CQRS是Command Query Responsibility Seperation(命令查询职责分离)的缩写。 世上很多事情都比较复杂,但是我们只要进行一些简单的分类后,那么事情就简单了很多,比如我们把人分为男人和女人,也可以把人分为大人和小孩,还比如,我们说国内和国外,城市和农村。经过一些类似这样的划分,我们的对不同的类就有不同的关注。 这样我们就会有妇女儿童医院专门让女人生孩子,而不会建一个医院让男女都生孩子。
CRUD
CRUD (Create, Read, Update, Delete) 增查改删,我们很多系统都是对数据的增查改删。过去我们很多系统比较简单,基本上增加的数据就是你要查询的数据,所以很多时候其实一个简单的Excel就能搞定。 而且增删改查也足够的简单,所以我们很多系统分层后在数据层Repository里仍是对单表的增删改查,这样对不少的系统都符合。
但是,系统规模稍微大一点,我们都知道我们的数据库里的数据模型很难和我们业务层需要的模型一致。 于是我们引入了Domain Model, Repository里就会做Domain Model的来回转换
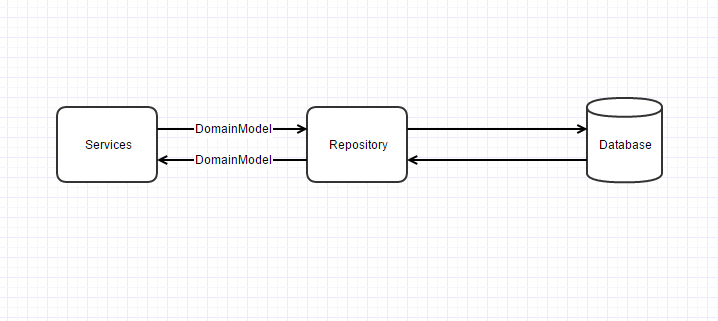
同时我们在UI层要的数据,往往又和具体的Domain不同,这个时候我们又要定义一个ViewModel. 而这些ViewModel又是组合不同的DomainModel得来。
传统的代码里的问题:
- 领域里有很多分页和排序,尤其是Repository里
- 查询的方法里暴露了很多不应该有的领域模型的属性,因为需要组装DTO
- 如果使用ORM,预加载了很多数据以提高性能,但是占用大量内存,而且需要维护这些数据。
- 加载组合庞大的数据,比如页面是需要一个名字,我们也会把整个User数据取出来。
重要的原来把数据混在一起,复杂的查询相当难以优化。 尤其是数据库出现大量的Join 系统性能极速下降。
最重要的是我们把读写都放在了一起,显得责任不够清晰,代码也更复杂了一些,比如读数据是不太关心事物的,读数据是不需要验证的,只有写的时候才需要做数据校验,这也比较符合SRP(单一职责),但是用CRUD的思维是我们全都混在了一起。
CQRS
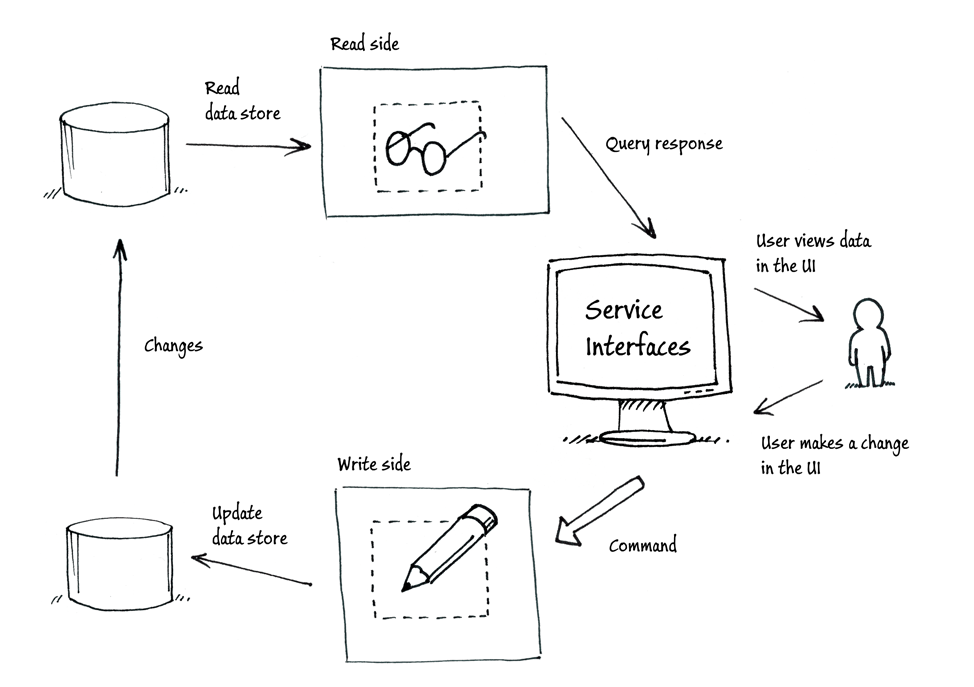
我们仔细看CRUD, 其实可以更简单的分为读(R)和写(CUD), 我们想想大部分情况都是,一个方法要么是执行一个Command完成一个动作,要么就是查询返回数据。 比如我们回答问题的人不应该去修改问题。
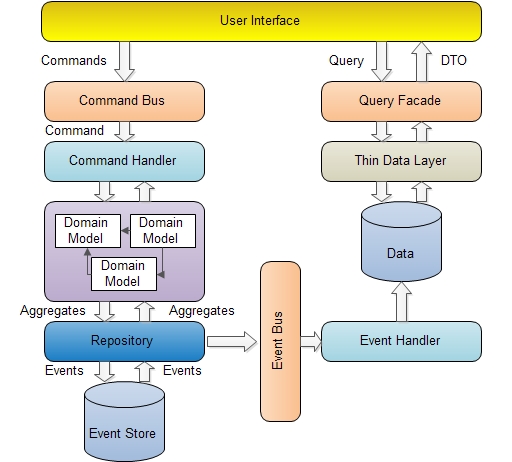
当我们读写分离后,我们对应的代码也会分离。
数据存储
写的一端需要保证事物,所以一般数据存储为第三范式,
读的一端一般都是反范式可以避免Join操作,这样我们只需要把数据存储为第一范式
扩展
大部分的系统里写数据要远远少于读数据,并且一般都是每次修改很少的一部分数据,所以在写这端扩展都不是特别紧迫,读数据基本都远大于写数据的次数, 所以扩展就更重要。 我们很难建立同一个Model 既能给写数据和读数据公用而且能够保证性能都比较好的。
查询端
查询端由于只是读数据,那么所有的方法应该都是返回数据,而且返回的数据就是界面直接需要的DTO, 这样可以减少传统的方法中把DomainModel映射为ViewModel或者DTO. 同时可以减少传统的领域里的一些混乱。
写端
由于把读分离出去,所以我们就只关注写,那么我们写这一段需要保证事物,数据输入的验证,另外一般写这一端都不需要及时的看到结果,所以大部分都需要一个void方法就可以,那么让我们系统异步就更加方便。这样使系统的扩展性大大增强。
代码更容易集中处理
当我在一些系统中使用CQRS后,很多地方代码大大简化,比如我所有的写操作都是一个Command, 那么我定义一个UICommand, 让所有的Command集成这个,那么我可以在这个UICommand里做一些通用的处理,比如Validation
同时我只需要定义一个CommandBus, 然后把对应的CommandBus分发到对应的Handler里(我前面几篇有实例代码),那么代码的耦合度大大降低。
代码分工协作更容易
由于读这一端直接读数据,而且对数据库没有任何操作,那么我们可以根据UI定义对应的DTO, 那么开发的时候我们可以用Mock数据,至于数据怎么存的,那么我们随后只要添加一层Thin Data Layer即可,实际上当我们使用CQRS后,很多时候我们把数据保存的时候都直接保存为Denormalize的,那么从数据里直接查询单表的数据就可以拿到页面需要的数据,大大提升读取数据的性能,同时代码也会极其的简化,开发读这一段代码的开发人员甚至都不需要对业务有太多了解。
实现
简单的实现
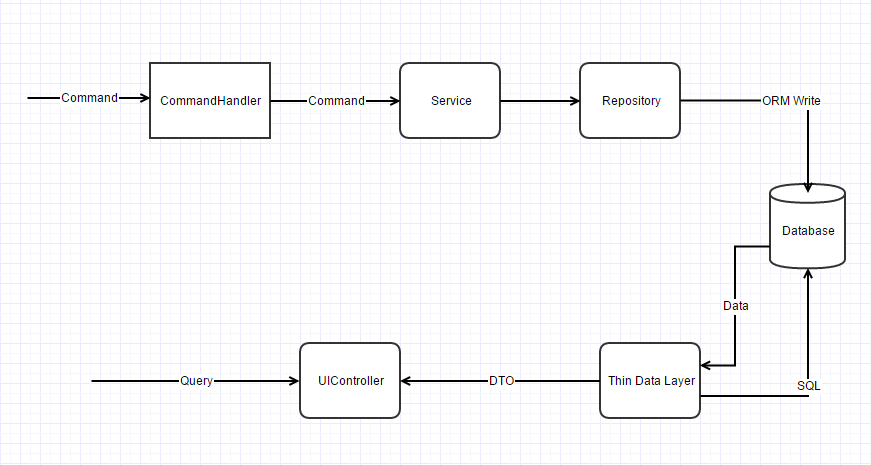
使用的Event后
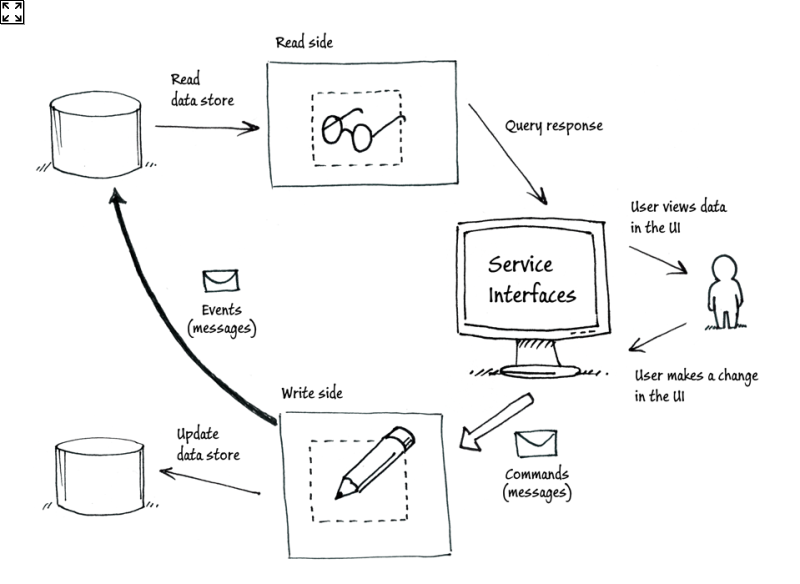
使用了Event Source 和Service bus后


![从壹开始微服务 [ DDD ] 之四 ║让你明白DDD的小故事 & EFCore初探](https://cdnss.haodaima.top/uploadfile/2024/0319/20240319084422588.png)