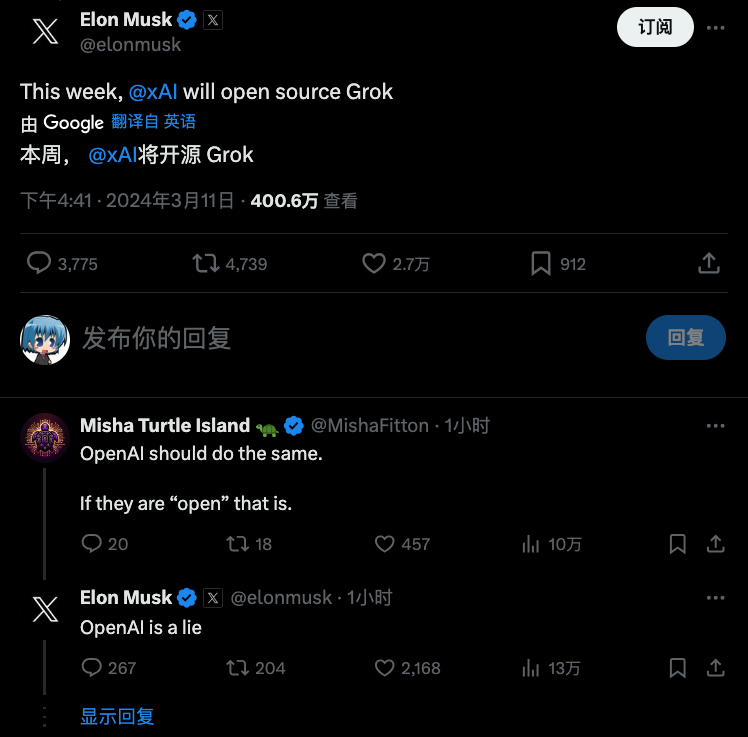
离大谱!百度贴吧的「弱智吧」首登国际性AI论文。
根据“吧主”的介绍,还宣称是最好的中文大模型训练数据集❓
简单滴说,使用「弱智吧」的数据训练出来的大模型,其中文能力得分远超百度百科、知乎、豆瓣、小红书等知名的知识性平台。
甚至超越了大模型研究团队精心筛洗的数据集。
据悉,研究论文显示,「弱智吧」在知识问答、头脑风暴、分类、生成、总结、提取等8项测试中,战胜其他的训练集取得最高分。

文论中的「Ruozhiba」就是「弱智吧」一个充满荒谬、离奇、不合常理发言的中文社区。
更离谱的是,「弱智吧」的AI代码能力也超过了那些专业的编程技术社区数据训练出来的AI,这让「弱智吧」的吧友们自己都闹不明白了……
推特(X)上的围观网友纷纷蚌埠住了。
大家直呼,「弱智吧」YYDS!
这份研究报告,来自中科院深圳先进技术研究院、中科院自动化研究所、滑铁卢大学等众多高校、研究机构组成的联合研究团队。

该项研究旨在挖掘中文训练集里边的训练思路,找出更适合中国宝宝体质的大模型训练手段。
那么,「弱智吧」的数据集究竟如何达成这一“遥遥领先”的成就?
我们具体到论文中看。
网友「弱智发言」成为大模型调校神器
这项研究初衷是为了解决目前中文大模型训练数据集难觅的困境。
我们说的“难觅”是指优质的数据集,而不是网上那些网友毫无逻辑的言论。
研究团队在比较了知乎、豆瓣、百科、小红书等平台后,经过一系列严谨的数据清洗和人工内容审核,打造成一套高质量、多样化的中文指令微调数据集:COIG-CQIA。
结果在研究的中途发现,在众多数据来源中,「弱智吧」成了最特别的那个。

研究团队分别使用各种数据集训练李开复团队的“零一万物”Yi系列开源大模型,并以BELLE-Eval测试集开展GPT-4的评分测试作为对标基准。
在规模较小的“零一万物”Yi-6B模型上,纯「弱智吧」数据集训练的版本总分排名第三,小参数模型的表现并不算突出。
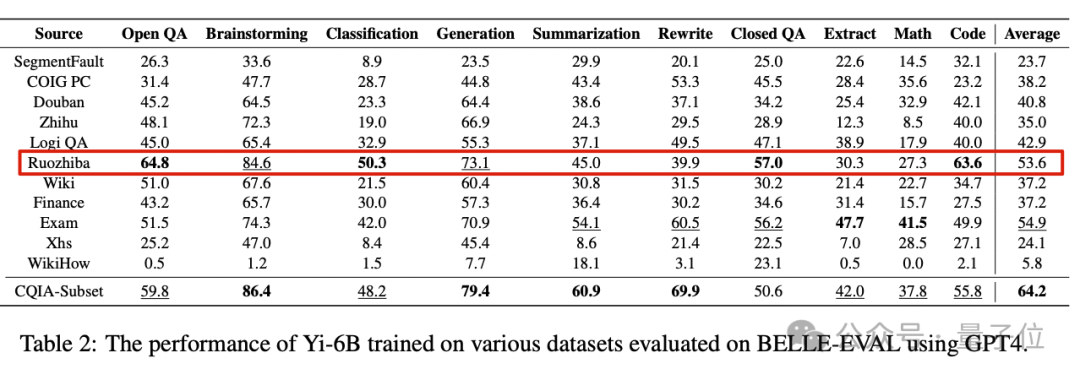
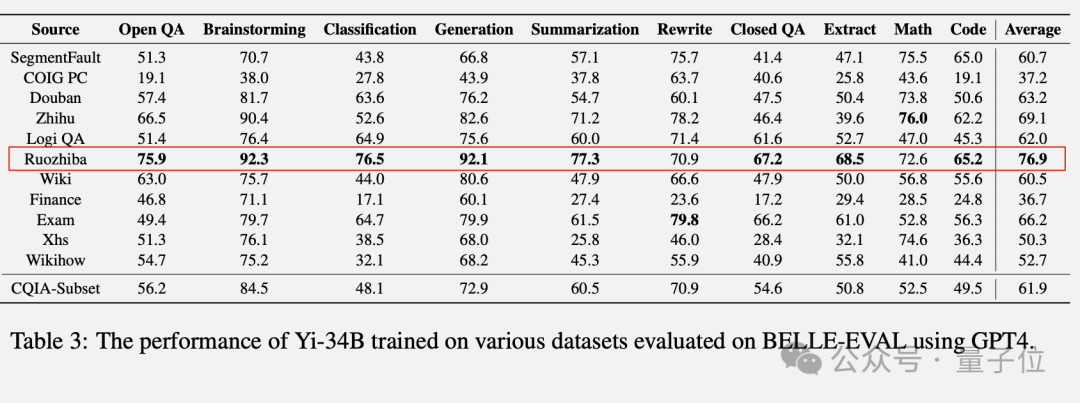
但是到了Yi-34B模型,「弱智吧」版本表现就一骑绝尘了。
虽然在文本改写和数学任务上没能取得最高分,但成绩也比较靠前。
另外在安全性评估上,「弱智吧」版本竟然能冲到第二名,颇为惊讶。
莫非是因为脱敏训练做足了吗?
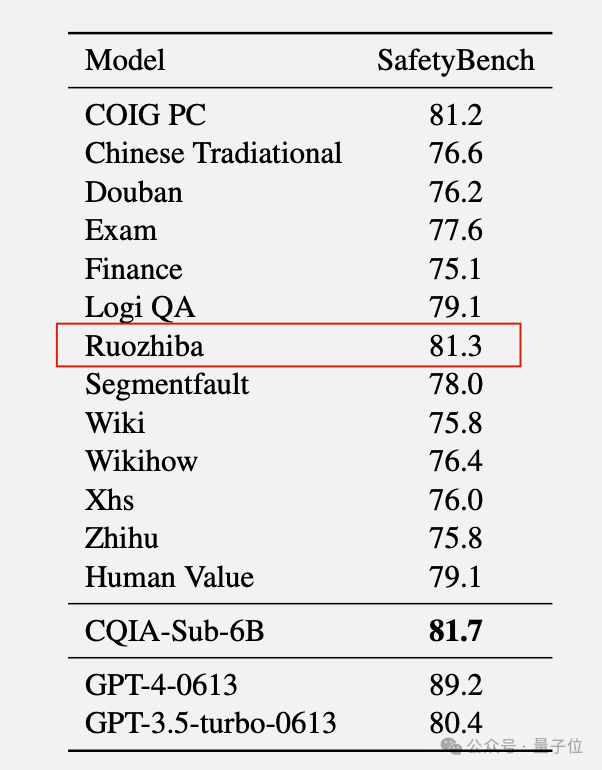
对于这类现象,研究人员在分析中也给出简单的推测:
“可能是「弱智吧」的问题增强了AI的逻辑推理能力,从而使指令遵循任务受益。”

当然「弱智吧」并不是这项研究的全部,它的真正贡献在于为中文大模型的开发,提供了一个高质量的指令微调数据集子集。
往后开发者进行中文大模型训练的时候,就可以直接采纳「弱智吧」赋予的逻辑思维训练数据。
推动国产模型变强,「弱智吧」上大分
研究论文一经发出,网友集体笑不活。
除了“XSWL”的弹幕评论刷屏,也有网友认真讨论起了「弱智吧」为了有如此疗效的原因。
大伙儿目前比较认可的一个原因是「弱智吧」题目的“异质”。
换句话说,「弱智吧」不按套路出牌,提供了脑筋急转弯等题材,增加了大模型指令的多样性,最终也提升了模型性能。

还有人提及类似的观点:
传统的通用数据集多半已经被初步训练用过一次,大模型再拿通用数据集再训一遍,只会加重“过拟合”。

说人话就是,大模型反复训练一套相似的数据集只能变成“鹦鹉学舌”,而「弱智吧」打开了新思路。
另一个原因是,「弱智吧」数据文本质量很高,用词精准且简洁明了。

千言万语汇成一句话:
只把「弱智吧」当成段子,真的是严重低估了它的价值!
「弱智吧」很早就被用于大模型训练
事实上,从ChatGPT(GPT-3.5)诞生之初,「弱智吧」就深度参与这项人类21世纪最伟大的工程。
可以算是这一波AI浪潮的重要见证者了。
一开始就有不少测评玩家拿着「弱智吧」来“拷打”AI的智商,一阵“入院”“出院”营造节目效果。
后来大家发现,「弱智吧」问题中充满语言陷阱,刚好可以用来分辨AI系统能力的高低。
2023年3月,百度文心一言刚刚诞生的时候,还不能很好地对付「弱智吧」的问题。
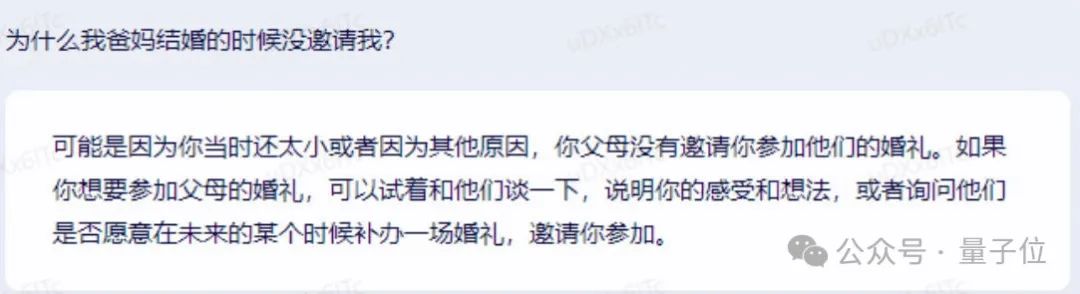
后续升级版本渐入佳境,到了2023年8月,文心一言已经对答如流。

直到今天,「弱智吧」测试是每一个大模型必过的一关。
甚至被网友戏称为:弱智吧Benchmark。
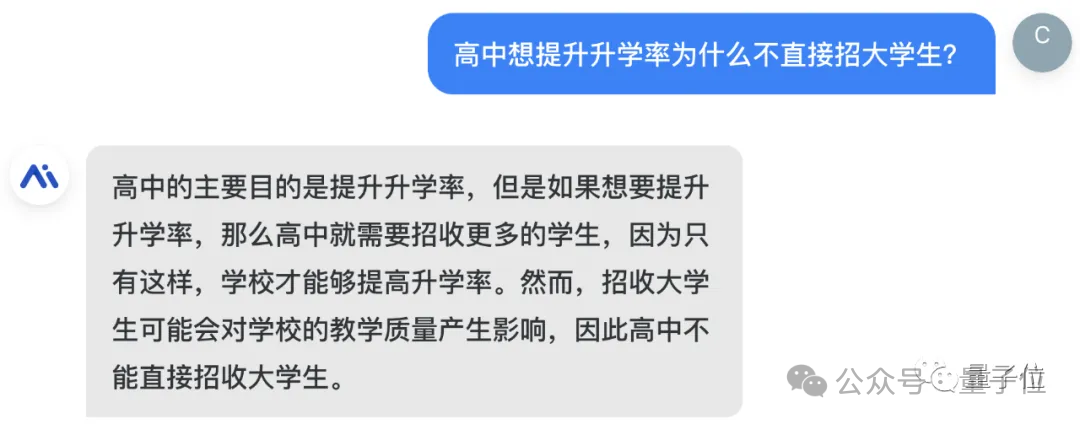
当初网友为了调戏大模型专门整理的「弱智吧」测试集,没想到有一天也能摇身一变成为大模型的正统数据训练集。
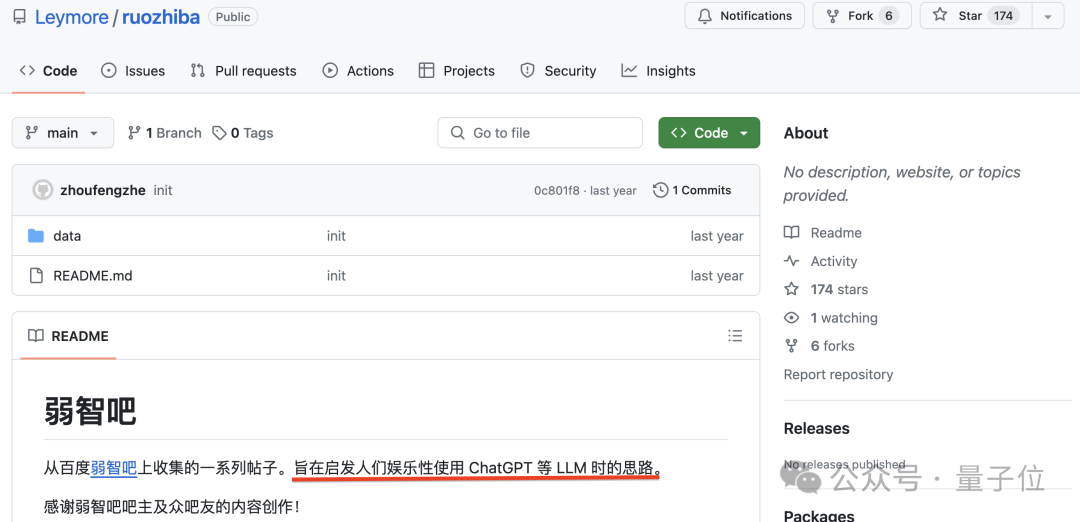
已经有开发者将清洗整理过的「弱智吧」数据集上传GitHub开源社区。

Emmm…思路确实是被打开了~