前言
随着年底考核的结束,团队也走了不少人,我没有做过多的挽留,因为我无法在他们年轻的时候给予他们更多的价值和成长,祝他们更好。接下来陆陆续续地面试了几个新人,我非常小心翼翼,我唯一能告诉他们的是我们的产品梦和技术梦,在90后组成的团队里面,我不希望琐碎的管理与他们的技术梦相冲撞,极力反对没有实践意义的日常工作,最近这三个月,因为莫名奇妙管理方式的改变,团队的创新似乎丢失了,同样也在这三个月,我努力忘记自己的情绪,带领团队回到正轨,领域驱动设计在这样的背景下应运而生了。
这篇文章假设你已经初步了解过领域驱动设计(DDD)的基本概念(聚合根、实体、值对象、领域服务、领域事件、资源库、限界上下文等)以及CQRS的设计,本文会将重点放在如何落地DDD和CQRS上。
DDD分层架构
Evans在它的《领域驱动设计:软件核心复杂性应对之道》书中推荐采用分层架构去实现领域驱动设计:
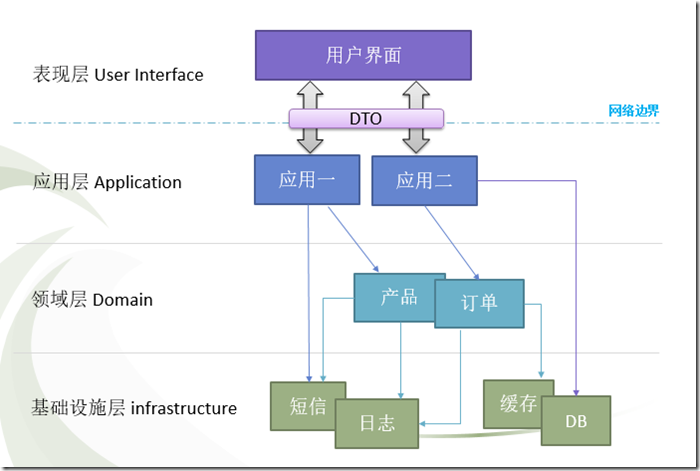
其实这种分层架构我们早已驾轻就熟,MVC模式就是我们所熟知的一种分层架构,我们尽可能去设计每一层,使其保持高度内聚性,让它们只对下层进行依赖,体现了高内聚低耦合的思想。
分层架构的落地就简单明了了,用户界面层我们可以理解成web层的Controller,应用层和业务无关,它负责协调领域层进行工作,领域层是领域驱动设计的业务核心,包含领域模型和领域服务,领域层的重点放在如何表达领域模型上,无需考虑显示和存储问题,基础实施层是最底层,提供基础的接口和实现,领域层和应用服务层通过基础实施层提供的接口实现类如持久化、发送消息等功能。阿里巴巴开源的整洁面向对向分层架构COLA就采取了这样的分层架构来实现领域驱动。
改进DDD分层架构和DIP依赖倒置原则
DDD分层架构是一种可落地的架构,但是我们依然可以进行改进,Vernon在它的《实现领域驱动设计》一书中提到了采用依赖倒置原则改进的方案。
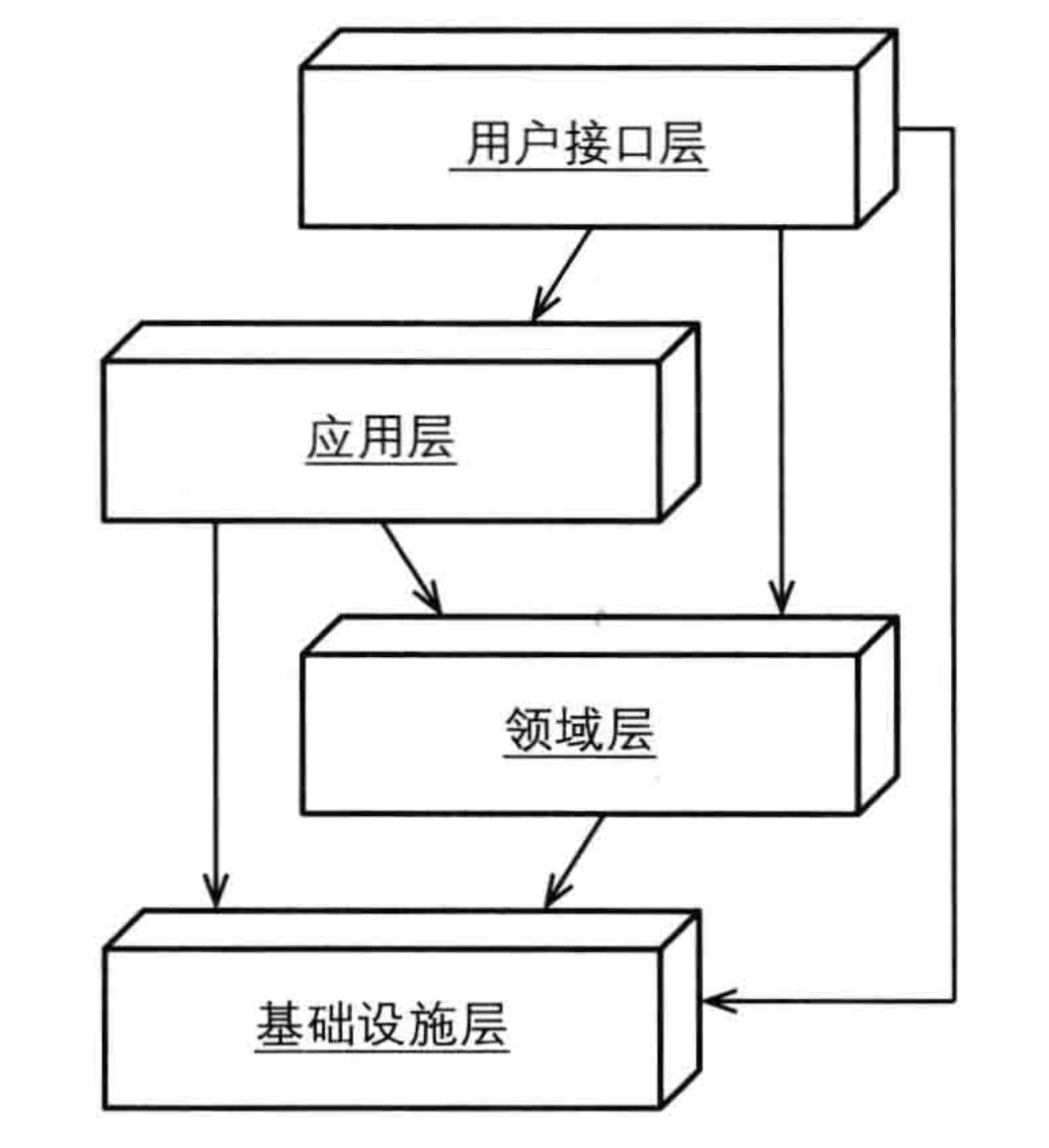
所谓的依赖倒置原则指的是:高层模块不应该依赖于低层模块,两者都应该依赖于抽象,抽象不应该依赖于细节,细节应该依赖于抽象。
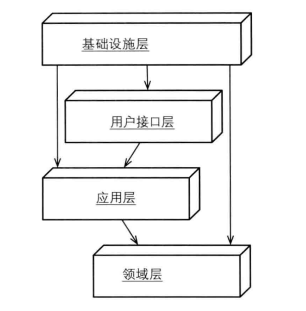
从图中可以看到,基础实施层位于其他所有层的上方,接口定义在其它层,基础实施实现这些接口。依赖原则的定义在DDD设计中可以改述为:领域层等其他层不应该依赖于基础实施层,两者都应该依赖于抽象,具体落地的时候,这些抽象的接口定义放在了领域层等下方层中。这也就是意味着一个重要的落地指导原则: 所有依赖基础实施实现的抽象接口,都应该定义在领域层或应用层中。
采用依赖倒置原则改进DDD分层架构除了上面说的DIP的好处外,还有什么好处吗?其实这种分层结构更加地高内聚低耦合。每一层只依赖于抽象,因为具体的实现在基础实施层,无需关心。只要抽象不变,就无需改动那一层,实现如果需要改变,只需要修改基础实施层就可以了。
采用依赖倒置原则的代码落地中,资源库Repository的抽象接口定义就会放在领域层了,下文会再阐述如何落地Repository。
六边形架构、洋葱架构、整洁架构
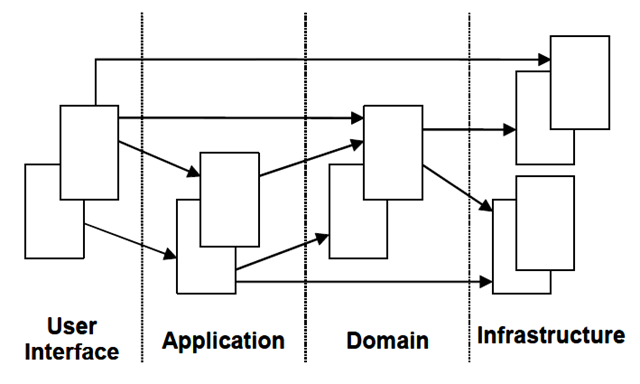
《实现领域驱动设计》一书中提到了DDD架构更深层次的变化,Vernon放弃了分层架构,采用了对称性架构:六边形架构,作者认为这是一种具有持久生命力的架构。当你真正理解这种架构的时候,相信你也不得不佩服这种角度不同的设计。
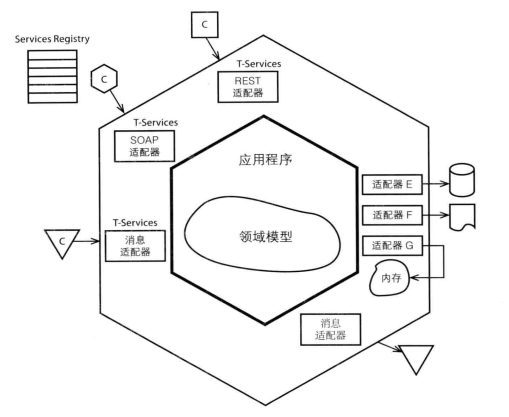
如上图,在这种架构风格中,外部客户和内部系统的交互都会通过端口和适配器完成转换,这些外部客户之间是平等的,比如用户web界面和数据库持久化,当你需要一个新的外部客户时,只需要增加相应的适配器,比如当我们增加外部一个RPC的服务时,只需要编写对应的适配器即可。
好吧,当将web界面和持久化统称在一起,没有前端和数据库后端之分的时候,这种观察架构的角度已经打动到了我。
那么适配器在各种外部客户的场景下时什么呢?如果外部客户时HTTP请求,那么SpringMVC的注解和Controller构成了适配器,如果外部客户时MQ消息,那么适配器就是MQConsumer监听器,如果外部客户时数据库,那么适配器可能就是Mybatis的Mapper。
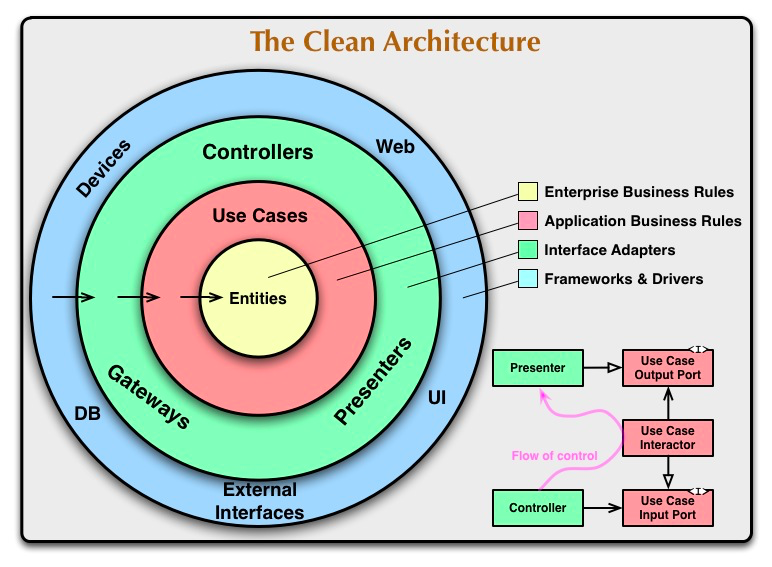
随着架构的演化,后来又提出了洋葱架构和整洁架构,这些架构大同小异,它们都只允许外层依赖内层,不允许内层知道外层的细节,下图是整洁架构图,详细介绍这里就不作赘述,可以参考这篇文章:The Clean Architecture。
SIDE-EFFECT-FREE模式和CQRS架构落地
SIDE-EFFECT-FREE模式被称为无副作用模式,熟悉函数时编程的朋友都知道,严格的函数就是一个无副作用的函数,对于一个给定的输入,总是返回固定的结果,通常查询功能就是一个函数,命令功能就不是一个函数,它通常会执行某些修改。
在DDD架构中,通常会将查询和命令操作分开,我们称之为CQRS(命令查询的责任分离Command Query Responsibility Segregation),具体落地时,是否将Command和Query分开成两个项目可以看情况决定,大多数情况下放在一个项目可以提高业务内聚性,下面这张图是来自
Martin Fowler的文章:CQRS。
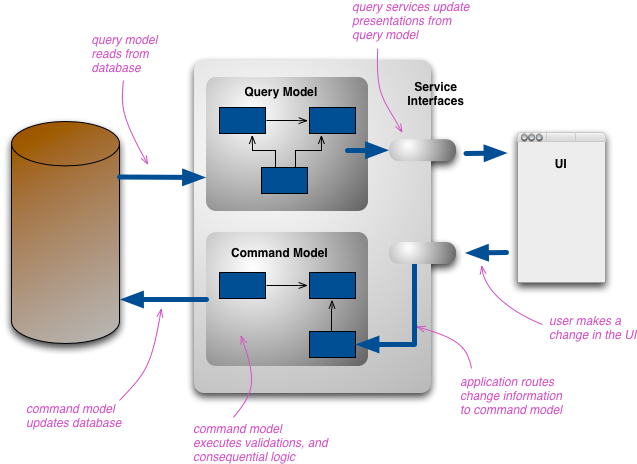
这张图读写只是逻辑分离,物理层面还是使用了一个数据库,我们可以将数据库改成读库和写库做到物理分离,这时候就需要同步都写库,业界的解决方案是当写库发生更改时,通过Event事件机制通知读库进行同步。
最终CQRS落地的方案我们选择了简单化处理,物理层面还是使用一个数据库,查询的时候部分数据直接从数据库读取,部分数据使用到了Elasticsearch,当数据库发生更改时,会发送Event事件通知ES进行更新。当然我们还可以更加技术的处理这种同步,我们可以去除事件,直接监听Mysql的binlog更新ES,而我们也正是这样做的。
DDD、CQRS架构落地
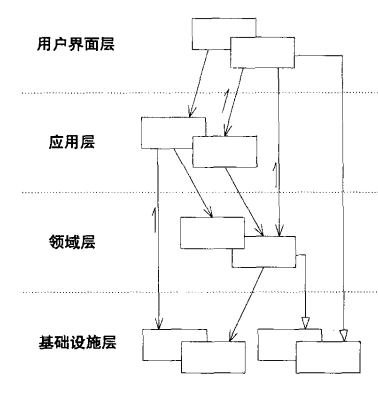
根据上面的分析,最终落地的DDD+CQRS的架构使用了对称性架构,如下图所示:
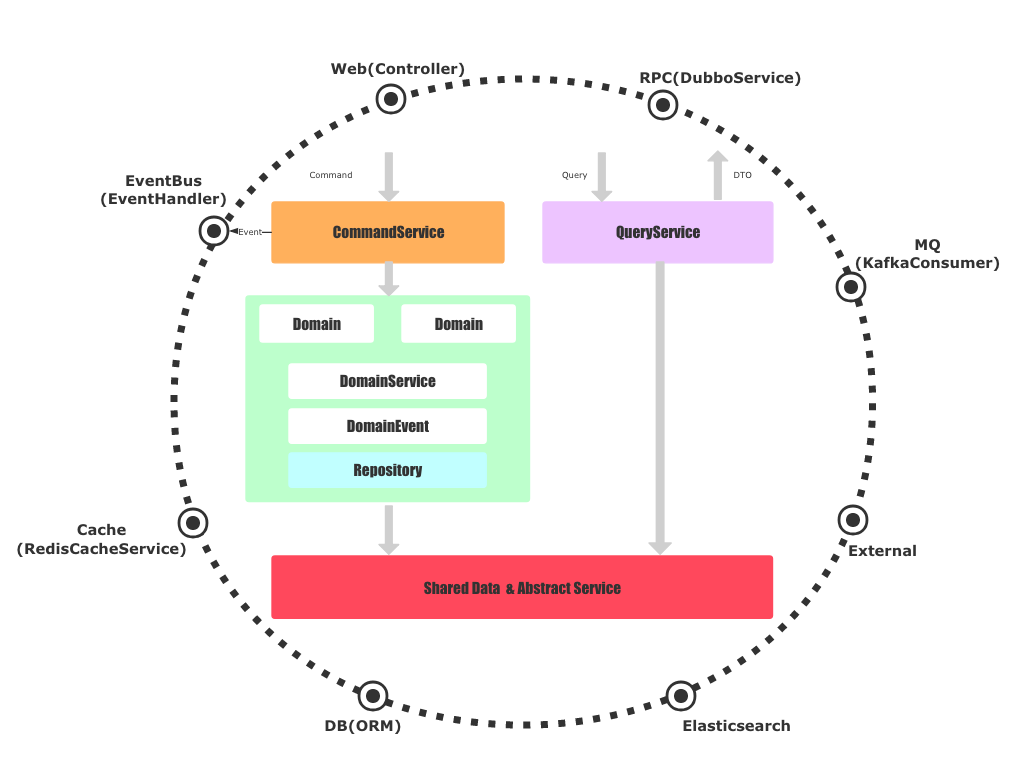
架构中,我们平等的看待Web、RPC、DB、MQ等外部服务,基础实施依赖圆圈内部的抽象。
当一个命令Command请求过来时,会通过应用层的CommandService去协调领域层工作,而一个查询Query请求过来时,则直接通过基础实施的实现与数据库或者外部服务交互。再次强调,我们所有的抽象都定义在圆圈内部,实现都在基础设施。
在具体落地中我们发现,Query和Command的有一些数据和抽象服务是公用的,因此我们抽出了一个新的模块:Shared Data & Service,这个模块的功能为公用的数据对象和抽象接口。
DDD、CQRS代码落地
分析DDD架构的方法论有很多,但是落地到代码层面的方法论少之又少,这一小节我们将具体到DDD设计的每个小点来阐述如何代码落地,下图中代码模块的组织正好对应了架构的设计。
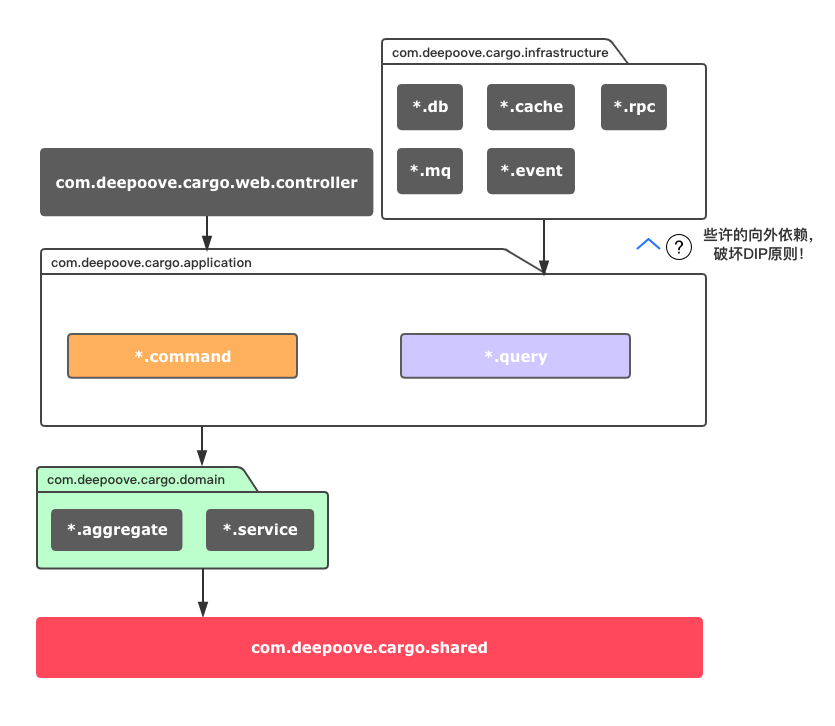
Web放在了模块com.deepoove.cargo.web.controller中,实现一些Controller,infrastructure放在了com.deepoove.cargo.infrastructure中,抽象接口的实现。它们都依赖于应用服务和领域模型。
落地用户界面com.deepoove.cargo.web.controller
Controller作为六边形架构中与HTTP端口的适配器,起到了适配请求,委托应用服务处理的任务。对称性架构的好处就在于,当增加新的用户的界面时我们可以创建一个新包去承载适配器(比如为暴露RPC服务创建com.deepoove.cargo.remoting包),然后调用应用层的服务。这里我们有一个规范:所有查询的条件封装成XXXQry对象,所有命令的请求封装成XXXCommand对象。
package com.deepoove.cargo.web.controller;
@RestController
@RequestMapping("/cargo")
public class CargoController {
@Autowired
CargoQueryService cargoQueryService;
@Autowired
CargoCmdService cargoCmdService;
@RequestMapping(value = "/{cargoId}", method = RequestMethod.GET)
public CargoDTO cargo(@PathVariable String cargoId) {
return cargoQueryService.getCargo(cargoId);
}
@RequestMapping(method = RequestMethod.POST)
public void book(@RequestBody CargoBookCommand cargoBookCommand) {
cargoCmdService.bookCargo(cargoBookCommand);
}
@RequestMapping(value = "/{cargoId}/delivery", method = RequestMethod.PUT)
public void modifydestinationLocationCode(@PathVariable String cargoId,
@RequestBody CargoDeliveryUpdateCommand cmd) {
cmd.setCargoId(cargoId);
cargoCmdService.updateCargoDelivery(cmd);
}
}
我们考虑校验逻辑应该放到哪一层的时候确定这一层代码可以有请求参数的基本校验,但是 应用服务的校验逻辑是必须存在的,校验和应用服务的耦合是紧密的。
落地应用服务com.deepoove.cargo.application.command
com.deepoove.cargo.application.command包里面是具体CommandService的抽象和实现,它将协调领域模型和领域服务完成业务功能,此处不包含任何逻辑。我们认为应用服务的每个方法与用例是一一对应的,典型的处理流程是:
- 校验
- 协调领域模型或者领域服务
- 持久化
- 发布领域事件
在这一层可以使用流程编排,典型的流程也可以使用技术手段固化,比如抽象模板模式。
package com.deepoove.cargo.application.command.impl;
@Service
public class CargoCmdServiceImpl implements CargoCmdService {
@Autowired
private CargoRepository cargoRepository;
@Autowired
DomainEventPublisher domainEventPublisher;
@Override
public void bookCargo(CargoBookCommand cargoBookCommand) {
// create Cargo
DeliverySpecification delivery = new DeliverySpecification(
cargoBookCommand.getOriginLocationCode(),
cargoBookCommand.getDestinationLocationCode());
Cargo cargo = Cargo.newCargo(CargoDomainService.nextCargoId(), cargoBookCommand.getSenderPhone(),
cargoBookCommand.getDescription(), delivery);
// saveCargo
cargoRepository.save(cargo);
// post domain event
domainEventPublisher.publish(new CargoBookDomainEvent(cargo));
}
@Override
public void updateCargoDelivery(CargoDeliveryUpdateCommand cmd) {
// validate
// find
Cargo cargo = cargoRepository.find(cmd.getCargoId());
// domain logic
cargo.changeDelivery(cmd.getDestinationLocationCode());
// save
cargoRepository.save(cargo);
}
}
我们再看看应用服务的代码发现,发布领域事件的动作放在了应用层没有放在领域层,而领域事件的定义是在领域层(紧接着会提到),这是为什么呢?如果 不考虑持久化,发布领域事件的确应该在领域模型中,但是在代码落地时,考虑到持久化完成后才代表有了真实的事件,所以我们将触发事件的代码放到了资源库后面。
落地领域模型com.deepoove.cargo.domain.aggregate
我们采用了aggregate而不是model,是为了将聚合根的概念显现出来,每个聚合根单独成一个子包,在单个聚合根中包含所需要的 值对象、领域事件的定义、资源库的抽象接口等,这里解释下为什么这些对象会在领域模型中,因为它们更能体现这个领域模型,而且资源库的抽象和聚合根有着对应的关系(不大于聚合根的数量)。
package com.deepoove.cargo.domain.aggregate.cargo;
import com.deepoove.cargo.domain.aggregate.cargo.valueobject.DeliverySpecification;
public class Cargo {
private String id;
private String senderPhone;
private String description;
private DeliverySpecification delivery;
public Cargo(String id) {
this.id = id;
}
public Cargo() {}
/**
* Factory method:预订新的货物
*
* @param senderPhone
* @param description
* @param delivery
* @return
*/
public static Cargo newCargo(String id, String senderPhone, String description,
DeliverySpecification delivery) {
Cargo cargo = new Cargo(id);
cargo.senderPhone = senderPhone;
cargo.description = description;
cargo.delivery = delivery;
return cargo;
}
public void changeDelivery(String destinationLocationCode) {
if (this.delivery
.getOriginLocationCode().equals(destinationLocationCode)) { throw new IllegalArgumentException(
"destination and origin location cannot be the same."); }
this.delivery.setDestinationLocationCode(destinationLocationCode);
}
public void changeSender(String senderPhone) {
this.senderPhone = senderPhone;
}
}
特别提醒的是,聚合根对象的创建不应该被Spring容器管理,也不应该被注入其它对象。我们注意到聚合根对象可以通过静态工厂方法Factory Method来创建,下文还会介绍如何落地资源库Repository进行聚合根的创建。
落地领域服务com.deepoove.cargo.domain.service
很多朋友无法判断业务逻辑什么时候该放在领域模型中,什么时候放在领域服务中,可以从以下几点考虑:
- 不是属于单个聚合根的业务或者需要多个聚合根配合的业务,放在领域服务中,注意是业务,如果没有业务,协调工作应该放到应用服务中
- 静态方法放在领域服务中
- 需要通过rpc等其它外部服务处理业务的,放在领域服务中
package com.deepoove.cargo.domain.service;
@Service
public class CargoDomainService {
public static final int MAX_CARGO_LIMIT = 10;
public static final String PREFIX_ID = "CARGO-NO-";
/**
* 货物物流id生成规则
*
* @return
*/
public static String nextCargoId() {
return PREFIX_ID + (10000 + new Random().nextInt(9999));
}
public void updateCargoSender(Cargo cargo, String senderPhone, HandlingEvent latestEvent) {
if (null != latestEvent
&& !latestEvent.canModifyCargo()) { throw new IllegalArgumentException(
"Sender cannot be changed after RECIEVER Status."); }
cargo.changeSender(senderPhone);
}
}
落地基础设施com.deepoove.cargo.infrastructure
基础设施可以对抽象的接口进行实现,上文中说到资源库Repository的接口定义在领域层,那么在基础设施中就可以具体实现这个接口。
package com.deepoove.cargo.infrastructure.db.repository;
@Component
public class CargoRepositoryImpl implements CargoRepository {
@Autowired
private CargoMapper cargoMapper;
@Override
public Cargo find(String id) {
CargoDO cargoDO = cargoMapper.select(id);
Cargo cargo = CargoConverter.deserialize(cargoDO);
return cargo;
}
@Override
public void save(Cargo cargo) {
CargoDO cargoDO = CargoConverter.serialize(cargo);
CargoDO data = cargoMapper.select(cargoDO.getId());
if (null == data) {
cargoMapper.save(cargoDO);
} else {
cargoMapper.update(cargoDO);
}
}
}
资源库Repository的实现就是将聚合根对象持久化,往往聚合根的定义和数据库中定义的结构并不一致,我们将数据库的对象称为数据对象DO,当持久化时就需要将聚合根 序列化 成数据库数据对象,通过资源库获取(构造)聚合根时,也需要 反序列化 数据库数据对象。
我们可以基于反射或其它技术手段完成序列化和反序列化操作,这样可以避免聚合根中编写过多的getter和setter方法。
落地查询服务com.deepoove.cargo.application.query
application应用服务包含了commond和query两个子包,其实query可以提取出去和application平级,但是这两种做法没有对错,只是选择问题。
CQRS中查询服务不会调用应用服务,也不会调用领域模型和资源库Repository,它会直接查询数据库或者ES获取原始数据对象DO,然后组装成数据传输对象DTO给用户界面,这个组装的过程称为Assembler,由于与用户界面有一定的对应关系,所以Assembler放在查询服务中。
那么问题来了,查询服务中如何获取DO呢?通常的做法是在查询模块中定义抽象接口,由基础设施实现从数据库获取数据 ,但是DO的定义不是在基础设施层吗,查询服务怎么可以访问到这些对象呢?我们有两个办法:
- 查询服务中定义一套一摸一样的DO,然后基础设施做转换,缺点是有点复杂,冗余了DO,优点是完美符合DIP原则:抽象在查询服务中,实现在基础设施。
- 将DO放到shared Data & Service中去,这样就只要一套DO供查询服务和命令服务使用,查询服务定义接口,基础设施实现接口
具体落地我们发现方法1太复杂了,方法2和mybatis结合会产生疑惑,因为mybatis Mapper就是一个接口,何须在查询服务中再定义一套接口呢?最终落地的代码在查询服务和DB交互时 破坏了DIP原则,直接依赖Mapper读取数据对象进行组装。
我们来看看一个查询服务的实现,其中CargoDTOAssembler是一个组装器:
package com.deepoove.cargo.application.query.impl;
@Service
public class CargoQueryServiceImpl implements CargoQueryService {
@Autowired
private CargoMapper cargoMapper;
@Autowired
private CargoDTOAssembler converter;
@Override
public List<CargoDTO> queryCargos() {
List<CargoDO> cargos = cargoMapper.selectAll();
return cargos.stream().map(converter::apply).collect(Collectors.toList());
}
@Override
public List<CargoDTO> queryCargos(CargoFindbyCustomerQry qry) {
List<CargoDO> cargos = cargoMapper.selectByCustomer(qry.getCustomerPhone());
return cargos.stream().map(converter::apply).collect(Collectors.toList());
}
@Override
public CargoDTO getCargo(String cargoId) {
CargoDO select = cargoMapper.select(cargoId);
return converter.apply(select);
}
}
是否需要将每个对象都转化成DTO返回给用户界面这个要看情况,个人认为当DO能满足界面需求时是可以直接返回DO数据的。
落地MQ、Event、Cache等
毫无疑问,MQ、Event、Cache的实现都应该在基础设施层,它们接口的定义放在哪里呢?一个方案是哪一层使用了抽象就在那一层定义接口,另一个方案是放到一个共有的抽象包下,基础设施和对应层依赖这个共有的抽象包。
最终落地我选择将这些接口放在了com.deepoove.cargo.shared包下,这个包的定义就是共有的数据和抽象。
我们以领域事件为例来看看代码如何实现,首先定义抽象接口com.deepoove.cargo.shared.DomainEventPublisher:
package com.deepoove.cargo.shared;
public interface DomainEventPublisher {
public void publish(Object event);
}
然后在基础实施中实现,具体实现采用guava的Eventbus方案:
package com.deepoove.cargo.infrastructure.event;
@Component
public class GuavaDomainEventPublisher implements DomainEventPublisher {
@Autowired
EventBus eventBus;
public void publish(Object event) {
eventBus.post(event);
}
}
发送事件的代码已经落地,那么监听事件的代码应该如何落地了呢?同样的,监听MQ的代码如何落地呢?按照架构图的指导,这些 监听器都应该充当着适配器的作用,所以它们的落地都应该放在基础设施层。
我们来看看具体监听器的实现:
package com.deepoove.cargo.infrastructure.event.comsumer;
@Component
public class CargoListener {
@Autowired
private CargoCmdService cargoCmdService;
@Autowired
private EventBus eventBus;
@PostConstruct
public void init(){
eventBus.register(this);
}
@Subscribe
public void recordCargoBook(CargoBookDomainEvent event) {
// invoke application service or domain service
}
}
监听器的基本流程就是适配领域事件,然后调用应用服务去处理。
落地RPC和防腐层
前面提到过,当我们暴露一个RPC服务时和web层是平等对待的,比如暴露一个dubbo协议的服务就和暴露一个http的服务是平等的。这一小节我们将来探讨如何与第三方系统的RPC服务进行交互。
这里涉及到DDD中Bounded Context和Context Map的概念,在领域驱动设计中,限界上下文之间是不能直接交互的,它们需要通过Context Map进行交互,在微服务足够细致的年代,我们可以做到一个微服务就代表着一个限界上下文。
当我们与第三方系统RPC交互时,就要考虑如何设计Context Map,典型的模式有Shared Kernel共享内核模式和Anti-corruption防腐层模式,最终落地时我们选择了防腐层模式,它的结构如下图(图来自《实现领域驱动设计》一书)所示:
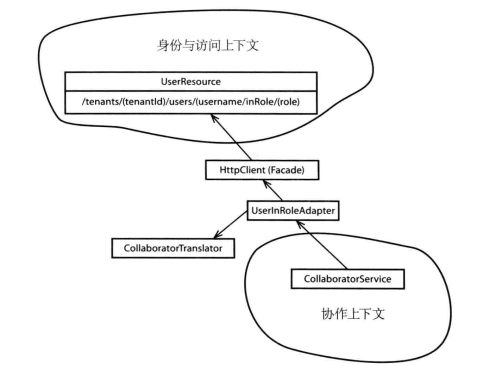
图中Adapter就是适配器,通用做法会再创建一个Translator实现上下文模型之间的翻译功能。
在看具体代码落地前还有一个问题需要强调,其它限界上下文的模型在我们系统中并不是一个模型实体,而是一个值对象,很显然Adapter应该放在基础设施层中,那么这个值对象存放在哪里呢?
我们可以将值对象和抽象接口定义在领域层,然后基础设施通过适配器和翻译器实现抽象接口,很明显这个做法是非常可取的。在具体落地时我们发现,这些值对象可能同时又被查询服务依赖,所以值对象和抽象接口定义在shared Data & Service中也是可取的,具体放在那里因看法而异。
接下来我们来看看适配器的基本实现,其中RemoteServiceTranslator起到了模型之间翻译的作用。
package com.deepoove.cargo.infrastructure.rpc.salessystem;
@Component
public class RemoteServiceAdapter {
@Autowired
private RemoteServiceTranslator translator;
// @Autowired
// remoteService
public UserDO getUser(String phone) {
// User user = remoteService.getUser(phone);
// return this.translator.toUserDO(user);
return null;
}
public EnterpriseSegment deriveEnterpriseSegment(Cargo cargo) {
// remote service
// translator
return EnterpriseSegment.FRUIT;
}
}
Cargo货物实例和源码
落地代码实现了一个简单的货运系统,主要功能包括预订货物、修改货运信息、添加货运事件和追踪货运物流信息等,具体源码参见:GitHub:https://github.com/Sayi/ddd-cargo
参考资料
在整个落地过程中,每次阅读《领域驱动设计》和《实现领域驱动设计》这两本书都会给我带来新的想法,值得推荐。
The Clean Architecture
DDD, Hexagonal, Onion, Clean, CQRS
dddsample-core
总结
所有的落地代码都是当前的想法,它一定会变化,架构和设计有魅力的地方就在于它会不断的变迁和升级,我们会不断丰富在领域驱动设计中的代码落地,也欢迎在评论中与我探讨DDD相关的话题。