大家好,我是付威,一名已在编码第一线奋斗了十余年的程序员。在2019年我初次接触到领域驱动设计(Domain-Driven Design,简称DDD)的概念。在我的探索中,我发现许多有关DDD的教程过于偏重于战略设计,充斥着许多晦涩难懂的概念,导致阅读起来相当艰难。有些教程往往只是解释了DDD的概念,而未深入探讨为何要采用这种方式以及这样做能带来哪些好处,这导致很多人在实践应用DDD时遇到了诸多难题。甚至有些人为了引入DDD而在项目中强制采用DDD架构,结果却意外增加了代码的复杂性,带来了一系列潜在的风险。
为了解决这一问题,我计划从代码的基础入手,详细讲解如何将DDD的理念应用于实际开发中,以便解答为何DDD能使我们的代码更加整洁的问题。今天,我们将着重讨论如何运用DDD的思想来组织我们的代码,从而实现"高内聚、低耦合"的开发目标。
首先,让我们看一个电商系统中下单功能的代码示例:
@Autowired
ProductDao productDao;
@Autowired
UserDao userDao;
public void createOrder(String productId,String userId,int count){
Product product = productDao.queryById(productId);
UserInfo user=userDao.queryByUserId(userId);
//风控检测
RiskResponse riskRes= riskClient.queryRisk(xxx);
if(riskRes!=null&&riskRes.getCode()==0&&riskRes.getRiskCode().equal("0001")){
//命中风控
throw new BizException("下单失败,请检查网络")
}
Order order=new Order();
order.setOrderId(IdUtils.generateId());
order.setPrice(product.getPrice()*count);
order.setAddress(user.getAddress());
order.setStatus(OrderEnum.OrderSucess);
orderDao.insert(order);
//预热缓存和增加记录
redisService.set("Order:OrderID_"+order.getOrderId(),order);
orderLogDao.addLog(order);
MessageEntity message = new MessageEntity();
message.setOrderId(order.getOrderId());
message.setMessage("下单成功");
kafkaSender.sent(messageEntity);
}
代码分析
首先,我们对这段代码的逻辑进行整理,共涉及5个步骤:
- 查询商品和用户信息
- 下单行为的风控检测
- 订单创建和持久化
- 写入缓存和记录下单日志
- 发送订单下单成功消息,通知其他系统
我们从这几个过程入手,根据业务的重要性,我们可以将它们划分为核心业务和非核心业务。显然,下单及其相关操作属于核心代码(步骤1、2、3)。与此相比,写日志、写入缓存以及发送Kafka消息则属于下单过程的非核心业务
核心代码分析
1. 【查询商品和用户信息】
productDao 和 userDao 这两个类是用于封装数据库的增删改查(CRUD)操作。然而,这种封装方式的问题在于,它们的方法实现与具体的数据存储介质密切相关,导致我们的业务逻辑对数据存储方式有着强烈的依赖。
举个例子来说明:当前情况下,我们的数据存储介质是MySQL数据库,因此 userDao 和 productDao 类中的方法都是基于SQL语句的封装。然而,如果以后需要更换不同的数据访问框架,或者将数据存储从MySQL迁移到Elasticsearch(ES),我们就必须修改 userDao 和 productDao 类的实现,以适应新的数据存储方式。这样的操作不仅会对核心业务代码产生影响,还会在项目的各个角落引发不确定性,从而导致每一次的代码优化都需要小心谨慎地进行。
这种紧密耦合的情况,除了增加了代码维护的难度,还可能引发系统的脆弱性。一旦需要改动存储层的实现,就必须在整个项目中寻找并修改所有与之相关的代码。这不仅消耗时间,还增加了出错的可能性。
2.【下单的行为的风控检测】
在订单生成的过程中,我们会调用风控查询的接口,这一步骤可以被视为对第三方应用的一种依赖。这种依赖关系迫使我们在处理返回值时必须非常仔细,涵盖判断返回值是否存在、验证成功的响应状态、以及业务代码的验证等多个环节,以确保我们的代码具备足够的健壮性。
然而,这种依赖关系同时也带来了潜在的问题,即我们的核心业务逻辑可能会随着第三方接口的变更而需要进行修改。以一个实际例子来说明,假设风控接口新增了代表风控生效的业务代码,如0002、0003等,那么我们的核心代码就必须相应地进行调整,例如:
riskRes!=null&&riskRes.getCode()==0&&(riskRes.getRiskCode().equal("0001")||riskRes.getRiskCode().equal("0002")||riskRes.getRiskCode().equal("0003")),
然而,这种改动会使代码变得难以阅读和维护。每次接口变更,我们都需要在多处代码中进行类似的修改,而且这些修改会在整个代码库中产生涟漪效应,导致代码的耦合度上升,可维护性下降。
3. 【订单的创建和持久化】
关于持久化的问题,上面已经有过详细的讲解,因此不再赘述。
在观察订单的创建过程时,我们发现这属于核心业务的关键部分。然而,仔细思考下,我们发现实际需要的其实是订单创建的结果。因此,将这个过程放在核心的业务代码中,可能会对代码的可读性产生不良影响。
很多朋友看到这里可能会想到,我们可以将订单的创建过程独立出来,以此来减轻核心业务对订单创建过程的依赖。当然,这是一个合理的解决方案,许多DDD实践也是这么做的。 我个人更倾向于采用实体的工厂模式来创建实体,以此进一步解耦实体的创建过程。
如果我们采用这种方式,我们可以更好地组织和管理代码,使其更易于阅读和理解。同时,这也能够避免在核心业务代码中过度混合不同的功能,从而提高代码的可维护性。
在订单创建过程中,有两个属性的赋值操作
order.setOrderId(IdUtils.generateId());
order.setPrice(product.getPrice() * count);
这两个赋值语句背后蕴含着更深层次的业务意义。其中,生成订单号是为了唯一标识每个订单,确保订单信息的准确无误;而计算订单价格则是根据产品数量和单价进行计算,确保订单金额的准确性。
然而,在传统的贫血模型中,这些隐藏在赋值语句背后的业务意义并没有得到明确的定义和体现。当类似的业务代码分散在各个类或服务中时,会导致业务代码呈现出碎片化的状态,无法形成有机的整体。在进行修改和维护时,我们需要在整个代码库中搜索引用,分别进行修改,这无疑增加了维护的难度和成本。
非核心代码分析
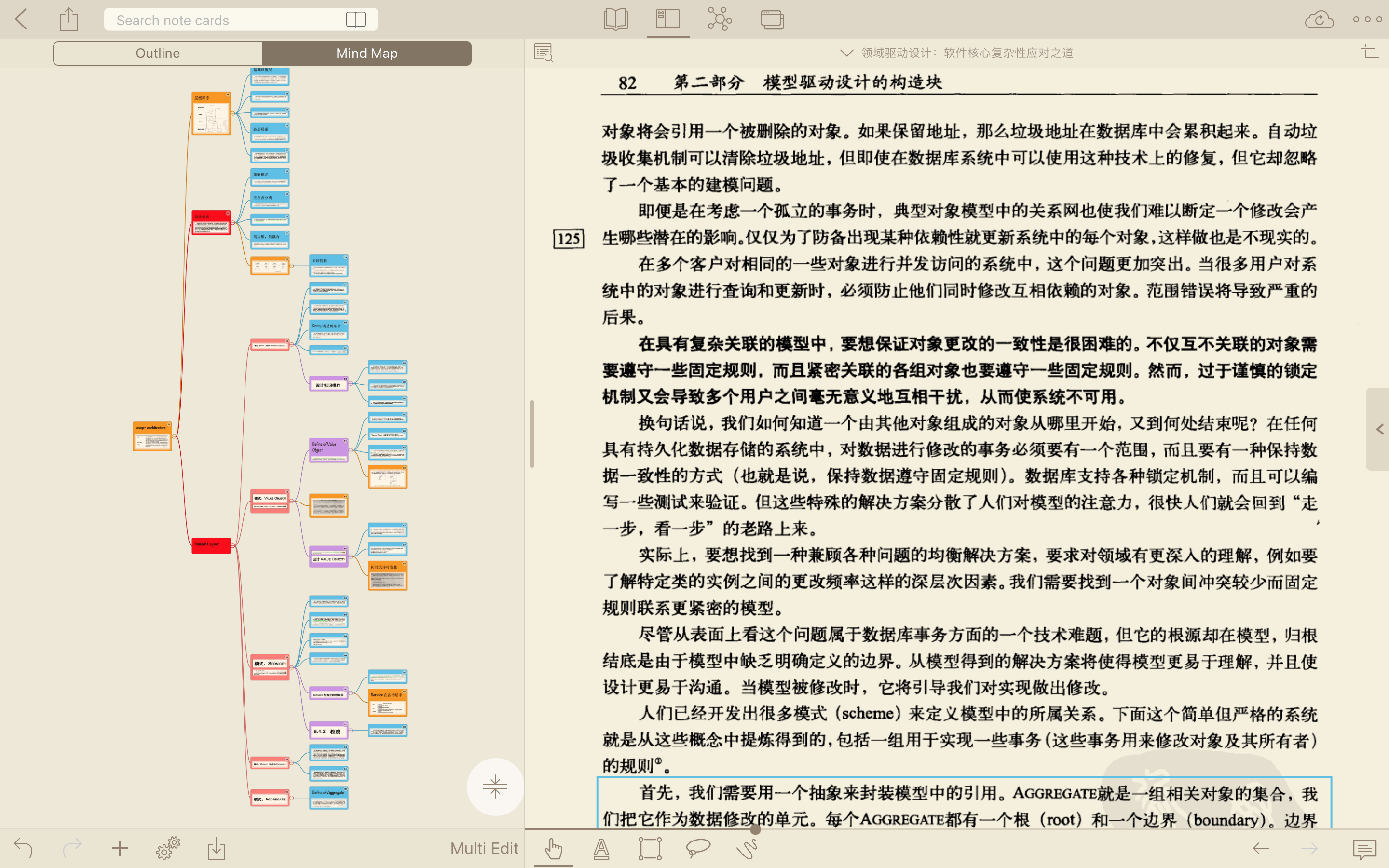
在领域驱动设计(DDD)中,我们通常将系统划分为三个主要部分:核心域、通用域和支撑域。
-
核心域:这是业务的核心部分,包括业务的核心规则和业务流程。在这个例子中,下单动作及其依赖的数据应该是核心域的一部分。
-
通用域:这个部分包含了一些跨领域的业务逻辑,比如缓存、日志记录、通知等。在这个例子中,下单后写入缓存、写入下单日志和通知都属于通用域。
-
支撑域:这个部分包含了一些基础设施和公共代码,比如数据库访问、网络通信、错误处理等。
对于如何拆分, 并没有固定的规则,需要根据具体的业务需求来确定。在这个例子中,由于下单动作及其依赖的数据是核心,而下单后写入缓存、写入下单日志和通知属于其他领域,所以应该采用领域间的交互方式进行拆分。也就是说,下单动作应该在核心域中完成,而写入缓存、写入下单日志和通知等操作则通过领域间的方式进行调用。这样可以保证核心域的内聚性,同时也可以降低不同领域之间的耦合度。
代码优化与领域驱动设计
问题分析总结
结合以上讨论,我们归纳出上述代码存在的问题:
- 第三方接口的业务无关性影响核心业务可维护性,容易引发对核心代码的频繁修改,降低代码的稳定性和可维护性。
- 业务逻辑与数据存储紧耦合,难以实现逻辑的复用和数据存储的切换,扩展性受限。
- 核心业务中掺杂了与核心业务无关的代码片段,影响代码的可读性,理解核心逻辑需要分离非关键细节。
- 实体内的业务逻辑分散在代码的不同地方,导致业务逻辑零散、难以维护。
- 领域间存在强耦合,对其他领域的修改容易对当前核心逻辑造成意外影响,增加系统的脆弱性和改动的风险。
代码优化实践
为了解决上述问题,我们引入了DDD的思想,通过优化核心业务代码和拆分通用业务逻辑,使代码更加整洁和可维护。以下是我们对代码的优化方案和具体实现:
1. 适配器模式隔离第三方接口
原始代码中的风控查询接口可能会变化,因此我们引入了适配器模式,将第三方接口的调用从核心业务代码中分离出来。具体地,我们创建了一个 RiskCheckAdapter 类来封装风控查询逻辑,并将返回值转化为业务领域的语言。这样,核心业务只关心风控是否通过,而不关心具体的返回值和变化。
@Service
public class RiskCheckAdapter {
@Autowired
private RiskClient riskClient;
public boolean isRiskDetected(String productId, String userId) {
RiskResponse riskRes = riskClient.queryRisk(xxx); // 根据实际情况传入参数
return riskRes != null && riskRes.getCode() == 0 && riskRes.getRiskCode().equals("0001");
}
}
@Service
public class RiskCheckService {
@Autowired
private RiskCheckAdapter riskCheckAdapter;
public boolean isRiskCheckPassed(String productId, String userId) {
return riskCheckAdapter.isRiskDetected(productId, userId);
}
}
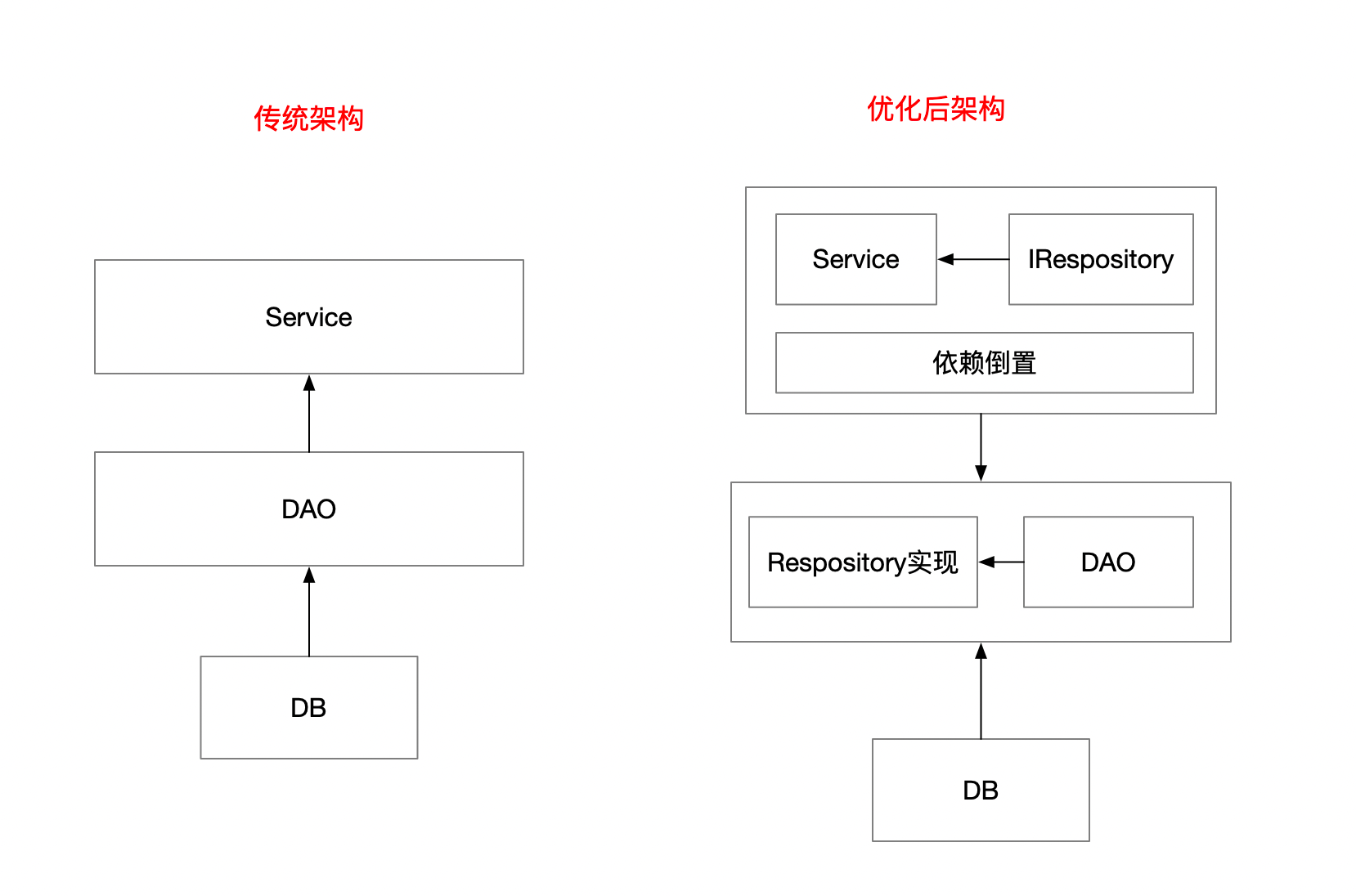
2. 仓储模式解耦数据访问
为了解决核心业务与数据存储的紧密耦合问题,我们引入了仓储模式。通过创建抽象的仓储接口和具体的实现,我们将核心业务与数据访问解耦。这样,如果数据存储介质发生变化,只需修改对应的仓储实现,而不影响核心业务代码。
// IProductRepository.java
public interface IProductRepository {
Product findById(String productId);
}
// IUserRepository.java
public interface IUserRepository {
User findByUserId(String userId);
}
// IOrderRepository.java
public interface IOrderRepository {
Order add(OrderDO order);
}
// IOrderLogRepository.java
public interface IOrderLogRepository {
void addLog(OrderLogDO log);
}
// ProductRepository.java
@Repository
public class ProductRepository implements IProductRepository {
@Autowired
private ProductDao productDao;
@Override
public Product findById(String productId) {
return productDao.queryById(productId);
}
}
// UserRepository.java
@Repository
public class UserRepository implements IUserRepository {
@Autowired
private UserDao userDao;
@Override
public User findByUserId(String userId) {
return userDao.queryByUserId(userId);
}
}
// UserRepository.java
@Repository
public class OrderRepository implements IOrderRepository {
@Autowired
private OrderDao orderDao;
@Autowired
private OrderConvert orderConvert;
@Override
public int save(OrderDO order) {
OrderPO orderPO=orderConvert.convertPO(order);
return orderDao.insert(orderPO);
}
}
// OrderLogRepository.java
@Repository
public class OrderLogRepository implements IOrderLogRepository {
@Autowired
private OrderLogDao orderLogDao;
@Override
public void addLog(OrderLog log) {
orderLogDao.addLog(log);
}
}
经过上面的组合后,从下图中我们可以看下前后的依赖对比,从图中可以看出,service层已经对数据不再有数据依赖。
3. 充血模式收敛实体业务逻辑
通过将实体的业务逻辑进行收敛,我们可以提高代码的内聚性和可读性。原始的贫血模式中,订单实体的业务逻辑分散在各处,使得代码难以维护。现在,我们使用充血模式,将订单的创建和属性设置封装在实体内部,提高了代码的聚焦度。
public class Order {
private String orderId;
private int count;
private double totalPrice;
private String address;
private int status;
public void createOrder(Product product, User user, int count) {
this.address = user.getAddress();
this.status = OrderEnum.OrderSuccess;
this.generateOrderId();
this.calculateTotalPrice(product.getPrice(), count);
}
private void generateOrderId() {
this.orderId = IdUtils.generateId();
}
private void calculateTotalPrice(double price, int count) {
this.count = itemCount;
this.totalPrice = price * count;
}
// ...其他属性和方法
}
public class OrderFactory {
public static Order createOrder(Product product, User user, int itemCount) {
Order order = new Order();
order.createOrder(product, user, itemCount);
return order;
}
}
//使用方式
Order order = orderFactory.createOrder(product, user, count);
orderDao.insert(order);
-
领域事件解耦领域间通信
在解耦领域之间的通信方面,我们引入了领域事件。通过定义领域事件、事件监听器以及事件发布机制,不同领域之间的交互变得更加松耦合。这样,当订单创建完成时,我们只需发布订单创建事件,其他领域根据事件进行响应,降低了领域间的依赖性。示意图如下:
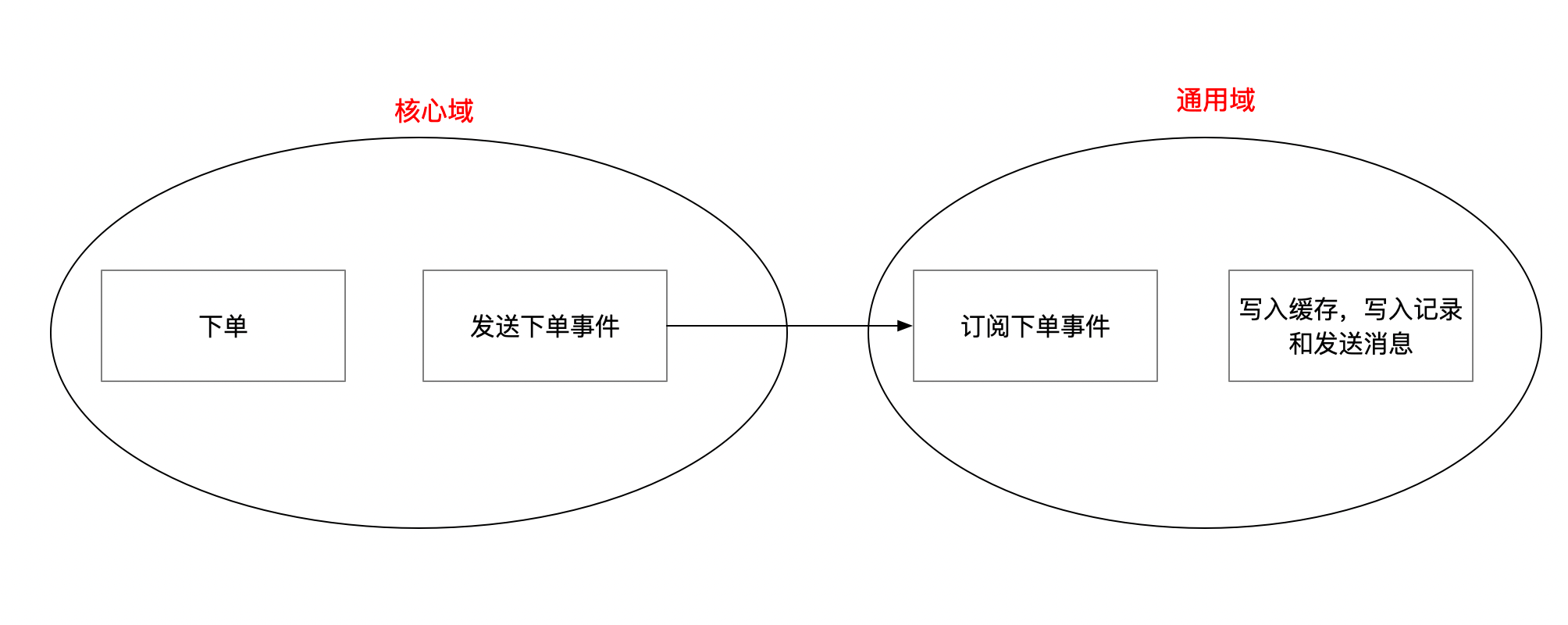
事件的代码:
// CommonEventListener.java
@Service
public class CommonEventListener {
@Autowired
private IOrderLogRepository orderLogRepository;
@Autowired
private RedisService redisService;
@Autowired
private KafkaSender kafkaSender;
@EventListener
public void handleOrderCreatedEvent(OrderCreatedEvent event) {
String orderId = event.getOrderId();
Order order = getOrderDetailsFromRepository(orderId);
// Process the event within the domain object
order.processOrderCreatedEvent(orderLogRepository, redisService);
sendMessage(order);
}
private Order getOrderDetailsFromRepository(String orderId) {
// Retrieve order details from repository using orderId
// Return the Order object
}
private void sendMessage(Order order) {
MessageEntity message = new MessageEntity();
message.setOrderId(order.getOrderId());
message.setMessage("下单成功");
kafkaSender.send(message);
}
}
优化后的核心业务代码
经过上述优化,核心业务代码变得更加清晰和可维护。以下是优化后的订单创建过程的示例:
// OrderServiceImpl.java
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private ApplicationEventPublisher eventPublisher;
@Autowired
private IProductRepository productRepository;
@Autowired
private IUserRepository userRepository;
@Autowired
private IOrderRepository orderRepository;
@Autowired
private IOrderFactory orderFactory;
@Autowired
private RiskCheckService riskCheckService;
@Override
public Order createOrder(String productId, String userId, int count) {
Product product = productRepository.findById(productId);
User user = userRepository.findByUserId(userId);
boolean isRiskPassed = riskCheckService.isRiskCheckPassed();
if (!isRiskPassed) {
throw new BizException("下单失败,请检查网络");
}
Order order = orderFactory.createOrder(product, user, count);
orderRepository.save(order);
// Publish OrderCreatedEvent
eventPublisher.publishEvent(new OrderCreatedEvent(order.getOrderId()));
return order;
}
}
总结:
通过领域驱动设计的思想,我们成功地对原始的代码进行了优化。引入适配器模式、仓储模式、充血模式和领域事件等概念,使得代码更加整洁、可读和可维护。这些优化不仅使核心业务更加稳定,也为未来的扩展和变化提供了更好的支持。
在下一讲中,我们将探讨如何在项目架构中演进DDD,并提供一个简洁的项目框架作为示例。感谢大家的关注!