领域驱动设计理解&总结 这篇文章主要是通读《实现领域驱动设计》之后自己的理解和总结(同时也参照一些博文的分析来加深自己的理解);
有些疑问是自定义内容,虽然有自己的理解,但依然感觉较为抽象,后续会通过实践来理解其中的精妙之处。
领域驱动设计指引
-
领域驱动设计 作为一种软件开发方法,提供了战略上(思考方式) 和 战术上(落地方式) 的建模工具来帮助我们 设计高质量的软件模型;
-
领域驱动设计 不是关于技术的,而是关于讨论、聆听、理解、发现业务价值 的,目的是将 知识 集中起来,形成 通用语言(Ubiquitous Language);
-
在 领域驱动设计 中,技术也重要,但更重要的是要掌握 领域建模 中更高层次的概念;
领域建模
在领域中构建模型,什么是 领域模型?
-
关于 某个特定业务领域的软件模型。通常,领域模型通过 对象模型 来实现,这些对象包含了数据和行为,并且表达了准确的业务含义。
为什么要使用DDD
Vaughn Vernon(沃恩.弗农) 在他的书里(《实现领域驱动设计》)阐述了很多,总结3点:
-
领域专家、开发者、业务人员等都掌握同样的软件知识,大家都使用相同的语言进行交流,每个人互相理解彼此在说什么;
-
设计就是代码,代码就是设计,软件能够表达大家所理解的意思;
-
DDD持续关注业务,会产生一些业务价值
-
获得一个有用的 领域模型;
-
业务得到更准确的 定义和理解;
-
领域专家可以为领域设计做出贡献;
-
更好的用户体验(软件本身容易上手,减少培训,提高效率)
-
清晰的模型边界
-
良好的企业架构
-
敏捷、迭代式和持续建模
-
使用 战略和战术工具
-
DDD推进过程中存在的挑战
-
创建通用语言(所有人达成一致的某个业务术语的统一认知)消耗额外的时间和精力
-
持续的将领域专家引入项目
-
改变开发者 对领域的思考方式
如何使用DDD
DDD 提供了战略上 和 战术上 的建模工具来帮助我们 设计高质量的软件模型,战略设计 侧重于高层次、宏观上去划分和集成限界上下文,而 战术设计 则关注更具体使用建模工具来细化上下文。
战略上
-
限界上下文(Bounded Context) 为团队创建一个建模边界;
-
成员在边界内部为特定的 业务领域 创建 解决方案;
-
单个限界上下文中团队成员共享一套 通用语言(Ubiquitous Language);
-
不同团队各自负责一个限界上下文,可以使用 上下文映射图 对限界上下文进行 界分和集成;
战术上
-
实体(Entity)
-
值对象(Value Object)
-
聚合(Aggregate)
-
领域服务(Domain Service)
-
领域事件(Domain Event)
-
资源库(Repository)
下边我针对 战略和战术 两个方面进行讲解
DDD之战略
领域
广义上讲:领域 是一个组织所做的事情以及其中所包含的一切(为某个组织开发软件时,你面对的就是这个组织的 领域)。
软件开发中:领域 既可以表示 整个业务系统,也可以表示系统中的 核心域 或者 支撑子域。
在DDD中:领域 被划分为若干 子域,领域模型 在 限界上下文 中完成开发。
领域 包括下边三种 子域:
-
核心域(业务成功的主要促成因素,是企业的核心竞争力,应该给予最高的优先级、最资深的领域专家和最优秀的开发团队,实施DDD的过程中主要关注于 核心域);
-
支撑子域(不是核心,对应业务的 某些重要方面,有时我们会创建或者购买某个支撑子域);
-
通用子域(不是核心,但被整个业务系统所使用);
现实世界中的领域
现实世界中的领域包括 问题空间(Problem Space)和 解决方案空间(Solution Space):
-
问题空间:是核心域和其他子域的组合,思考的是 业务面临的挑战
-
解决方案空间:一组特定的 软件模型,包括一个或多个限界上下文,思考的是如何实现软件(限界上下文 即是一个 特定的解决方案,通过软件的方式实现解决方案)以 解决这些业务挑战
限界上下文
-
一个 显式的边界(主要是一个语义上的边界),领域模型便存在于这个边界之内;每一个模型概念(包括它的属性和操作)在边界之内都具有特殊的含义;
-
一个 给定的业务领域 会包含多个限界上下文,想与一个限界上下文沟通,则需要通过显示边界进行通信;系统通过确定的限界上下文来进行解耦,而每一个上下文内部紧密组织,职责明确,具有较高的内聚性;
-
一个很形象的隐喻:细胞质所以能够存在,是因为细胞膜限定了什么在细胞内,什么在细胞外,并且确定了什么物质可以通过细胞膜(引用);
与技术组件保持一致
将限界上下文想象成技术组件是可以的,但是技术组件并 不能来定义(是说不能定义概念?) 限界上下文,有几种做法:
-
在使用 IntelliJ IDEA 时,一个 限界上下文 通常就是一个工程项目;
-
在使用Java时,顶层包名通常表示 限界上下文中顶层模块 的名字;
-
一个团队,一个限界上下文(即便项目按分层架构模块划分,团队依然应该只工作在一个限界上下文中);
上下文映射图
确定了单个限界上下文之后,有时还需要确定多个限界上下文之间的关系,这时就需要上下文映射图
一个项目的 上下文映射图 可以用两种方式来表示:
-
画一个简单的框图来表示 两个或多个 限界上下文 之间的 映射关系(该框图表示了不同的限界上下文在 解决方案空间 中是如何通过集成相互关联的);
-
通过 限界上下文 集成的源代码实现来表示;
限界上下文界分和集成
康威定律 告诉我们,系统结构 应尽量与 组织结构 保持一致
-
这里认为团队结构(无论是内部组织还是团队间组织)就是 组织结构,限界上下文 就是 系统结构;
-
因此,团队结构 应该和 限界上下文 保持一致。
梳理清楚上下文之间的关系,从 团队内部 的关系来看,有如下好处:
-
任务更好拆分(一个开发人员可以全身心的投入到相关的一个单独的上下文中);
-
沟通更加顺畅(一个上下文可以明确自己对其他上下文的依赖关系,从而使得团队内开发直接更好的对接);
从 团队间 的关系来看,明确的上下文关系能够带来如下帮助:
-
每个团队在它的限界上下文中能够更加明确自己领域内的概念(因为限界上下文是领域的 解决方案空间);
-
对于限界上下文之间发生交互,团队与限界上下文的一致性,能够保证我们明确对接的团队和依赖的上下游;
限界上下文之间的映射关系
-
合作关系(Partnership):两个限界上下文建立起来的一种 紧密合作关系,要么一起成功,要么一起失败;
-
共享内核(Shared Kernel):两个限界上下文紧密依赖共享的 部分模型和代码;
-
客户方-供应方开发(Customer-Supplier Development):两个限界上下文有计划的 产生相互依赖(当两个团队处于上下游关系时,下游团队开发会受到上游开发的影响,上游团队计划应该估计下游团队的需求);
-
遵奉者(Conformist):下游限界上下文只能 盲目依赖 上游限界上下文的现象;
-
防腐层(Anticorruption Layer):一个限界上下文通过转换和翻译与其他的限界上下文进行交互;
-
开放主机服务(Open Host Service):定义一种协议,让其他限界上下文通过该协议对本限界上下文进行访问;
-
发布语言(Published Language):两个限界上下文之间翻译模型所需要的公用语言,通常与开放主机服务一起使用;
-
另谋他路(Separate Way):两个限界上下文之间不存在任何关系,寻找另外更简单、更专业的方法来解决问题;
-
大泥球(Big Ball of Mud):混杂在一起的、边界非常模糊的限界上下文关系;
领域/上下文划分的原则
在划分的过程中,经常纠结的一个问题是:这个模型(概念或数据)看起来放这个领域合适,放另一个也合适,如何抉择 呢?
-
依据该模型与边界内其他模型或角色 关系的紧密程度(比如,是否当该模型变化时,其他模型也需要进行变化;该数据是否通常由当前上下文中的角色在当前活动范围内使用);
-
服务边界内的 业务能力职责应单一,不是完成同一业务能力的模型不放在同一个上下文中;
-
划分的子域和服务需满足 正交原则(模块的独立性,领域名字代表的自然语言上下文保持互相独立);
-
组织中 业务部分的划分 也是一种参考(组织架构,一个业务部门的存在往往有其独特的业务价值);
简单打个比方,同一个领域上下文中的模型要保持 近亲关系,五福以内,同一血统(业务)。
DDD之战术
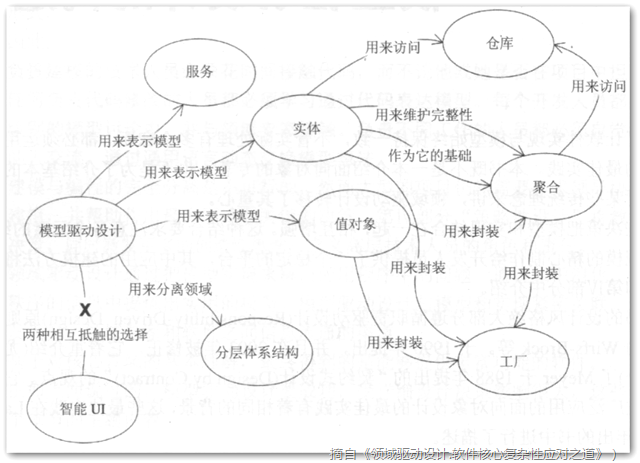
实体
当一个对象由其 唯一的身份标志 区分、具有可变的特性,这种对象即为实体。
-
实体属性的验证可以放在实体内部进行
值对象
将领域概念建模成 值对象 的时候,应该将通用语言考虑在内,这是前提。(为什么将通用语言考虑在内?值对象 是领域里的一个概念,大家要统一认知,用通用语言作为标准,可以达到共同理解的目的)
构建值对象,要了解 值对象 以下的特点:
-
它度量或者描述了 领域中的一件东西;
-
它可以作为 不变量;
-
它将不同的相关的属性组合成一个 概念整体;
-
当度量和概念改变时,可以用另一个值对象予以 替换;
-
它可以和其他值对象进行相等性 比较;
-
它不会对协作对象造成任何副作用;
在实践中,需要保证值对象创建后就不能被修改,即不允许外部再修改其属性(如:在订单上下文中如果你只关注下单时商品信息快照,那么将商品对象视为值对象是很好的选择)
聚合
-
聚合(Aggregate)是一组相关对象的集合,作为一个整体被外界访问,它由 实体 和 值对象 在 一致性边界之内 组成,聚合根(Aggregate Root)是这个聚合的根节点。
聚合的设计原则
-
在设计聚合时,我们需要慎重的考虑 一致性
-
关注聚合的 一致性边界,在一致性边界之内建模真正的 不变条件(不变条件 指的是业务规则)
-
同一个事务之内不能修改多个 聚合实例
-
-
在边界之外使用 最终一致性
-
-
设计 小聚合;(“小” 的极端意思是指 一个聚合只拥有全局标识和单个属性;这种做法不推荐)
-
通过唯一标识来引用其他聚合或实体:当存在对象之间的关联时,建议引用其唯一标识而非引用其整体对象(如果是外部上下文中的实体,引用其唯一标识或将需要的属性构造值对象)
注:如果聚合创建复杂,推荐使用 工厂方法 来屏蔽内部复杂的创建逻辑
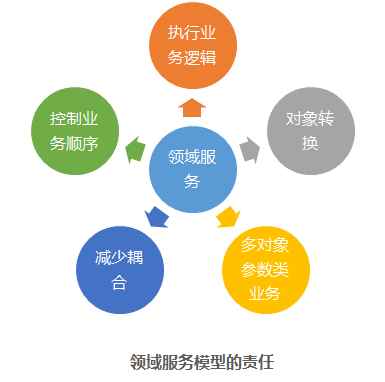
领域服务
-
当领域中的某个操作过程或转换过程不是实体或者值对象的职责时,将该操作放在一个单独的接口中,即 领域服务。
领域服务的特点
-
领域服务 和通用语言一致,表示 无状态 的操作,它用于实现特定于某个领域的任务;
-
某个操作不适合放在实体(聚合)与值对象上时,适合 领域服务;
-
执行一个显著的业务操作过程;
-
对领域对象进行转换;
-
以多个领域对象作为输入进行计算,结果产生一个值对象;
-
-
领域服务 是用来处理业务逻辑的(我们不能将业务逻辑放到应用层,即使非常简单,它依然是业务逻辑)
领域事件
-
对 领域中 所发生的事件(领域专家所关心的发生在领域中的一些事件)进行建模,即 领域事件(领域模型 的组成部分)
领域事件的特点
-
领域事件 用来捕获领域中发生的一些事情,开始使用领域事件时,要 对不同的事件进行定义;
-
“当...时,请通知我” 等等场景
领域事件发布方法
-
限界上下文内,观察者模式 是一种简单高效的发布领域事件的方法;
-
限界上下文外,利用 消息机制 将本地限界上下文产生的事件发送到 远程限界上下文 中(我们要保证 所有限界上下文 的最终一致性);
资源库
-
对领域的存储和访问进行统一管理的对象,即 资源库(Repository);
资源库的特点
-
通常我们将 聚合实例 存放在资源库中,之后再通过资源库获取相同的实例;
-
通常来说,聚合类型 和 资源库之间存在着 一对一的关系;
-
当两个或多个聚合位于同一个对象层级中时,他们可以共享同一个资源库;
-
注:资源库和 DAO是不同的,一个DAO主要从数据库表的角度来看待问题,并且提供 CRUD 操作
DDD之架构
极简化架构设计主要从下边三个角度出发:
-
业务架构:根据业务需求设计业务模块及交互关系;
-
系统架构:根据业务需求设计系统和子系统的模块;
-
技术架构:根据业务需求决定采用的技术及框架;
DDD的核心诉求 就是能够让 业务架构 和 系统架构 形成绑定关系,从而当我们去响应 业务变化 调整业务架构时,系统架构的改变是随之自发的
这个 业务变化 的结果有两个:
-
业务架构 的梳理和 系统架构 的梳理是同步渐进的,其结果是划分出的 业务上下文 和 系统模块结构 是绑定的;
-
技术架构 是解耦的,可以根据划分出来的业务上下文的系统架构选择最合适的实现技术;
架构类型
分层架构
-
所有架构的始祖,支持N层架构系统,将一个应用程序或者系统分为不同的层次
DDD使用的传统分层架构:
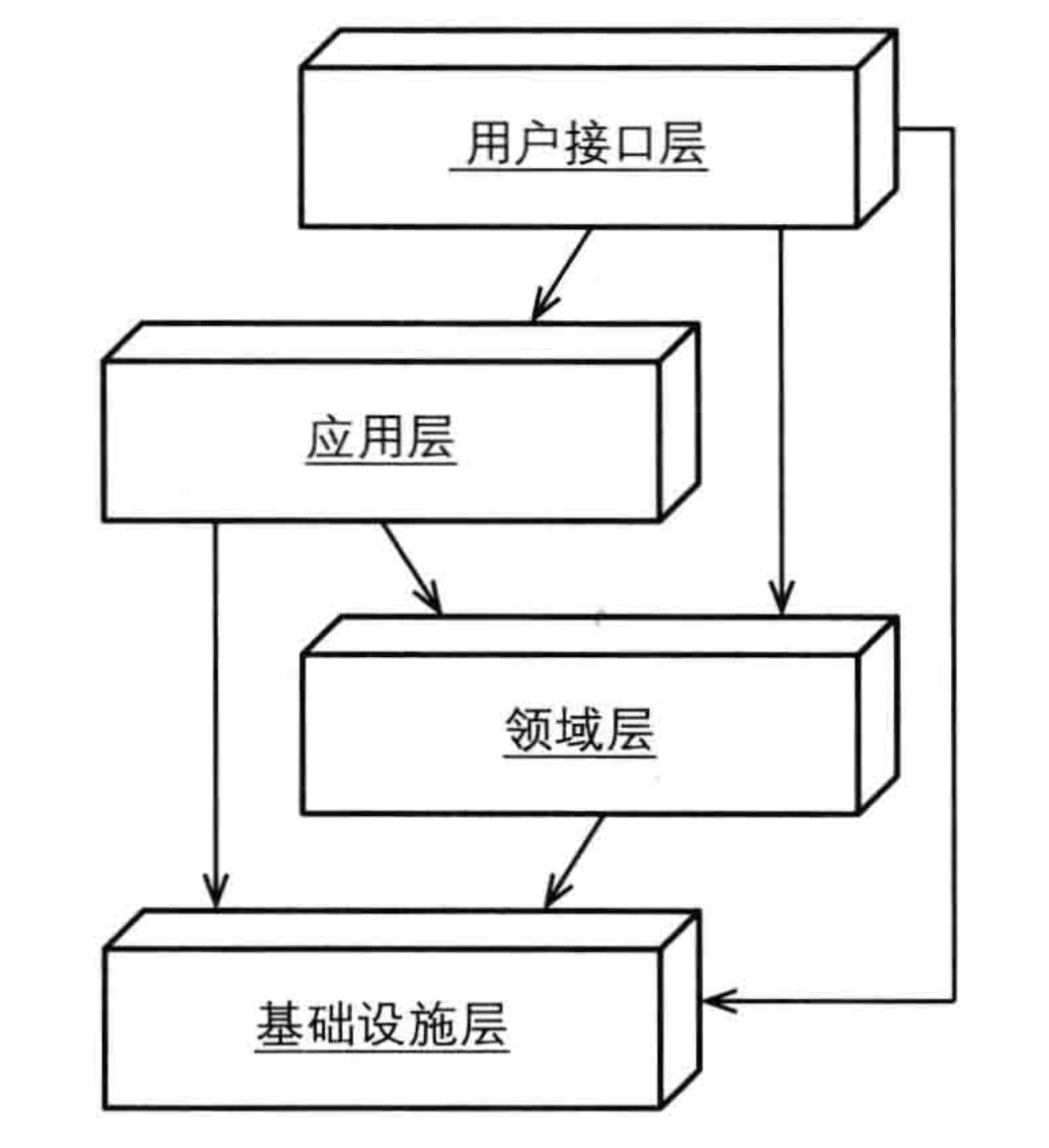
分层架构原则:每层只能与其下方的层发生耦合(分层架构 分为 严格分层架构 和 松散分层架构)。
严格分层架构:每层只能和直接位于其下方的层发生耦合。
松散分层架构:任意上方层与任意下方层发生耦合。
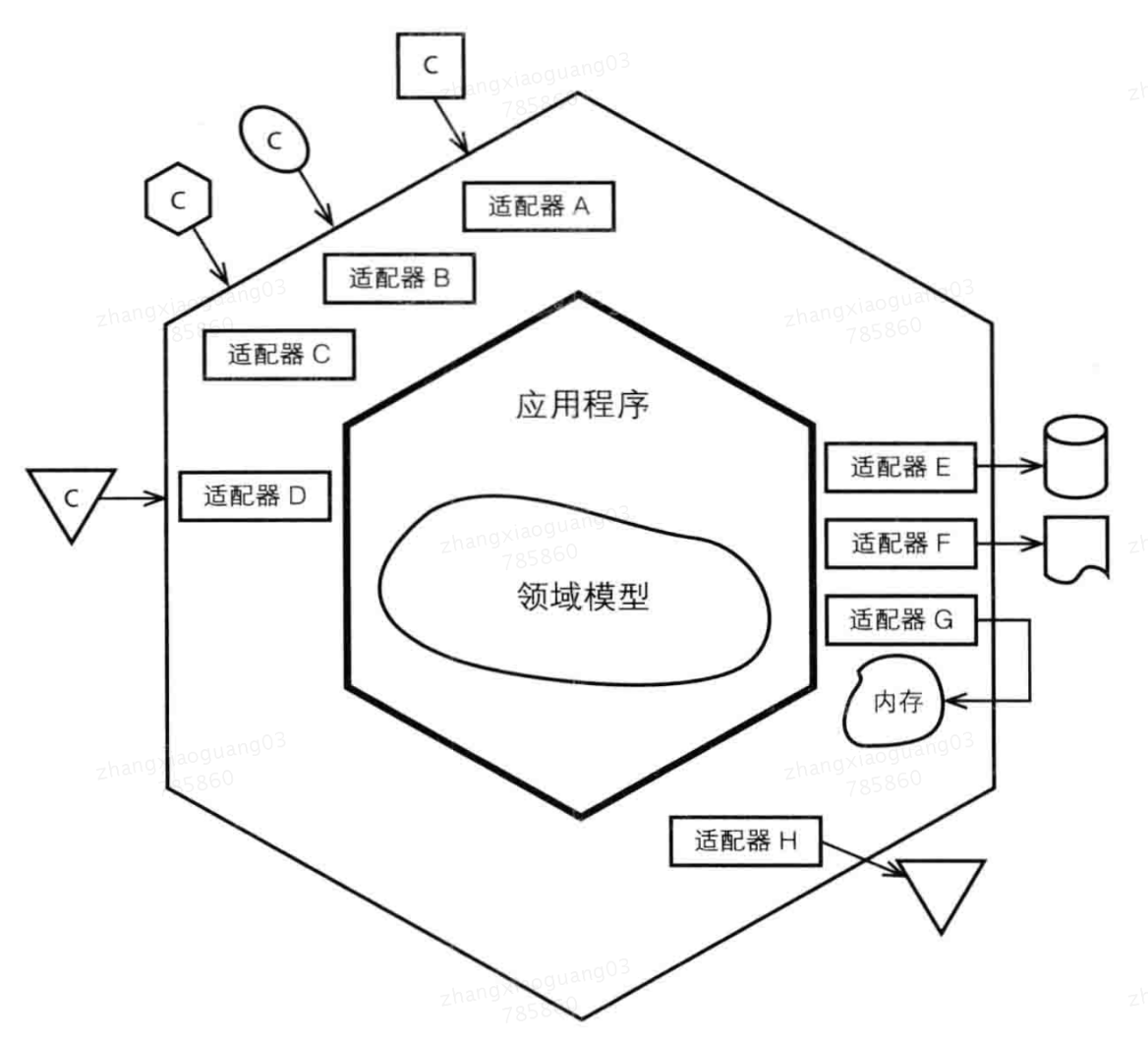
六边形架构
六边形结构(端口与适配器架构、onion架构):一种具有对称性特征的架构风格。
为什么是6边形?不是4边形或8边形?
六边形架构视角:架构中存在两个区域,“外部区域”和“内部区域”,外部区域 供给客户提交输入,内部区域 获取持久化数据、对数据进行存储或转发。
面向服务架构
服务设计原则
-
服务契约:通过契约文档,服务阐述自身的目的与功能;
-
松耦合:服务将依赖关系最小化;
-
服务抽象:服务只发布契约,隐藏内部逻辑;
-
服务重用性:一种服务可被其他所有服务重用;
-
服务自治性:服务自行控制环境与资源以保持独立性;
-
服务无状态性:服务负责消费方的状态管理;
-
服务可发现性:客户可通过服务元数据来查找服务和理解服务;
-
服务组合性:一种服务可用由其他服务组合而成,不用管其他服务的大小和复杂性如何;