发布时间:2024-03-04 04:31:26
来源:网络
.
---------------------领域驱动(DDD,Domain Driven Design)为软件设计提供了一套完整的理论指导和落地实践,通过战略设计
领域驱动(DDD,Domain Driven Design)为软件设计提供了一套完整的理论指导和落地实践,通过战略设计和战术设计,将技术实现与业务逻辑分离,来应对复杂的软件系统。本系列文章准备以实战的角度来介绍 DDD,首先编写领域驱动的代码模型,然后再基于代码模型,引入 DDD 的各项概念,先介绍战术设计,再介绍战略设计。
> DDD 实战1 - 基础代码模型 DDD 实战2 - 集成限界上下文(Rest & Dubbo)
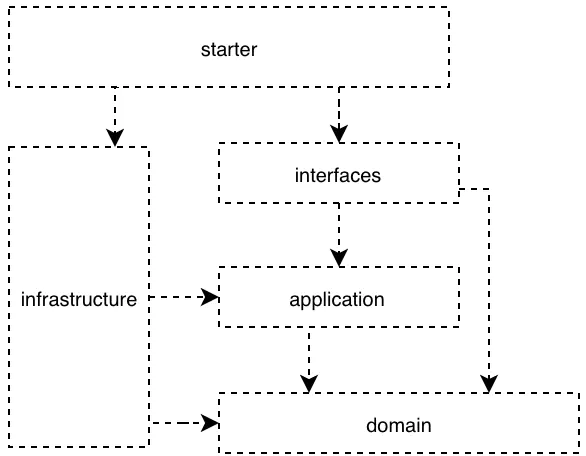
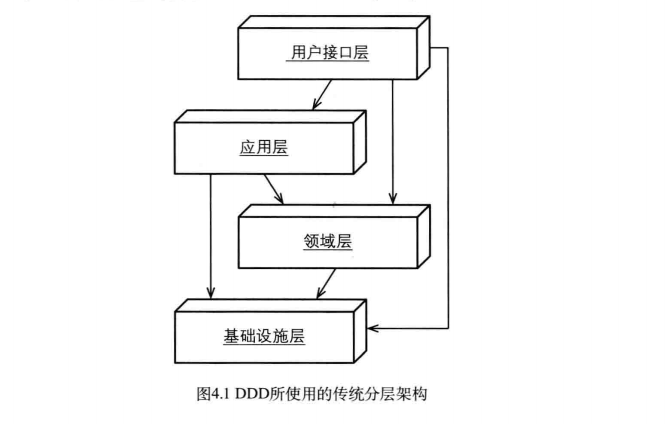
在 DDD 中,共有四层(领域层、应用层、用户接口层、基础设施层),其层级实际上是环状架构。如上图所示。根据整洁架构思想,在上述环状架构中,越往内层,代码越稳定,其代码不应该受外界技术实现的变动而变动,所以依赖关系是:外层依赖内层。按照这个依赖原则,DDD 代码模块依赖关系如下:
领域层(domain):位于最内层,不依赖其他任何层;
应用层(application):仅依赖领域层;
用户接口层(interfaces):依赖应用层和领域层;
基础设施层(infrastructure):依赖应用层和领域层;
启动模块(starter):依赖用户接口层和基础设施层,对整个项目进行启动。
DDD 各层职责
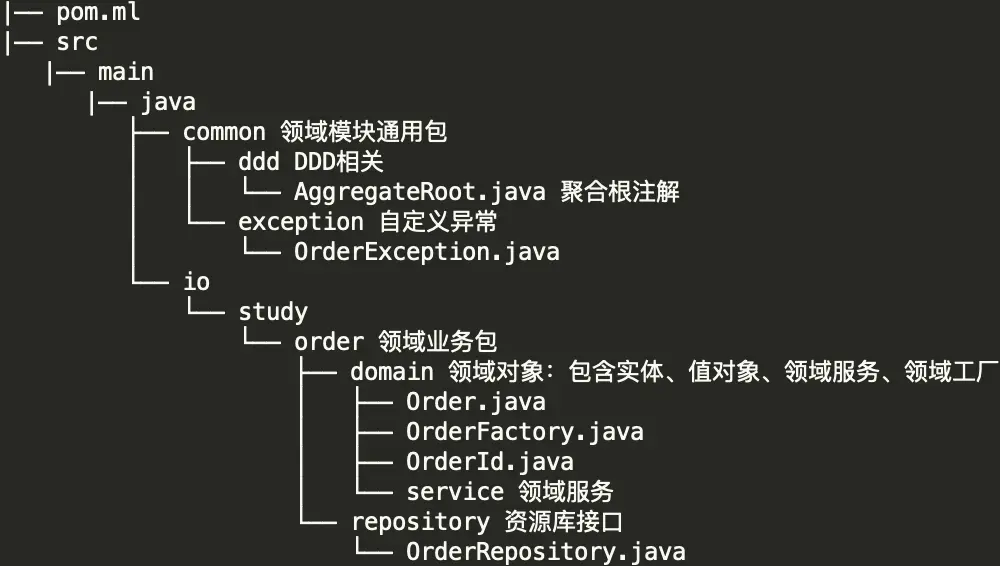
领域模型层 domain
包括实体、值对象、领域工厂、领域服务(处理本聚合内跨实体操作)、资源库接口、自定义异常等
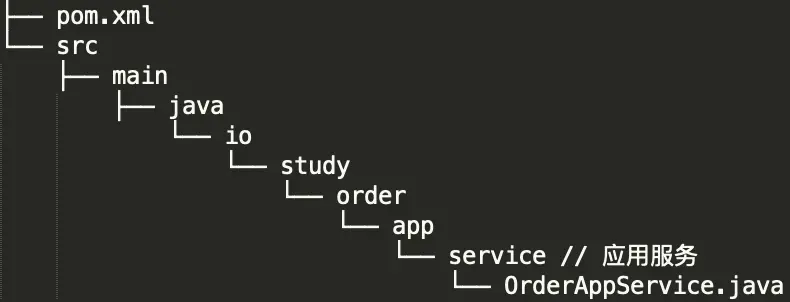
应用服务层 application
跨聚合的服务编排,仅编排聚合根。包括:应用服务等
用户接口层 interfaces
本应用的所有流量入口。包括三部分:
web 入口的实现:包括 controller、DTO 定义、DTO 转化类
消息监听者(消费者):包括 XxxListener
RPC 接口的实现:比如在使用 Dubbo 时,我们的服务需要开放 Dubbo 服务给第三方,此时需要创建单独的模块包,例如 client 模块,包含 Dubbo 接口和 DTO,在用户接口层中,去做 client 中接口的实现以及 DTO 转化类
基础设施层 infrastructure
本应用的所有流量出口。包括:
资源库接口的实现
数据库操作接口、数据库实现(如果使用mybatis,则包含 resource/*.xml)、数据库对象 DO、DO 转化类
中间件的实现、文件系统实现、缓存实现、消息实现 等
第三方服务接口的实现
基于 DDD 开发订单中心
需求:基于 DDD 开发一个订单中心,实现下订单、查询订单等功能https://github.com/zhaojigang/ordercenter
ordercenter 根模块
领域层代码模型
包依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<scope>provided</scope>
</dependency>
</dependencies>
引入 spring-boot-autoconfigure:2.4.2,在领域工厂中需要用到 Spring 注解
DDD 标识注解 common.ddd.AggregateRoot
自定义异常 common.exception.OrderException
将自定义异常放在领域层,因为 DDD 推荐使用充血模型,在领域实体、值对象或者领域服务中,也会做一些业务逻辑,在业务逻辑中,可以根据需要抛出自定义异常
资源库接口 io.study.order.repository.OrderRepository
资源库接口放置在领域层,实现领域对象自持久化,同时实现依赖反转。
依赖反转:将依赖关系进行反转,假设 Order 要做自持久化,那么需要拿到资源库的实现 OrderRepositoryImpl 才行,那么 domain 包就要依赖 infrastructure 包,但是这不符合 外层依赖内层 的原则,所以需要进行依赖反转,由 infrastructure 包依赖 domain 包。实现依赖反转的方式就是在被依赖方中添加接口(例如,在 domain 包中添加 OrderRepository 接口),依赖包对接口进行实现(infrastructure 包中对 OrderRepository 进行实现),这样的好处是,domain 可以完全仅关注业务逻辑,不要关心具体技术细节,不用去关心,到底是存储到 mysql,还是 oracle,使用的数据库框架是 mybatis 还是 hibernate,技术细节的实现由 infrastructure 来完成,真正实现了业务逻辑和技术细节的分离
资源库的命名推荐:对于资源库,推荐面向集合进行设计,即资源库的方法名采用与集合相似的方法名,例如,保存和更新是 add、addAll,删除时 remove、removeAll,查询是 xxxOfccc,例如 orderOfId,ordersOfCondition,复数使用 xxxs 的格式,而不是 xxxList 这样的格式
一个聚合具有一个资源库:比如订单聚合中,Order 主订单是聚合根,OrderItem 子订单是订单聚合中的一个普通实体,那么在订单聚合中只能存在 OrderRepository,不能存在 OrderItemRepository,OrderItem 的 CRUD 都要通过 OrderRepository 先获得 Order,再从 Order 中获取 List<OrderItem>,再做逻辑。这样的好处,保证了聚合根值整个聚合的入口,对聚合内的其他实体和值对象的方访问,只能通过聚合根,保证了聚合的封装性
领域工厂 io.study.order.factory.OrderFactory
工厂的作用:创建聚合。
创建复杂的聚合,简化客户端的使用。例如 Order 的创建需要注入资源库,订单创建后,可以直接发布订单创建事件。
可读性好(更加符合通用语言),比如 对于创建订单,createOrder 就比 new Order 的语义更加明确
更好的保证一致性,防止出错,假设创建两个主订单 Order,两个主订单下分别还要创建多个子订单 OrderItem,每个子订单中需要存储主订单的ID,如果由客户端来设置 OrderItem 中的主订单ID,可能会将A主订单的ID设置给B主订单下的子订单,可能出现数据不一致的问题,具体的示例见 《实现领域驱动》P183。
实体唯一标识 io.study.order.domain.OrderId
推荐使用强类型的对象作为实体的唯一标识,好处有两个:
唯一标识类是一个值对象,推荐值对象设置为不可变对象,使用 @lombok.Value 标注值对象,既可标识该对象为值对象,也可以是该类变为不可变类。例如,表示后的 OrderId 没有 setXxx 方法。
值对象的行为函数都是无副作用函数(即不能影响值对象本身的状态,例如 OrderId 对象被创建后,不能再使用 setXxx 修改其属性值),如果确实有属性需要变动,值对象需要整个换掉(例如,重新创建一个 OrderId 对象)
聚合根 io.study.order.domain.Order
聚合根是一个特殊的实体,是整个聚合对外的使者,其他聚合与改聚合沟通的方式只能是通过聚合根
由于使用工厂来创建 Order,那么 Order 的构造器需要设置为 protected,防止外界直接使用进行创建
实体单个属性的校验需要在 setXxx 中完成自校验
实体是可变的、具有唯一标识,其唯一标识通常需要设计成强类型
聚合中的 XxxRepository 可以通过上述的工厂进行注入,也可以使用“双委派”机制,即提供类似方法:createOrder(Order order, XxxRepository repository),然后应用层在调用该方法时,传入注入好的 repository 实例即可。但是这样的方式,提高了客户端使用的复杂性。
应用层代码模型
包依赖
<dependencies>
<dependency>
<groupId>io.study</groupId>
<artifactId>order-domain</artifactId>
<version>${project.version}</version>
</dependency>
</dependencies>
应用服务 io.study.order.app.service.OrderAppService
应用服务用于服务编排,如上述先存储订单,然后再调用库存服务减库存。(库存服务属于第三方服务,第三方服务的集成见下一小节)
基础设施层代码模型
包依赖
mapstruct 用于实现模型映射器,关于其使用见 https://www.jianshu.com/p/53aac78e7d60
数据存储采用 mysql,数据库操作框架使用 mybatis,可以看到,领域层对具体的技术实现并不关注,仅关注业务,通过 DDD 实现了技术细节与业务逻辑的解耦。
资源库实现 io.study.order.repository.impl.OrderRepositoryImpl
数据库操作接口 io.study.order.data.OrderDAO
数据库实现类 resources/mapper/OrderDAO.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="io.study.order.data.OrderDAO">
<resultMap id="BaseResultMap" type="io.study.order.data.OrderDO">
<id column="id" property="id" jdbcType="BIGINT"/>
<result column="name" property="name" jdbcType="VARCHAR"/>
</resultMap>
<sql id="Base_Column_List">
id, name
</sql>
<select id="selectByPrimaryKey" resultMap="BaseResultMap" parameterType="java.lang.Long">
select
<include refid="Base_Column_List"/>
from `order`
where id = #{id,jdbcType=BIGINT}
</select>
<insert id="insertSelective" parameterType="io.study.order.data.OrderDO">
insert into `order`
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="id != null">
id,
</if>
<if test="name != null">
name,
</if>
</trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
<if test="id != null">
#{id,jdbcType=BIGINT},
</if>
<if test="name != null">
#{name,jdbcType=VARCHAR},
</if>
</trim>
</insert>
</mapper>
数据对象
数据对象转换器 io.study.order.data.OrderDOConverter
在创建实体对象时,需要使用工厂进行创建,这样才能为实体注入资源库实现。
用户接口层代码模型
包依赖
引入 springfox-boot-starter:3.0.0 来实现自动化可测试的 Rest 接口文档
Controller io.study.order.web.OrderController
数据传输对象 io.study.order.web.dto.OrderDto
DTO 转换类 io.study.order.web.assembler.OrderDtoAssembler
转换器应该写在外层还是内层,比如 OrderDtoAssembler 是应该写在 interfaces 层,还是写在 application 层,从依赖关系来考虑:假设写在 application 层,由于 DTO 是定义在 interfaces 层,那么 application 需要依赖 interfaces,与 外层依赖内层 的原则不符,那么 DTO 是否可以写在 application 层,假设现在有个需要对外提供的 Dubbo 接口,该接口中存在的 DTO 是需要打包给第三方的,所以并不适合写在 application 层。
启动模块代码模型
包依赖
启动器 io.study.order.OrderApplication
springfox3.x 通过注解 @EnableOpenApi 来启动自动配置
配置文件 resource/application.properties
mybatis.mapper-locations=/mapper
引用第三方接口
首先介绍 ordercenter 做为消费者引用第三方接口的方式(第三方接口分别提供 Rest 和 Dubbo 两种形式),然后介绍 ordercenter 做为服务提供者为第三方提供服务接口的方式。
代码:https://github.com/zhaojigang/ordercenter
设计原则:
第三方服务的接入需要使用防腐层进行包装,进行防腐设计
第三方服务由应用服务层进行编排
第三方服务的实现由基础设施层进行实现
根据 外层依赖内层 的原则,需要将第三方服务的防腐接口和防腐模型放置在应用服务层,其实现放置在基础设施层;应用层只关心业务逻辑,不关心具体的技术实现(不关心是 Rest 服务还是 Dubbo 服务),基础设施层来关心技术细节。
应用服务层
应用服务 io.study.order.app.service.OrderAppService
第三方服务防腐接口 io.study.order.rpc.inventory.InventoryAdaptor
第三方服务防腐模型 io.study.order.rpc.inventory.InventoryDTO
基础设施层
在基础设施层,使用了 Rest 和 Dubbo 两种方式来实现了库存服务接口。分别来看下实现。
第三方服务实现 io.study.order.rpc.impl.RestInventoryAdaptorImpl
第三方服务防腐对象转换器 io.study.order.rpc.impl.RestInventoryTranslator
库存服务 Rest 实现
再来看下 Dubbo 的服务实现方式,Dubbo 的配置方式通常会有两种:xml 和注解方式。这里以注解方式进行演示。首先看库存服务提供的 Dubbo 服务。
库存服务(Dubbo 形式)
来看下在 ordercenter 引用第三方服务的姿势
第三方服务实现 io.study.order.rpc.impl.DubboInventoryAdaptorImpl
第三方服务防腐对象转换器 io.study.order.rpc.impl.DubboInventoryAdaptorImpl
基础设层包依赖
服务启动模块
这里将数据库、dubbo 的配置信息都写在了启动模块中,实际上也可以将这些配置写在他们各自使用的地方,比如可以将这些配置都写在 infrastructure 中,同时还可以将这些配置根据功能拆分成不同的配置文件,之后在启动类使用 @PropertySource 进行加载即可。
提供服务给第三方
如果仅提供 Rest 服务,那么当前的用户接口层中的 io.study.order.web.OrderController 即可。但是绝大多数情况下,需要提供类似 Dubbo 的使用方式,打成 Jar 包给第三方使用,为了避免内部逻辑泄露,以及为了打给第三方的包是一个“干净”的包,我们抽出一个单独的模块 order-client 来实现这一目的。
设计原则:
创建 order-client 模块:仅存储提供给第三方的接口和对象模型
用户接口层来实现 order-client 中的接口
领域层中需要使用 order-client 中的查询对象,所以领域层直接依赖 order-client,最终形成如下的依赖关系。
client 模块
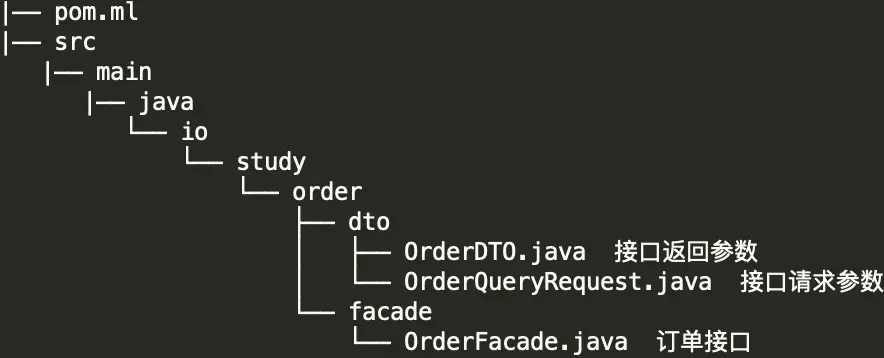
对外接口 io.study.order.facade.OrderFacade
对外接口返回模型 io.study.order.dto.OrderDTO
@Data
public class OrderDTO implements Serializable {
private static final long serialVersionUID = 8642623148247246765L;
对外接口请求参数 io.study.order.dto.OrderQueryRequest
用户接口层
Dubbo 服务的配置和启动与上述的库存服务相同,不在赘述,接下来着重看一下 OrderQueryRequest 对象的传输路径。
类:OrderFacade -> OrderFacadeImpl -> OrderRepository -> OrderRepositoryImpl
层:client -> interfaces -> domain -> infrastructure
由于 domain 中要使用到 client 定义的对象,那么 domain 要依赖 client,乍一看,不符合 外层依赖内层 的原则,实际上,在 DDD 分层模型中,是没有 client 这个模块的;另外, 外层依赖内层 原则的目的是为了保证内层的稳定性,这个稳定怎么理解?个人理解为,模块内的代码不随外界技术的变动而变动,例如,将存储从 mysql 换成了 oracle,我们仅需要处理 infrastructure 层即可,其他内层不动;在比如,当前的都是直接穿数据库的,想使用 Cache Aside Pattern 加一层缓存,那么仅需要在 infrastructure 资源库的实现中进行修改即可,内层逻辑不应该动。但是现在如果是业务本身就发生了变化,那么内部的模型除了部分可以使用开闭设计避免变动时,大部分情况下还是要动的,不管是 application 还是 domain 层,client 被 domain 依赖就是这个道理,假设 domain 不依赖 client,那么我们需要在 domain 层也一模一样的设计一个查询模型,然后在用户接口层进行转换即可,这样也是可以实现的,但是必要性是否有,可以考虑一下。