本地调用(一般是通过生成代理Proxy去调用, 通常会有JDK动态代理、CGLIB动态代理、Javassist生成字节码技术等),之后得到调用的返回值。
4、服务调用
B机器进行本地调用(通过代理Proxy和反射调用)之后得到了返回值,此时还需要再把返回值发送回A机器,同样也需要经过序列化操作,然后再经过网络传输将二进制数据发送回A机器,而当A机器接收到这些返回值之后,则再次进行反序列化操作,恢复为内存中的表达方式,最后再交给A机器上的应用进行相关处理(一般是业务逻辑处理操作)。
通常,经过以上四个步骤之后,一次完整的RPC调用算是完成了,另外可能因为网络抖动等原因需要重试等。
详情见: https://blog.csdn.net/m0_48795607/article/details/116237861
Dubbo面试题
想了解Dubbo,可以多看一下Dubbo的官方文档。
官方文档地址: https://dubbo.apache.org/zh/docs/introduction/
Q:讲一下Dubbo
0.服务容器负责启动,加载,运行服务提供者。
1.服务提供者在启动时,向注册中心注册自己提供的服务。
2.服务消费者在启动时,向注册中心订阅自己所需的服务。
3.注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
4.服务消费者,从提供者地址列表中,基于负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
5.服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
Q:讲一下Dubbo的分层架构图。
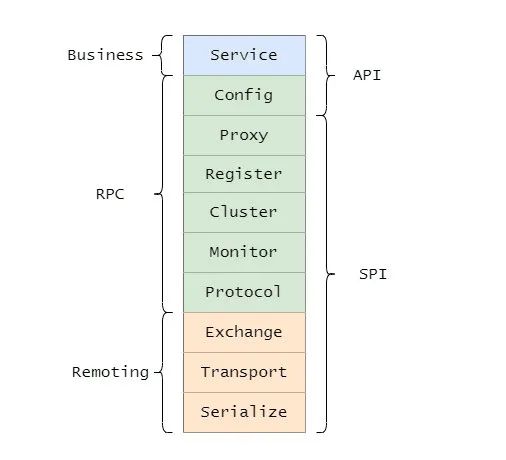
官网地址: https://dubbo.apache.org/zh/docs3-v2/java-sdk/concepts-and-architecture/code-architecture/
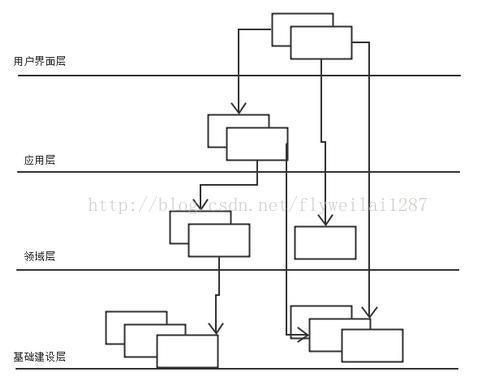
Dubbo大的三层分别为 Business(业务层)、RPC 层、Remoting,并且还分为 API 层和 SPI 层。
Dubbo的整体设计分 10 层:
接口服务层(Service):该层与业务逻辑相关,根据provider和consumer的业务设计对应的接口和实现
配置层(Config):对外配置接口,以ServiceConfig和ReferenceConfig为中心服务
代理层(Proxy):服务接口透明代理,生成服务的客户端Stub 和服务端的Skeleton,以ServiceProxy 为中心,扩展接口为ProxyFactory。
服务注册层(Registry):封装服务地址的注册和发现,以服务URL为中心,扩展接口为RegistryFactory、Registry、RegistryService。
路由层(Cluster):封装多个提供者的路由和负载均衡,并桥接注册中心,以Invoker为中心,扩展接口为Cluster、Directory、Router和LoadBlancce。
监控层(Monitor):RPC调用次数和调用时间监控,以Statistics 为中心,扩展接口为MonitorFactory、Monitor和 MonitorService。
远程调用层(Protocal):封装RPC调用,以Invocation和Result为中心,扩展接口为Protocal、Invoker和Exporter。
信息交换层(Exchange):封装请求响应模式,同步转异步。以 Request和Response为中心,扩展接口为Exchanger、
ExchangeChannel、ExchangeClient和ExchangeServer。
网络传输层(Transport):抽象mina和 netty 为统一接口,以 Message为中心,扩展接口为Channel、Transporter、Client、Server和Codec。
数据序列化层(Serialize):可复用的一些工具,扩展接口为Serialization、ObjectInput、ObjectOutput和ThreadPool。
Dubbo的服务治理
Q:Dubbo的服务提供者、服务消费者需要配置哪些信息?
服务提供者需要配置ip、端口、Dubbo协议、注册中心地址等
Q:Dubbo Consumer(服务消费者)每次调用服务都要去查一次注册中心么?
可以在消费端会进行缓存;通过配置缓存文件的路径开启。
<dubbo:registry id="zookeeper" address="zookeeper://192.*.*.*:2181" file="d:/dubbo-server" />
Q:Dubbo可以对结果进行缓存吗?
为了提高数据访问的速度。Dubbo提供了声明式缓存,以减少用户加缓存的工作量<dubbo:reference cache=“true” />
其实比普通的配置文件就多了一个标签 cache=“true”。
Q:Dubbo的注册中心集群挂掉,发布者和订阅者之间还能通信么?
可以通讯。启动Dubbo 时,消费者会从Zookeeper拉取注册的生产者的地址接口等数据,缓存在本地。每次调用时,按照本地存储的地址进行调用。
注册中心对等集群,任意一台宕机后,将会切换到另一台;注册中心全部宕机后,服务的提供者和消费者仍能通过本地缓存通讯。
服务提供者无状态,任一台宕机后,不影响使用;服务提供者全部宕机,服务消费者会无法使用,并无限次重连等待服务者恢复;
Q:Dubbo服务调用是阻塞的吗?
默认是阻塞的,可以异步调用,没有返回值的可以这么做。
Dubbo是基于NIO的非阻塞实现并行调用,客户端不需要启动多线程即可完成并行调用多个远程服务,相对多线程开销较小,异步调用会返回一个Future对象。
Q:Dubbo异步调用的原理是什么?
在 Dubbo 中发起异步调用。从 2.7.0 开始,Dubbo 的所有异步编程接口开始以 CompletableFuture 为基础
基于 NIO 的非阻塞实现并行调用,客户端不需要启动多线程即可完成并行调用多个远程服务,相对多线程开销较小。
服务消费者调用服务提供者:
//调用服务
asyncService.sayHello("world");
// 拿到调用的Future引用,当结果返回后,会被通知和设置到此Future
CompletableFuture<String> future = RpcContext.getContext().getCompletableFuture();
// 为Future添加回调
future.whenComplete((retValue, exception) -> {
if (exception == null) {
System.out.println(retValue);
} else {
exception.printStackTrace();
}
});
异步调用的官网地址: https://dubbo.apache.org/zh/docs/v2.7/user/examples/async-call/
Q:Dubbo服务调用超时了,会怎么样?
重试,可以设置超时的时间,以及设置重试的次数。
<!-- 延迟到Spring初始化完成后,再暴露服务,服务调用超时设置为6秒,超时重试3次-->
<dubbo:provider delay="-1" timeout="6000" retries="3"/>
Q:Dubbo 超时时间怎样设置?
Dubbo 超时时间设置有两种方式:
- 服务提供者端设置超时时间,在 Dubbo 的用户文档中,推荐如果能在服务端多配置就尽量多配置,因为服务提供者比消费者更清楚自己提供的服务特性。
- 服务消费者端设置超时时间,如果在消费者端设置了超时时间,以消费者端为主,即优先级更高。因为服务调用方设置超时时间控制性更灵活。如果消费方超时,服务端线程不会定制,会产生警告。
Q:dubbo线程池满了怎么办?
dubbo的线程池有多种类型:
fixed:包含固定个数线程
cached:不限制线程个数,线程空闲一分钟会被回收,当新请求到来时会创建新线程
limited:线程个数随着任务增加而增加,但不会超过最大阈值。空闲线程不会被回收
eager:当所有核心线程数都处于忙碌状态时,优先创建新线程执行任务,而不是立即放入队列。
dubbo默认的线程池配置:
<dubbo:protocol name="dubbo" dispatcher="all" threadpool="fixed" threads="200" />
线程池打满了,可以先改成 cached 类型的线程池。并提高支持的threads线程数。(存疑)
线程池打满的问题排查:
线程池打满后,拒绝策略会输出线程快照文件以保护现场,在分析线程快照文件时BLOCKED和TIMED_WAITING线程状态需要我们重点关注。如果发现大量线程阻塞或者等待状态则可以定位到具体代码行。
详情见: https://blog.csdn.net/woshixuye/article/details/115797017
Q:Dubbo使用过程中都遇到了些什么问题?
(1)在注册中心找不到对应的服务,检查service实现类是否添加了@service注解或者xml配置,
检查下dubbo的服务提供者、消费者,是否配置了接口。
如果服务暴露时和服务订阅时使用了 group 和 version 配置,
要确认服务方provider 和消费方consumer 之间的group/version要对应得上,
如果没有对应上,也会报 RpcException 这个错误。
详情见: https://www.cnblogs.com/expiator/p/16496244.html
(2)无法连接到注册中心,检查配置文件中的对应的ip、端口,是否正确。
Q:服务上线怎么兼容旧版本?
可以用版本号(version)过渡,多个不同版本的服务注册到注册中心,版本号不同的服务相互间不引用。
Q:Dubbo的集群容错模式,有哪些?
默认的容错方案是Failover Cluster。
| 集群容错模式(策略) | 特性 | 缺点 |
|---|---|---|
| Failover Cluster(失败自动切换) | 当出现失败,重试其它服务器,通常用于读操作(推荐使用) | 重试会带来更长延迟 |
| Failfast Cluster(快速失败) | 只发起一次调用,失败立即报错,通常用于非幂等性的写操作 | 如果有机器正在重启,可能会出现调用失败 |
| Failsafe Cluster(失败安全) | 出现异常时,直接忽略,通常用于写入审计日志等操作 | 调用信息丢失 |
| Failback Cluster(失败自动恢复) | 后台记录失败请求,定时重发,通常用于消息通知操作 | 不可靠,重启丢失 |
| Forking Cluster(并行调用多个服务器) | 只要一个成功即返回,通常用于实时性要求较高的读操作 | 需要浪费更多服务资源 |
| Broadcast Cluster(广播调用所有提供者) | 逐个调用,任意一台报错则报错,通常用于更新提供方本地状态 | 速度慢,任意一台报错则报错 |
Q:Dubbo有哪些负载均衡策略?
随机调用法、轮询法、最少活跃调用数、一致性Hash均衡算法。
(1)Random LoadBalance:随机,按权重设置随机概率(推荐使用)
缺陷:在一个截面上碰撞的概率高,重试时,可能出现瞬间压力不均
推荐使用的原因:在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
(2)RoundRobin LoadBalance:轮询,按公约后的权重设置轮询比率
缺陷:存在慢的机器累积请求问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
极端情况可能产生雪崩。
(3)LeastActive LoadBalance:最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差,使慢的机器收到更少请求
缺陷:不支持权重,在容量规划时,不能通过权重把压力导向一台机器压测容量
(4)ConsistentHash LoadBalance:一致性Hash,相同参数的请求总是发到同一提供者,当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动
缺陷:压力分摊不均
Q:Dubbo SPI和Java SPI区别?
答:JDK SPI:
JDK标准的SPI会一次性加载所有的扩展实现,如果有的扩展吃实话很耗时,但也没用上,很浪费资源。
所以只希望加载某个的实现,就不现实了。
DUBBO SPI:
1,对 Dubbo进行扩展,不需要改动Dubbo的源码
2,延迟加载,可以一次只加载自己想要加载的扩展实现。
3,增加了对扩展点IOC和AOP的支持,一个扩展点可以直接setter注入其它扩展点。
4,Dubbo的扩展机制能很好的支持第三方IoC容器,默认支持Spring Bean。
Q:Dubbo支持哪些协议?
Dubbo支持Dubbo、rmi、hessian、http、webservice、thrift、Redis等多种协议。
默认协议:Dubbo协议。
Dubbo:单一长连接和NIO异步通讯,适合大并发小数据量的服务调用,以及消费者远大于提供者。传输协议TCP,异步 Hessian序列化。Dubbo推荐使用Dubbo协议。
RMI: 采用JDK标准的RMI协议实现,传输参数和返回参数对象需要实现 Serializable 接口,使用 Java 标准序列化机制,使用阻塞式短连接,传输数据包大小混合,消费者和提供者个数差不多,可传文件,传输协议TCP。 多个短连接 TCP协议传输,同步传输,适用常规的远程服务调用和RMI互操作。在依赖低版本的Common-Collections 包,Java 序列化存在安全漏洞。
WebService:基于WebService的远程调用协议,集成CXF实现,提供和原生WebService的互操作。多个短连接,基于 HTTP 传输,同步传输,适用系统集成和跨语言调用。
HTTP: 基于 Http 表单提交的远程调用协议,使用Spring的HttpInvoke 实现。多个短连接,传输协议HTTP,传入参数大小混合,提供者个数多于消费者,需要给应用程序和浏览器JS调用。
Hessian:集成 Hessian 服务,基于 HTTP 通讯,采用 Servlet暴露服务,Dubbo 内嵌 Jetty 作为服务器时默认实现,提供与 Hession 服务互操作。多个短连接,同步 HTTP 传输,Hessian 序列化,传入参数较大,提供者大于消费者,提供者压力较大,可传文件。
Memcache:基于Memcache实现的RPC协议。
Redis:基于Redis实现的RPC协议。
Q:Dubbo的序列化有哪些方式?
hession、Duddo、Json、java序列化
Q:Dubbo协议有什么特点?
连接个数:单连接
连接方式:长连接
传输协议:TCP
传输方式:NIO 异步传输
序列化:Hessian 二进制序列化
适用范围:传入传出参数数据包较小(建议小于100K),消费者比提供者个数多,单一消费者无法压满提供者,
尽量不要用 dubbo 协议传输大文件或超大字符串。
适用场景:常规远程服务方法调用
Q:dubbo 通信协议 dubbo 协议为什么采用异步单一长连接?
因为服务的现状大都是服务提供者少,通常只有几台机器,
而服务的消费者多,可能整个网站都在访问该服务,
比如 Morgan 的提供者只有 6 台提供者,却有上百台消费者,每天有 1.5 亿次调用,
如果采用常规的 hessian 服务,服务提供者很容易就被压跨,
通过单一连接,保证单一消费者不会压死提供者,
长连接,减少连接握手验证等,
并使用异步 IO,复用线程池。
-- 参考自:《Dubbo面试专题及答案》
Q:Dubbo Monitor实现原理?
(1)Consumer端在发起调用之前会先走 filter 链;provider端在接收到请求时也是先走filter链,然后才进行真正的业务逻辑处理。默认情况下,在consumer和provider的filter链中都会有Monitorfilter。
MonitorFilter向DubboMonitor发送数据。
(2)DubboMonitor将数据进行聚合后(默认聚合 1min 中的统计数据)暂存到ConcurrentMap<Statistics, AtomicReference> statisticsMap,然后使用一个含有3个线程(线程名字:DubboMonitorSendTimer)的线程池每隔 1min 钟,调用SimpleMonitorService遍历发送statisticsMap中的统计数据,每发送完毕一个,就重置当前的 Statistics 的AtomicReference。
(3)SimpleMonitorService 将这些聚合数据塞入BlockingQueue queue中(队列大写为 100000)
(4)SimpleMonitorService 使用一个后台线程(线程名为:DubboMonitorAsyncWriteLogThread) 将queue中的数据写入文件(该线程以死循环的形式来写)
(5)SimpleMonitorService 还会使用一个含有1个线程(线程名字:DubboMonitorTimer)的线程池每隔5min钟,将文件中的统计数据画成图表
Q:Dubbo和SpringCloud有哪些区别?
Dubbo是Soa(面向服务的架构),SpringCloud是微服务架构,除了服务,还有注册中心、熔断、配置中心。
Dubbo基于Rpc(远程过程调用),SpringCloud基于restFul,基于http协议。
最大的区别: Dubbo 底层是使用 Netty 这样的 NIO 框架,是基于TCP 协议传输的,配合序列化完成 RPC 通信。
而 SpringCloud 是基于 Http 协议+Rest 接口调用通信,相对来说, Http 请求会有更大的报文,占的带宽也会更多。
Q:讲一下Dubbo的SPI机制。
Q:你们用的是哪个版本的Dubbo?
Q:Dubbo配置文件是如何加载到Spring中的?
Spring容器在启动的时候,会读取到Spring默认的一些schema以及Dubbo自定义的schema,每个schema都会对应一个自己的NamespaceHandler,NamespaceHandler里面通过BeanDefinitionParser来解析配置信息并转化为需要加载的 bean 对象。
Q:Dubbo用到哪些设计模式?
Dubbo框架在初始化和通信过程中使用了多种设计模式,可灵活控制类加载、权限控制等功能。
(1)工厂模式:
Provider在export服务时,会调用ServiceConfig的export方法。ServiceConfig中有个字段:
private static final Protocol protocol = ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();
Dubbo里有很多这种代码。这也是一种工厂模式,只是实现类的获取采用了JDKSPI的机制。这么实现的优点是可扩展性强,想要扩展实现,只需要在classpath下增加个文件就可以了,代码零侵入。另外,像上面的Adaptive实现,可以做到调用时动态决定调用哪个实现,但是由于这种实现采用了动态代理,会造成代码调试比较麻烦,需要分析出实际调用的实现类。
(2)装饰器模式:
Dubbo在启动和调用阶段都大量使用了装饰器模式。以 Provider提供的调用链为例,具体的调用链代码是在ProtocolFilterWrapper 的buildInvokerChain完成的,具体是将注解中含有group=provider的Filter实现,按照order排序。
EchoFilter -> ClassLoaderFilter -> GenericFilter -> ContextFilter -> ExecuteLimitFilter -> TraceFilter -> TimeoutFilter -> MonitorFilter -> ExceptionFilter
更确切地说,这里是装饰器和责任链模式的混合使用。例如,EchoFilter的作用是判断是否是回声测试请求,是的话直接返回内容,这是一种责任链的体现。而像ClassLoaderFilter则只是在主功能上添加了功能,更改当前线程的ClassLoader,这是典型的装饰器模式。
(3)观察者模式:
Dubbo的Provider启动时,需要与注册中心交互,先注册自己的服务,再订阅自己的服务,订阅时,采用了观察者模式,开启一个listener。注册中心会每5秒定时检查是否有服务更新,如果有更新,向该服务的提供者发送一个notify消息,provider接受到notify消息后,即运行NotifyListener的notify方法,执行监听器方法。
(4)动态代理模式:
Dubbo扩展JDK SPI的类ExtensionLoader的Adaptive实现是典型的动态代理实现。Dubbo需要灵活地控制实现类,即在调用阶段动态地根据参数决定调用哪个实现类,所以采用先生成代理类的方法,能够做到灵活的调用。生成代理类的代码是ExtensionLoader的createAdaptiveExtensionClassCode方法。代理类的主要逻辑是,获取URL参数中指定参数的值作为获取实现类的key。
Zookeeper 面试题
参考资料: https://blog.csdn.net/wanghaiping1993/article/details/125396988
Zookeeper 注册中心
Q:Zookeeper为什么能做注册中心?
Zookeeper的数据模型是树型结构,由很多数据节点组成,zk将全量数据存储在内存中,可谓是高性能,而且支持集群,可谓高可用。
另外Zookeeper支持事件监听(watch命令)。客户端可以对zookeeper上的数据节点进行Watch,监听数据节点的变化,如果数据节点发生变化,那么所有订阅的客户端都能够接收到通知。
Q:Zookeeper做为注册中心,主要存储哪些数据?存储在哪里?
ip、端口、协议。数据存储在Zookeeper的节点上面。
Q:心跳机制有什么用?
Q:服务提供者能实现失效踢出是什么原理?
服务失效剔除基于zookeeper 的临时节点原理。
Q:讲一下Zookeeper的系统架构。
(1)ZooKeeper分为服务器端(Server) 和客户端(Client),客户端可以连接到整个ZooKeeper服务的任意服务器上(除非 leaderServes 参数被显式设置, leader 不允许接受客户端连接)。
(2)客户端使用并维护一个 TCP 连接,通过这个连接发送请求、接受响应、获取观察的事件以及发送心跳。如果这个 TCP 连接中断,客户端将自动尝试连接到另外的 ZooKeeper服务器。客户端第一次连接到 ZooKeeper服务时,接受这个连接的 ZooKeeper服务器会为这个客户端建立一个会话。当这个客户端连接到另外的服务器时,这个会话会被新的服务器重新建立。
(3)每一个Server代表一个安装Zookeeper服务的机器,即是整个提供Zookeeper服务的集群(或者是由伪集群组成);
(4)组成ZooKeeper服务的服务器必须彼此了解。它们维护一个内存中的状态图像,以及持久存储中的事务日志和快照, 只要大多数服务器可用,ZooKeeper服务就可用;
(5)ZooKeeper 启动时,将从实例中选举一个 leader,Leader 负责处理数据更新等操作,一个更新操作成功的标志是当且仅当大多数Server在内存中成功修改数据。每个Server 在内存中存储了一份数据。
(6)Zookeeper是可以集群复制的,集群间通过Zab协议(Zookeeper Atomic Broadcast)来保持数据的一致性;
(7)Zab协议包含两个阶段:leader election阶段和Atomic Brodcast阶段。
a) 集群中将选举出一个leader,其他的机器则称为follower,所有的写操作都被传送给leader,并通过brodcast将所有的更新告诉给follower。
b) 当leader崩溃或者leader失去大多数的follower时,需要重新选举出一个新的leader,让所有的服务器都恢复到一个正确的状态。
c) 当leader被选举出来,且大多数服务器完成了 和leader的状态同步后,leadder election 的过程就结束了,就将会进入到Atomic brodcast的过程。
d) Atomic Brodcast同步leader和follower之间的信息,保证leader和follower具有形同的系统状态。
Q:Zookeeper的原理是什么?
Q:Zookeeper是怎么保证一致性的?
zab协议。
zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,zab就进入了恢复模式,当领导者被选举出来,且大多数server完成了和 leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和server具有相同的系统状态。
Q:Zookeeper有哪些应用场景?
Zookeeper可以作为服务协调的注册中心。还可以做分布式锁(如果没有用过分布式锁就不要说)
Q:Zookeeper的节点有哪些类型?有什么区别?
临时节点,永久节点。 更加细分就是临时有序节点、临时无序节点、永久有序节点、永久无序节点。
临时节点: 当创建临时节点的程序停掉之后,这个临时节点就会消失,存储的数据也没有了。
Q:说说Zookeeper中的ACL 权限控制机制。
UGO(User/Group/Others)目前在 Linux/Unix 文件系统中使用,也是使用最广泛的权限控制方式。是一种粗粒度的文件系统权限控制模式。
ACL(Access Control List)访问控制列表包括三个方面:
权限模式(Scheme)
(1)IP:从 IP 地址粒度进行权限控制
(2)Digest:最常用,用类似于 username:password 的权限标识来进行权限配置,便于区分不同应用来进行权限控制
(3)World:最开放的权限控制方式,是一种特殊的 digest 模式,只有一个权限标识“world:anyone”
(4)Super:超级用户
授权对象:授权对象指的是权限赋予的用户或一个指定实体,例如 IP 地址或是机器灯。
权限 Permission
(1)CREATE:数据节点创建权限,允许授权对象在该 Znode 下创建子节点
(2)DELETE:子节点删除权限,允许授权对象删除该数据节点的子节点
(3)READ:数据节点的读取权限,允许授权对象访问该数据节点并读取其数据内容或子节点列表等
(4)WRITE:数据节点更新权限,允许授权对象对该数据节点进行更新操作
(5)ADMIN:数据节点管理权限,允许授权对象对该数据节点进行 ACL 相关设置操作
zookeeper分布式锁
Q:Zookeeper是怎么实现分布式锁的?
分布式锁:基于Zookeeper一致性文件系统,实现锁服务。锁服务分为保存独占及时序控制两类。
保存独占:将Zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除自己创建的distribute_lock 节点就释放锁。
时序控制:基于/distribute_lock锁,所有客户端在它下面创建临时顺序编号目录节点,和选master一样,编号最小的获得锁,用完删除,依次方便。
更详细的回答如下:
其实基于Zookeeper,就是使用它的临时有序节点来实现的分布式锁。
原理就是:当某客户端要进行逻辑的加锁时,就在Zookeeper上的某个指定节点的目录下,去生成一个唯一的临时有序节点, 然后判断自己是否是这些有序节点中序号最小的一个,如果是,则算是获取了锁。如果不是,则说明没有获取到锁,那么就需要在序列中找到比自己小的那个节点,并对其调用exist()方法,对其注册事件监听,当监听到这个节点被删除了,那就再去判断一次自己当初创建的节点是否变成了序列中最小的。如果是,则获取锁,如果不是,则重复上述步骤。
当释放锁的时候,只需将这个临时节点删除即可。
Q:Zookeeper 是如何保证事务的顺序一致性的呢?
Zookeeper 采用了递增的事务 id 来识别,所有的 proposal (提议)都在被提出的时候加上了zxid 。 zxid 实际上是一个 64 位数字。高 32 位是 epoch 用来标识 Leader 是否发生了改变,如果有新的Leader 产生出来, epoch 会自增。 低 32 位用来递增计数。 当新产生的 proposal 的时候,会依据数据库的两阶段过程,首先会向其他的 Server 发出事务执行请求,如果超过半数的机器都能执行并且能够成功,那么就会开始执行。
Q:ZooKeeper 集群中个服务器之间是怎样通信的?
Leader 服务器会和每一个 Follower/Observer 服务器都建立 TCP 连接,同时为每个Follower/Observer 都创建一个叫做 LearnerHandler 的实体。LearnerHandler 主要负责 Leader 和Follower/Observer 之间的网络通讯,包括数据同步,请求转发和 proposal 提议的投票等。Leader 服务器保存了所有 Follower/Observer 的 LearnerHandler 。
Q:Zookeeper的广播模式有什么缺陷?
广播风暴。
Q:讲一下Zookeeper的读写机制。
Leader主机负责读和写。
Follower负责读,并将写操作转发给Leader。Follower还参与Leader选举投票,参与事务请求Proposal投票。
Observer充当观察者的角色。Observer和Follower的唯一区别在于:Observer不参与任何投票。
zookeeper集群
Q:Zookeeper 集群服务器,有哪些角色?有哪些状态?
Zookeeper 集群服务器有以下 3 种角色:
- Leader(主)
- Follower(从,参与投票)
- Observer(观察者,不参与投票)
Zookeeper 集群服务器有以下 4 种状态:
- LOOKING
寻找 Leader 状态,当服务器处于该状态时,表示当前集群没有 Leader,因此会进入 Leader 选举状态。 - FOLLOWING
跟随者状态,表示当前服务器角色是 Follower。 - LEADING
领导者状态,表示当前服务器角色是 Leader。 - OBSERVING
观察者状态,表示当前服务器角色是 Observer。
Q:讲一下Zookeeper的选举机制。
简单版:集群初始化,或者集群Leader不可用时,会重新选举Leader。Observer不参与投票。
超过半数的Follower选举投票即可选出新的Leader,投票相同的情况下,根据 myid 和 zxid 的大小共同决断,zxid 更大的优先成为 Leader。
详细版:
(1)基础概念:集群机器 ID 是指 myid,它是每一个集群机器中的编号文件,代表 ZooKeeper 集群服务器的标识,手动生成,全局全一。
事务 ID 是指 zxid,Zookeeper 会给每个更新请求分配一个事务 ID,它是一个 64 位的数字,由 Leader 统一进行分配,全局唯一,不断递增,在一个节点的状态信息中可以查看到最新的事务 ID 信息。
(2)选举方式
Zookeeper 提供了 3 种选举方式:
- LeaderElection
- AuthFastLeaderElection
- FastLeaderElection (最新默认)
(3)选举场景
Zookeeper 会在以下场景进行选举:
- Zookeeper 集群启动初始化时进行选举
- Zookeeper 集群 Leader 失联/宕机时重新选举
(4)集群启动初始化时进行选举,选举大致流程:
1、初始投票
服务器启动后,每个 Server 都会给自己投上一票,每次投票会包含所投票服务器的 myid 和 zxid,这里使用 Server(myid, zxid)的方式表示,此时的投票结果为:zk1(1, 0),zk2(2, 0),zk3(3, 0)
2、同步投票结果
集群中的服务器在投票后,会将各自的投票结果同步给集群中其他服务器。
3、检查投票有效性
各服务器在收到投票后会检查投票的有效性,如:是否本轮投票,是否来自 LOOKING 状态的服务器的投票等。
4、处理投票
服务器之间会进行投票比对,规则如下:
优先检查 zxid,较大的服务器优先作为 Leader
如果 zxid 相同,则 myid 较大的服务器作为 Leader
如:zk1 和 zk2 进行比对,此时 zk2 胜出,zk1 更新自己的投票为:zk1(2, 0)
5、统计投票结果
每轮投票比对之后都会统计投票结果,确认是否有超过半数的机器都得到相同的投票结果,如果是,则选出 Leader,否则继续投票。
本轮选举中,zk1 和 zk2 都得到了相同的投票结果(2, 0),2 指 zk2,并且超过了半数的机器(2 > 3 / 2),所以此时 zk2 就成为了本轮选举的 Leader。
所以,即使 zk3 启动了,因为集群已经有了 Leader,所以选举也结束了,zk3 不再参与选举,后面进来的都是小弟。
6、更改服务器状态
一旦选出 Leader,每个服务器就会各自更新自己的状态:
zk1 >>> FOLLOWING
zk2 >>> LEADING
Zk3 >>> FOLLOWING
Zookeeper 集群按 myid 从小到大依次启动初始化时,在超过半数机器的投票的情况下,谁的 myid 最大,谁就是 Leader。
(5)集群 Leader 挂掉时重新选举,集群重新选举.
选举大致过程:
1、状态变更
既然过去的老大 Leader 不可用了,那所有的 Follower 服务器就需要从 FOLLOWING 状态变更为:LOOKING,开始新的一轮 Leader 选举。
其他步骤与集群启动时的选举是一致的。
集群重新选举时,根据 myid 和 zxid 的大小共同决断,zxid 更大的优先成为 Leader。
参考资料: https://mp.weixin.qq.com/s/RdTDJSMYBqkZGnGsmwoDvw
Q:Zookeeper在选举过程中,会对外提供服务么?
zk集群选举过程中不对外提供服务。
如果leader宕机,集群会马上进行新的leader选举,在选举期间是不对外提供服务的,不满足可用性。
Q:你们的zookeeper集群配置了几个节点?
3个节点。注意,zookeeper集群节点,最好是奇数个的。
集群中的zookeeper节点需要超过半数,整个集群对外才可用。
这里所谓的整个集群对外才可用,是指整个集群还能选出一个Leader来,zookeeper默认采用quorums来支持Leader的选举。
如果有2个zookeeper,那么只要有1个死了zookeeper就不能用了,因为1没有过半,所以2个zookeeper的死亡容忍度为0;同理,要是有3个zookeeper,一个死了,还剩下2个正常的,过半了,所以3个zookeeper的容忍度为1;同理你多列举几个:2->0;3->1;4->1;5->2;6->2会发现一个规律,2n和2n-1的容忍度是一样的,都是n-1,所以为了更加高效,何必增加那一个不必要的zookeeper呢。
Q:zookeeper的集群节点,如果不是奇数的,可能会出现什么问题?
可能会出现脑裂。
假死:由于心跳超时(网络原因导致的)认为master死了,但其实master还存活着。
脑裂:由于假死会发起新的master选举,选举出一个新的master,但旧的master网络又通了,导致出现了两个master ,有的客户端连接到老的master 有的客户端链接到新的master。
详情见:https://my.oschina.net/wangen2009/blog/2994188
Q:zookeeper是怎么解决脑裂的?
过半数机制。超过半数的Follower选举投票才可以选出新的Leader。
SpringCloud面试题(微服务)
SpringColud的理解,详情见: https://www.cnblogs.com/expiator/p/9597071.html
Q:你用过SpringCloud的哪些组件?
服务协调,注册中心,熔断,降级,配置中心,网关。
Eureka 注册中心/服务治理
Q:讲一下Eureka.
Eureka分为服务注册中心,服务提供者 ,服务消费者。服务提供者 、服务消费者都必须指定注册中心。服务提供者提供服务,而服务消费者可以调用提供者的服务。
Q:Eureka是怎么和服务通信的?
心跳机制。
Q:Eureka有哪些特性?
服务提供者有以下特性:
服务续约:在注册完服务之后,服务提供者会维护一个心跳机制用来持续告诉Eureka Server: "我还活着 ” 。
EurekaServer有以下特性:
失效剔除:默认每隔一段时间(默认为60秒) 将当前清单中超时(默认为90秒)没有续约的服务剔除出去。
自我保护:EurekaServer 在运行期间,会统计心跳失败的比例在15分钟之内是否低于85%(通常由于网络不稳定导致)。 Eureka Server会将当前的实例注册信息保护起来, 让这些实例不会过期,尽可能保护这些注册信息。
Q:Eureka怎么保证高可用?
多个注册中心互相注册。
Eureka Server的高可用实际上就是将自己作为服务向其他服务注册中心注册自己,这样就可以形成一组互相注册的服务注册中心,以实现服务清单的互相同步,达到高可用的效果。
Q:eureka挂了服务能正常访问么?
Eureka Client(服务消费者) 从 Eureka Server 上获取服务的注册信息,「并将其缓存在本地」,这句是关键。
当 Eureka Client 在需要调用远程服务时,会从该信息中查找远程服务所对应的 IP 地址、端口等信息。Eureka Client 上缓存的服务注册信息会定期更新(30 秒),如果 Eureka Server 返回的注册表信息与本地缓存的注册表信息不同的话,Eureka Client 会自动处理。
这里,也涉及到两个属性:
- 是否允许获取注册表信息:eureka.client.fetch-registry=true。
- Eureka Client 上缓存的服务注册信息,定期更新的时间间隔
默认 30 秒,可以通过如下属性自行修改:eureka.client.registry-fetch-interval-seconds=30。
参考资料:https://blog.csdn.net/feiying0canglang/article/details/122937727
Q:Eureka注册中心和Zookeeper注册中心,有什么区别?
Eureka注重高可用,属于CAP中的AP。
Zookeeper注重一致性,属于CAP中的CP。
Q:除了Zookeeper,你用过哪些注册中心?有什么区别?
Zookeeper,Redis,Eureka
Zookeeper,是分布式中的CP,能够更好地保证分布式一致性。
Redis基于发布/订阅模式。
Eureka在SpringCloud中应用较多。Eureka是分布式中的AP,也就是注重可用性。
Nacos面试题 -- Nacos注册中心
Q:Nacos服务是如何判定服务实例的状态?
通过发送心跳包,5秒发送一次,如果15秒没有回应,则说明服务出现了问题,
如果30秒后没有回应,则说明服务已经停止。
Q:服务消费方是如何调用服务提供方的资源?
通过RestTemplate第三方类来实现。
Q:Nacos中的负载均衡底层是如何实现的?
通过Ribbon实现,Ribbon中定义了一些负载均衡算法,然后基于这些算法从服务
实例中获取一个实例为消费方提供服务。
Q:如何理解Nacos中的命名空间?
用于进行租户粒度的配置隔离。不同的命名空间下,可以存在相同的 Group 或 Data ID 的配置。Namespace 的常用场景之一是不同环境的配置的区分隔离,例如开发测试环境和生产环境的资源(如配置、服务)隔离等。
命名空间,也就是namespace,其实这个概念并不是Nacos中独有的,在Nacos中,不管是配置还是服务,都是属于某一个命名空间中的,默认情况下都是属于pulibc这个命名空间中的,我们可以在Nacos中新增命名空间,也就相当于开辟了另外一套存放服务和配置的地方,命名空间之间是独立的,完全不冲突的,所以我们可以利用Nacos中的命名空间来实现不同环境、不同租户之间的服务注册和配置。
Q:Nacos中保证的是CP还是AP?
通常我们说,Nacos技能保证CP,也能保证AP,具体看如何配置,只有注册中心的数据需要进行集群节点之间的同步,从而涉及到是CP还是AP,如果注册的节点是临时节点,那么就是AP,如果是非临时节点,那么就是CP,默认是临时节点。
Q:Nacos的就近访问是什么意思?
首先,在Nacos中,一个服务可以有多个实例,并且可以给实例设置cluster-name,就是可以再进一步的给所有实例划分集群,那如果现在某个服务A想要调用服务B,那么Naocs会看调用服务A的实例是属于哪个集群的,并且调用服务B时,那就会调用同样集群下的服务B实例,根据cluster-name来判断两个实例是不是同一个集群,这就是Nacos的就近访问。
Q:什么是健康保护阈值?
为了防止因过多实例 (Instance) 不健康导致流量全部流向健康实例 (Instance) ,继而造成流量压力把健康实例 (Instance) 压垮并形成雪崩效应,应将健康保护阈值定义为一个 0 到 1 之间的浮点数。当域名健康实例数 (Instance) 占总服务实例数 (Instance) 的比例小于该值时,无论实例 (Instance) 是否健康,都会将这个实例 (Instance) 返回给客户端。这样做虽然损失了一部分流量,但是保证了集群中剩余健康实例 (Instance) 能正常工作。
服务消费 Feign
Q:讲一下Feign。
Q:为什么要使用Feign?
Feign可以进行服务消费,Feign内置了Hystrix 和 Ribbon。
1.feign采用的是基于接口的注解。
2.feign整合了ribbon,具有负载均衡的能力。
3.整合了Hystrix,具有熔断的能力。
Q:Feign使用了哪些协议?
Http协议。
Q:Feign底层原理。
动态代理。
服务消费 Ribbon
Q:SpringCloud如何进行负载均衡?
使用Ribbon.
Q:Ribbon有哪些功能?
负载均衡,重试机制。
Q:Ribbon有哪些负载均衡的策略?
常用的有:轮询,随机,加权。
随机策略:随机选择server.
轮询策略:按照顺序选择server(ribbon默认策略).
重试策略:在一个配置时间段内,当选择server不成功,则一直尝试选择一个可用的server.
最低并发策略:逐个考察server,如果server断路器打开,则忽略,再选择其中并发链接最低的server.
可用过滤策略:过滤掉一直失败并被标记为circuit tripped的server,过滤掉那些高并发链接的server(active connections超过配置的阈值).
响应时间加权重策略:根据server的响应时间分配权重,响应时间越长,权重越低,被选择到的概率也就越低。响应时间越短,权重越高,被选中的概率越高,这个策略很贴切,综合了各种因素,比如:网络,磁盘,io等,都直接影响响应时间.
区域权重策略: 综合判断server所在区域的性能,和server的可用性,轮询选择server并且判断一个AWS Zone的运行性能是否可用,剔除不可用的Zone中的所有server.
参考: https://www.cnblogs.com/idoljames/p/11698923.html
Hystrix熔断
Q:讲一下Hystrix。为什么要使用熔断?
当某个服务发生故障(类似用电器发生短路)之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个错误响应,而不是长时间的等待。这样就不会使得线程因调用故障服务被长时间占用不释放,避免了故障在分布式系统中的蔓延。
使用熔断,可以避免服务雪崩。
Q:Hystrix熔断的原理是什么?
"舱壁模式",实现进程线程池的隔离,它会为每一个服务创建一个独立的线程池,这样就算某个服务出现延迟过高的情况,也不会拖慢其他的服务。
Q:Hystrix熔断有哪几种方隔离方式?
线程池隔离。信号量隔离。
Q:这两种隔离模式,有什么区别?
在大部分情况下,使用线程池隔离会有非常微小的延迟(9ms),可以忽略不计。
如果对延迟的要求非常高的话,可以使用信号量隔离。
信号量的开销远比线程池的开销小,但是信号量不能设置超时,也没法实现异步访问。
Q:什么时候会触发熔断?什么时候断路器的状态会发生变化?
当QPS达到20,或者请求失败率达到50%,断路器就会变成打开,就会触发熔断。
断路器变成打开状态后,会进行休眠,默认5秒,在到达休眠时间后,将再次允许请求尝试访问,此时为"半开状态",若此时请求继续失败,那断路器又会进入"打开状态",如此循环。
Q:熔断如何设置超时时间,重试次数?
如果超时时间设置过短,或者重试次数过多,会频繁地重试,加大服务的压力。
如果超时时间设置过长,可能会导致请求响应慢,导致阻塞、卡顿。
超时时间设置:方案一,按照服务提供者线上真实的服务水平,取 P999 或者 P9999 的值,也就是以 99.9% 或者 99.99% 的调用都在多少毫秒内返回为准。
方案二,按照接口重要性来进行设置,并发低的接口设置的超时时间可以多点,比如2s,并发高的接口设置的超时时间可以设置的低点,比如200ms。
重试时间设置:一两次即可。大部分情况下,调用失败都是因为偶发的网络问题或者个别服务提供者节点有问题导致的,如果能换个节点再次访问说不定就能成功。
如果是读比较多的服务,重试次数设置多一些也没关系。如果是写比较多的服务,最好还是减少重试次数,或者不设置重试,否则容易出错。
Q:讲一下熔断和降级的区别?
熔断是直接返回一个错误响应。
服务降级是采取备用逻辑。
服务降级:当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作。
在服务降级逻辑中,我们需要实现一个通用的响应结果,并且该降级逻辑应该是从缓存或者是一些降级逻辑中获取,而不是依赖网络请求获取,这样能够稳定地返回结果的处理逻辑。
Q:Hystrix什么时候会触发服务降级?
当前Hystrix命令处于"熔断/短路"状态,断路器是打开的时候。
当前Hystrix命令的线程池,请求队列,或者信号量被占满的时候。
Zuul网关
Q:Zuul网关,有什么功能?
Zuul能够进行过滤(Filter),设置白名单。
Zuul还能进行请求路由/服务路由。
路由功能,负责将外部请求功能转发到具体的微服务实例上,是实现外部访问统一入口的基础。
Q:Zuul网关如何实现路由?
通过服务路由的功能,在对外提供服务的时候,只需要通过暴露Zuul中配置的调用地址就可以让调用方统一的来访问我们的服务,而不需要了解具体提供服务的主机信息了。
Q:Zuul有几种过滤器类型?
4种。
pre : 可以在请求被路由之前调用。
适用于身份认证的场景,认证通过后再继续执行下面的流程。
route : 在路由请求时被调用。
适用于灰度发布场景,在将要路由的时候可以做一些自定义的逻辑。
post :在 route 和 error 过滤器之后被调用。
这种过滤器将请求路由到达具体的服务之后执行。适用于需要添加响应头,记录响应日志等应用场景。
error : 处理请求时发生错误时被调用。
在执行过程中发送错误时会进入 error 过滤器,可以用来统一记录错误信息。
Q:Gateway和Zuul有什么区别和联系?
Zuul:
使用的是阻塞式的 API,不支持长连接,比如 websockets。
底层是servlet,Zuul处理的是http请求
没有提供异步支持,流控等均由hystrix支持。
依赖包spring-cloud-starter-netflix-zuul。
Gateway:
底层依然是servlet,但使用了webflux,多嵌套了一层框架。
依赖spring-boot-starter-webflux和/ spring-cloud-starter-gateway。
提供了异步支持,提供了抽象负载均衡,提供了抽象流控,并默认实现了RedisRateLimiter。
-
相同点:
1、底层都是servlet
2、两者均是web网关,处理的是http请求 -
不同点:
1、内部实现:
gateway对比zuul多依赖了spring-webflux,在spring的支持下,功能更强大,内部实现了限流、负载均衡等,扩展性也更强,但同时也限制了仅适合于Spring Cloud套件
zuul则可以扩展至其他微服务框架中,其内部没有实现限流、负载均衡等。
2、是否支持异步:
zuul仅支持同步。gateway支持异步。
理论上gateway则更适合于提高系统吞吐量(但不一定能有更好的性能),最终性能还需要通过严密的压测来决定。
3、框架设计的角度:
gateway具有更好的扩展性,并且其已经发布了2.0.0的RELESE版本,稳定性也是非常好的。
4、性能:
WebFlux 模块的名称是 spring-webflux,名称中的 Flux 来源于 Reactor 中的类 Flux。Spring webflux 有一个全新的非堵塞的函数式 Reactive Web 框架,可以用来构建异步的、非堵塞的、事件驱动的服务,在伸缩性方面表现非常好。使用非阻塞API。 Websockets得到支持,并且由于它与Spring紧密集成,所以将会是一个更好的开发体验。
参考:https://www.cnblogs.com/lgg20/p/12507845.html
Nacos面试题 -- Nacos配置中心
-
Q:为什么使用配置中心?
集中管理配置信息,动态发布配置信息。减少多个服务中的冗余配置。 -
Q:项目中为什么要定义 bootstrap.yml 文件?
bootstrap.yml 文件被读取的优先级比较高,可以在服务启动时读取配置中心的数据) -
Q:Nacos配置中心宕机了,我们的服务还可以读取到配置信息吗?
可以从内存,客户端获取配置中心的配置信息以后,会将配置信息在本地存储一份) -
Q:微服务应用中我们的客户端如何从配置中心获取信息?
我们的服务一般会先从内存中读取配置信息,同时我们的微服务还可以定时向nacos配置中心发请求拉取(pull)更新的配置信息
SpringCould Config配置中心
Q:讲一下Config。
配置管理工具包,让你可以把配置放到远程服务器,集中化管理集群配置,目前支持本地存储、Git以及Subversion。
"一次配置,随处可用"。
SkyWalking链路追踪
待补充
参考资料:
Dubbo面试题: https://blog.csdn.net/m0_48795607/article/details/116237861