互联网2024年3月20日报道丨AI资讯早报
奥特曼评价GPT-4:“有点糟糕”
当地时间3月19日报道,OpenAI CEO奥特曼本周作客科技博主Lex Fridman 的访谈中表示,一年前上线的GPT-4 其实“有点糟糕(kind sucks)”,阿尔特曼更期待即将到来的 GPT-5 能够真正配得上大家的期待。

当被问及 GPT-4 及其最令人印象深刻的能力时,他说道,“展望未来几年,我们应该意识到我们现在拥有的工具将来看来会非常落后,这正是鞭策我们不断进步、创造更美好的未来的动力。”“别误会,我既不想贬低 GPT-4 的成就,也不想夸大其词,”奥特曼说,“正因我们正处于指数级发展的曲线上,所以很快我们就会像现在看待 GPT-3 一样看待 GPT-4。”
奥特曼还认为,GPT-4的确存在“令人惊鸿一瞥的闪光点”,但他指出,ChatGPT 在处理复杂的多步骤问题时几乎没什么用处。令他感到”神奇“的情况少之又少。
Stability AI推出3D渲染视频模型Stable Video 3D
知名开源大模型公司Stability AI又上新了!当地时间3月18日,该公司网站发布用于渲染3D视频的生成式AI视频工具Stable Video 3D(SV3D)。
据了解,Stability AI一直在开发其Stable Video技术的视频功能,使用户能够从图像或文本提示生成短视频。SV3D在Stability AI之前的Stable Video Diffusion模型的基础上进行了改进,适用于新视角合成任务(Novel View Synthesis) 和3D生成的任务。


通过SV3D,Stability AI通过能够根据单一输入图像创建和转换多视图3D网格,为其视频生成模型增加了新的深度。
在去年12月,Stability AI曾经推出Stable Zero123三维建模模型,该模型基于Stable Diffusion开发,并且一次输出一张图像。SV3D基于Stable Video Diffusion模型,并且同时输出多个新视角,而这也是SV3D的关键优势。根据Stability AI的说法,SV3D能够从任何给定角度提供连贯的视角。
SV3D现已可供商业使用,订阅Stability AI Professional的会员每月20美元(对于年收入不到100万美元的创作者和开发者)。该模型最低的显卡运行要求为英伟达GeForce RTX 4090及以上。
谷歌推出多模态视频模型VLOGGER AI:让人物肖像会“说话”

近日,谷歌在其 GitHub 页面发布博文介绍一款名为 VLOGGER AI 的新模型,用户只需要输入一张肖像照片和一段音频内容,该模型可以让这些人物“动起来”,富有面部表情地朗读音频内容。
项目主页:

VLOGGER AI 是一种适用于虚拟肖像的多模态 Diffusion 模型,使用 MENTOR 数据库进行训练,该数据库中包含超过 80 万名人物肖像,以及累计超过 2200 小时的影片,从而让 VLOGGER 生成不同种族、不同年龄、不同穿着、不同姿势的肖像影片。
研究人员表示:“和此前的多模态模型相比,VLOGGER AI 的优势在于不需要对每个人进行训练,不依赖于人脸检测和裁剪,可以生成完整的图像(而不仅仅是人脸或嘴唇),并且考虑了广泛的场景(例如可见躯干或不同的主体身份),这些对于正确合成交流的人类至关重要”。
Unity调查:超六成游戏工作室正在采用AI技术开发
根据游戏渲染引擎 Unity 的调查显示,超过六成(62%)的游戏工作室在其项目开发过程中会利用人工智能的辅助,这些工具通常被用于节省时间和提高效率。
在 2022 年,一款游戏制作的平均周期为 218 天,而现在则增加到了 304 天。然而,参与调查的工作室中有 71% 表示人工智能帮助他们提升了工作质量,从理论上讲,游戏的平均质量得到了长足进步。动画角色是最常使用人工智能进行创作的部分,其次是协助编写代码。接下来是创建插图和关卡、编写脚本以及测试游戏。

根据 68% 的受访者反馈,使用人工智能的主要原因是为了减少制作原型的时间。2023 年,96% 的工作室在原型开发上花费的时间不到三个月,而一年前这一比例仅为 85%。另一个 AI 应用领域是世界构建,有 56% 的工作室使用 AI 进行这一部分的工作。在这些工作室中,有 64% 利用 AI 创建了非玩家角色 (NPC) 来填充游戏世界。
YouTube宣布,AI生成的视频内容务必进行标注
YouTube 日前宣布,即日起视频内容创作者在该平台上传、发布视频时,都需要标注“篡改或合成”的写实逼真内容,包括应用了生成式 AI 技术进行视频内容制作与剪辑。

YouTube 官方将「逼真内容」定义为“任何观众容易误认为是真实的人事物或地点”的内容。若视频创作者使用真人声音的合成版本来为视频配音,或发布“AI 换脸”主题的视频,就需要附上标签。此举的本质目的是防止 AI 生成内容可能导致的虚假信息传播,而非反对创作者通过 AI 制作内容。
而类似于美颜滤镜、背景模糊等传统视觉特效,以及转场特效动画等不属于此次涉及的 AI 制作内容的范畴。
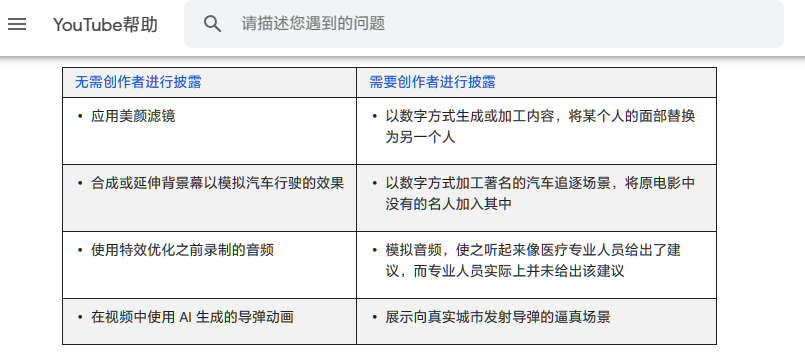
官方表示,创作者必须披露存在以下情况的内容:
- 让现实中存在的人看似说了某些话或做了某些事,但实际上此人并未说过或做过
- 加工有关真实事件或地点的视频片段
- 生成逼真但实际并不存在的场景
这可能包括使用音频、视频或图片制作或编辑工具,完全或部分加工或制作而成的内容。但与此同时,创作者无需对加工或合成的非逼真内容进行披露,也无需对真实内容的轻微修改进行披露。
除了上文提到的美颜或特效外,YouTube 还举例称,类似于“某人骑着独角兽穿越奇幻世界”“描绘人在太空中漂浮的绿幕场景”这种公众很明确能知道现实世界不存在的内容,则不需要强制标注。
Canalys:预估2025年AI PC出货量占到40%
市场调查机构 Canalys 近日发布的最新报告指出,2024 年标志着传统 PC 产业链朝着 AI PC 的重大转变,预估今年全球 AI PC 出货量 4800 万台,占到全部 PC 出货总量的 18%。目前狭义上的「AI PC」特指的是搭载了英特尔最新酷睿处理器的 PC 设备。
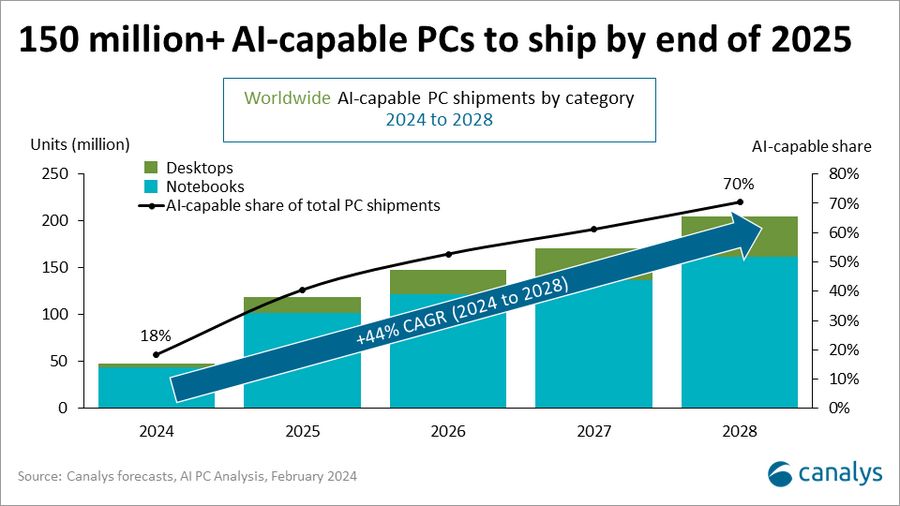
该机构预估 2025 年全球 AI PC 出货量超过 1 亿台,占 PC 出货总量的 40%;到 2028 年,全球 AI PC 出货量 2.05 亿台,2024 年至 2028 年期间的复合年增长率将达到 44%。




