数据库架构设计
一、数据库之互联网常用架构方案
1.1 目录
一、数据库架构原则
- 高可用
- 高性能
- 一致性
- 扩展性
二、常见的架构方案
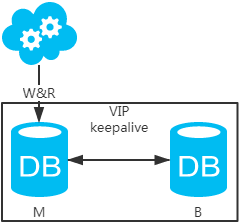
方案一:主备架构,只有主库提供读写服务,备库冗余作故障转移用
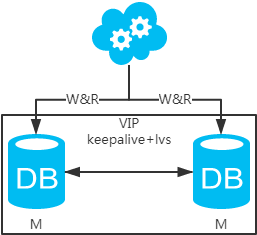
方案二:双主架构,两个主库同时提供服务,负载均衡
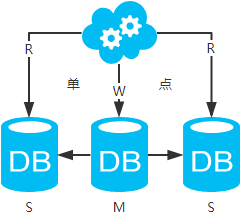
方案三:主从架构,一主多从,读写分离
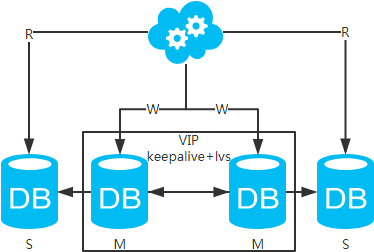
方案四:双主+主从架构,看似完美的方案
三、一致性解决方案
第一类:主库和从库一致性解决方案
第二类:DB和缓存一致性解决方案
四、个人的一些见解
1、架构演变
2、个人见解
第一,性能一般,这点可以通过建立高效的索引和引入缓存来增加读性能,进而提高性能。这也是通用的方案。第二,扩展性差,这点可以通过分库分表来扩展。
1.2 常见的架构方案
我们采用双主+主从架构
方案一:主备架构,只有主库提供读写服务,备库冗余作故障转移用
jdbc:mysql://vip:3306/xxdb
- 高可用分析:高可用,主库挂了,keepalive(只是一种工具)会自动切换到备库。这个过程对业务层是透明的,无需修改代码或配置。
- 高性能分析:读写都操作主库,很容易产生瓶颈。大部分互联网应用读多写少,读会先成为瓶颈,进而影响写性能。另外,备库只是单纯的备份,资源利用率50%,这点方案二可解决。
- 一致性分析:读写都操作主库,不存在数据一致性问题。
- 扩展性分析:无法通过加从库来扩展读性能,进而提高整体性能。
- 可落地分析:两点影响落地使用。第一,性能一般,这点可以通过建立高效的索引和引入缓存来增加读性能,进而提高性能。这也是通用的方案。第二,扩展性差,这点可以通过分库分表来扩展。
方案二:双主架构,两个主库同时提供服务,负载均衡
jdbc:mysql://vip:3306/xxdb
- 高可用分析:高可用,一个主库挂了,不影响另一台主库提供服务。这个过程对业务层是透明的,无需修改代码或配置。
- 高性能分析:读写性能相比于方案一都得到提升,提升一倍。
- 一致性分析:存在数据一致性问题。请看,一致性解决方案。
- 扩展性分析:当然可以扩展成三主循环,但笔者不建议(会多一层数据同步,这样同步的时间会更长)。如果非得在数据库架构层面扩展的话,扩展为方案四。
- 可落地分析:两点影响落地使用。第一,数据一致性问题,一致性解决方案可解决问题。第二,主键冲突问题,ID统一地由分布式ID生成服务来生成可解决问题。
方案三:主从架构,一主多从,读写分离
jdbc:mysql://master-ip:3306/xxdb
jdbc:mysql://slave1-ip:3306/xxdb
jdbc:mysql://slave2-ip:3306/xxdb
- 高可用分析:主库单点,从库高可用。一旦主库挂了,写服务也就无法提供。
- 高性能分析:大部分互联网应用读多写少,读会先成为瓶颈,进而影响整体性能。读的性能提高了,整体性能也提高了。另外,主库可以不用索引,线上从库和线下从库也可以建立不同的索引(线上从库如果有多个还是要建立相同的索引,不然得不偿失;线下从库是平时开发人员排查线上问题时查的库,可以建更多的索引)。
- 一致性分析:存在数据一致性问题。请看,一致性解决方案。
- 扩展性分析:可以通过加从库来扩展读性能,进而提高整体性能。(带来的问题是,从库越多需要从主库拉取binlog日志的端就越多,进而影响主库的性能,并且数据同步完成的时间也会更长)
- 可落地分析:两点影响落地使用。第一,数据一致性问题,一致性解决方案可解决问题。第二,主库单点问题,笔者暂时没想到很好的解决方案。
注:思考一个问题,一台从库挂了会怎样?读写分离之读的负载均衡策略怎么容错?
方案四:双主+主从架构,看似完美的方案
jdbc:mysql://vip:3306/xxdb
jdbc:mysql://slave1-ip:3306/xxdb
jdbc:mysql://slave2-ip:3306/xxdb
高可用分析:高可用。
高性能分析:高性能。
一致性分析:存在数据一致性问题。请看,一致性解决方案。
扩展性分析:当然可以扩展成三主循环,但笔者不建议(会多一层数据同步,这样同步的时间会更长)。可以通过加从库来扩展读性能,进而提高整体性能。(带来的问题是,从库越多需要从主库拉取binlog日志的端就越多,进而影响主库的性能,并且数据同步完成的时间也会更长)
可落地分析:两点影响落地使用。第一,数据一致性问题,一致性解决方案可解决问题。第二,主键冲突问题,ID统一地由分布式ID生成服务来生成可解决问题。但数据同步又多了一层,数据延迟更严重。
1.3 一致性解决方案
第一类:主库和从库一致性解决方案

注:图中圈出的是数据同步的地方,数据同步(从库从主库拉取binlog日志,再执行一遍)是需要时间的,这个同步时间内主库和从库的数据会存在不一致的情况。如果同步过程中有读请求,那么读到的就是从库中的老数据。如下图。
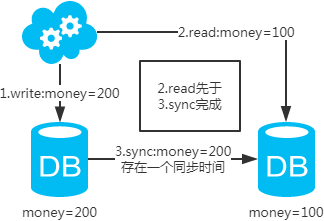
既然知道了数据不一致性产生的原因,有下面几个解决方案供参考:
- 直接忽略,如果业务允许延时存在,那么就不去管它。
- 强制读主,采用主备架构方案,读写都走主库。用缓存来扩展数据库读性能 。有一点需要知道:如果缓存挂了,可能会产生雪崩现象,不过一般分布式缓存都是高可用的。

- 选择读主,写操作时根据库+表+业务特征生成一个key放到Cache里并设置超时时间(大于等于主从数据同步时间)。读请求时,同样的方式生成key先去查Cache,再判断是否命中。若命中,则读主库,否则读从库。代价是多了一次缓存读写,基本可以忽略。

- 半同步复制,等主从同步完成,写请求才返回。就是大家常说的“半同步复制”semi-sync。这可以利用数据库原生功能,实现比较简单。代价是写请求时延增长,吞吐量降低。
- 数据库中间件,引入开源(mycat等)或自研的数据库中间层。个人理解,思路同选择读主。数据库中间件的成本比较高,并且还多引入了一层。
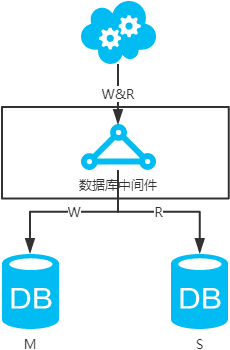
第二类:DB和缓存一致性解决方案
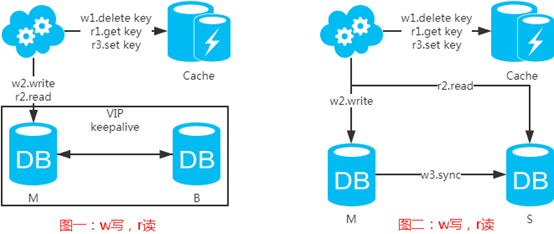
先来看一下常用的缓存使用方式:
第一步:淘汰缓存;
第二步:写入数据库;
第三步:读取缓存?返回:读取数据库;
第四步:读取数据库后写入缓存。
注:如果按照这种方式,图一,不会产生DB和缓存不一致问题;图二,会产生DB和缓存不一致问题,即4.read先于3.sync执行。如果不做处理,缓存里的数据可能一直是脏数据。解决方式如下:
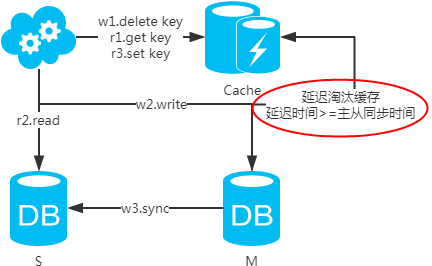
注:设置缓存时,一定要加上失效时间,以防延时淘汰缓存失败的情况!
1.4 VIP(虚拟IP)
数据库高可用场景下,VIP(虚拟IP)的作用
高可用性HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性。HA系统是目前企业防止核心计算机系统因故障停机的最有效手段。
实现HA的方式,一般采用两台机器同时完成一项功能,比如数据库服务器,平常只有一台机器对外提供服务,另一台机器作为热备,当这台机器出现故障时,自动动态切换到另一台热备的机器。
怎么实现故障检测的那?
心跳,采用定时发送一个数据包,如果机器多长时间没响应,就认为是发生故障,自动切换到热备的机器上去。
怎么实现自动切换那?
虚IP。何为虚IP那,就是一个未分配给真实主机的IP,也就是说对外提供数据库服务器的主机除了有一个真实IP外还有一个虚IP,使用这两个IP中的 任意一个都可以连接到这台主机,所有项目中数据库链接一项配置的都是这个虚IP,当服务器发生故障无法对外提供服务时,动态将这个虚IP切换到备用主机。
开始我也不明白这是怎么实现的,以为是软件动态改IP地址,其实不是这样,其实现原理主要是靠TCP/IP的ARP协议。因为ip地址只是一个逻辑 地址,在以太网中MAC地址才是真正用来进行数据传输的物理地址,每台主机中都有一个ARP高速缓存,存储同一个网络内的IP地址与MAC地址的对应关 系,以太网中的主机发送数据时会先从这个缓存中查询目标IP对应的MAC地址,会向这个MAC地址发送数据。操作系统会自动维护这个缓存。这就是整个实现 的关键。
下边就是我电脑上的arp缓存的内容。
(192.168.1.219) at 00:21:5A:DB:68:E8 [ether] on bond0
(192.168.1.217) at 00:21:5A:DB:68:E8 [ether] on bond0
(192.168.1.218) at 00:21:5A:DB:7F:C2 [ether] on bond0
192.168.1.217、192.168.1.218是两台真实的电脑,
192.168.1.217为对外提供数据库服务的主机。
192.168.1.218为热备的机器。
192.168.1.217为虚IP。
大家注意红字部分,219、217的MAC地址是相同的。
再看看那217宕机后的arp缓存
(192.168.1.219) at 00:21:5A:DB:7F:C2 [ether] on bond0
(192.168.1.217) at 00:21:5A:DB:68:E8 [ether] on bond0
(192.168.1.218) at 00:21:5A:DB:7F:C2 [ether] on bond0
这就是奥妙所在。
当218 发现217宕机后会向网络发送一个ARP数据包,告诉所有主机192.168.1.219这个IP对应的MAC地址是00:21:5A:DB:7F:C2 ,这样所有发送到219的数据包都会发送到mac地址为00:21:5A:DB:7F:C2的机器
实现:
参考:
https://blog.csdn.net/kongxx/article/details/73173762
https://blog.csdn.net/weixin_40006394/article/details/80451269
https://blog.csdn.net/wenxindiaolong061/article/details/80320531
1.5 Keepalive
或者用HeartBeat
参考:
https://blog.csdn.net/qq_24336773/article/details/82143367
https://www.jianshu.com/p/3e5e6a433224
https://blog.51cto.com/superpcm/2095395
1.6 lvs
二、数据库之互联网常用分库分表方案
2.1 目录
一、数据库瓶颈
1、IO瓶颈
2、CPU瓶颈
二、分库分表
1、水平分库
2、水平分表
3、垂直分库
4、垂直分表
三、分库分表工具
四、分库分表步骤
五、分库分表问题
1、非partition key的查询问题(水平分库分表,拆分策略为常用的hash法)
2、非partition key跨库跨表分页查询问题(水平分库分表,拆分策略为常用的hash法)
3、扩容问题(水平分库分表,拆分策略为常用的hash法)
六、分库分表总结
七、 分库分表示例
2.2 数据库瓶颈
不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。在业务Service来看就是,可用数据库连接少甚至无连接可用。接下来就可以想象了吧(并发量、吞吐量、崩溃)。
1、IO瓶颈
第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度 -> 分库和垂直分表。
第二种:网络IO瓶颈,请求的数据太多,网络带宽不够 -> 分库。
2、CPU瓶颈
第一种:SQL问题,如SQL中包含join,group by,order by,非索引字段条件查询等,增加CPU运算的操作 -> SQL优化,建立合适的索引,在业务Service层进行业务计算。
第二种:单表数据量太大,查询时扫描的行太多,SQL效率低,CPU率先出现瓶颈 -> 水平分表。
2.3 分库分表
1、水平分库

1)概念:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
2)结果:
每个库的结构都一样;
每个库的数据都不一样,没有交集;
所有库的并集是全量数据;
3)场景:系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属来垂直分库。
4)分析:库多了,io和cpu的压力自然可以成倍缓解。
2、水平分表
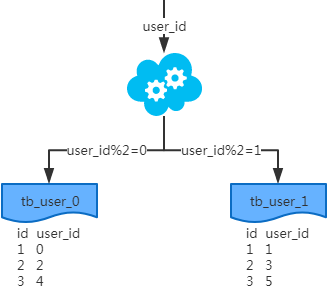
1)概念:以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。
2)结果:
每个表的结构都一样;
每个表的数据都不一样,没有交集;
所有表的并集是全量数据;
3)场景:系统绝对并发量并没有上来,只是单表的数据量太多,影响了SQL效率,加重了CPU负担,以至于成为瓶颈。
4)分析:表的数据量少了,单次SQL执行效率高,自然减轻了CPU的负担。
3、垂直分库
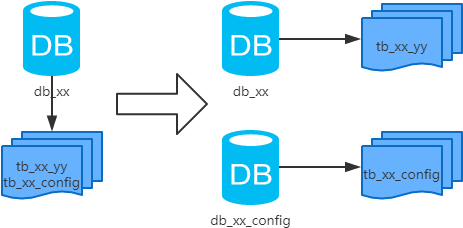
1)概念:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
2)结果:
每个库的结构都不一样;
每个库的数据也不一样,没有交集;
所有库的并集是全量数据;
3)场景:系统绝对并发量上来了,并且可以抽象出单独的业务模块。
4)分析:到这一步,基本上就可以服务化了。例如,随着业务的发展一些公用的配置表、字典表等越来越多,这时可以将这些表拆到单独的库中,甚至可以服务化。再有,随着业务的发展孵化出了一套业务模式,这时可以将相关的表拆到单独的库中,甚至可以服务化。
4、垂直分表

1)概念:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
2)结果:
每个表的结构都不一样;
每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据;
所有表的并集是全量数据;
3)场景:系统绝对并发量并没有上来,表的记录并不多,但是字段多,并且热点数据和非热点数据在一起,单行数据所需的存储空间较大。以至于数据库缓存的数据行减少,查询时会去读磁盘数据产生大量的随机读IO,产生IO瓶颈。
4)分析:可以用列表页和详情页来帮助理解。垂直分表的拆分原则是将热点数据(可能会冗余经常一起查询的数据)放在一起作为主表,非热点数据放在一起作为扩展表。这样更多的热点数据就能被缓存下来,进而减少了随机读IO。拆了之后,要想获得全部数据就需要关联两个表来取数据。但记住,千万别用join,因为join不仅会增加CPU负担并且会讲两个表耦合在一起(必须在一个数据库实例上)。关联数据,应该在业务Service层做文章,分别获取主表和扩展表数据然后用关联字段关联得到全部数据。
2.4 分库分表工具
1. sharding-sphere:jar,前身是sharding-jdbc;
2. TDDL:jar,Taobao Distribute Data Layer;
3. Mycat:中间件。
注:工具的利弊,请自行调研,官网和社区优先。
2.5 分库分表步骤
根据容量(当前容量和增长量)评估分库或分表个数 -> 选key(均匀)-> 分表规则(hash或range等)-> 执行(一般双写)-> 扩容问题(尽量减少数据的移动)。
2.6 分库分表问题
1.非partition key的查询问题(水平分库分表,拆分策略为常用的hash法)
1)端上除了partition key只有一个非partition key作为条件查询
映射法:
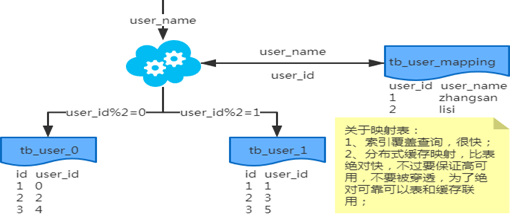
基因法:

注:写入时,基因法生成user_id,如图。关于xbit基因,例如要分8张表,23=8,故x取3,即3bit基因。根据user_id查询时可直接取模路由到对应的分库或分表。根据user_name查询时,先通过user_name_code生成函数生成user_name_code再对其取模路由到对应的分库或分表。id生成常用snowflake算法。
2) 端上除了partition key不止一个非partition key作为条件查询
映射法:

冗余法:
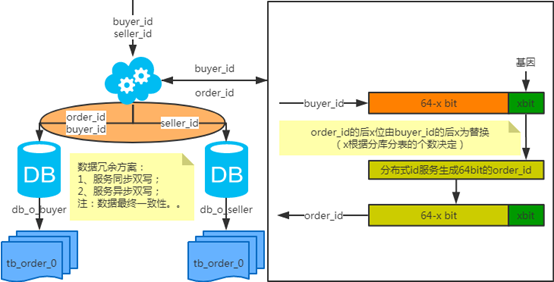
注:按照order_id或buyer_id查询时路由到db_o_buyer库中,按照seller_id查询时路由到db_o_seller库中。感觉有点本末倒置!有其他好的办法吗?改变技术栈呢?
3)后台除了partition key还有各种非partition key组合条件查询
NoSQL法:

冗余法:
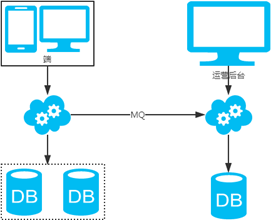
2、非partition key跨库跨表分页查询问题(水平分库分表,拆分策略为常用的hash法)
注:用NoSQL法解决(ES等)。
3、扩容问题(水平分库分表,拆分策略为常用的hash法)
1) 水平扩容库(升级从库法)

注:扩容是成倍的。
2) 水平扩容表(双写迁移法)
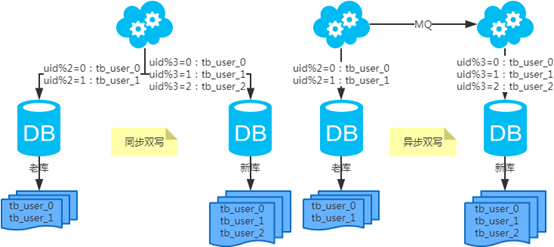
第一步:(同步双写)应用配置双写,部署;
第二步:(同步双写)将老库中的老数据复制到新库中;
第三步:(同步双写)以老库为准校对新库中的老数据;
第四步:(同步双写)应用去掉双写,部署;
注:双写是通用方案。
2.7 分库分表总结
1. 分库分表,首先得知道瓶颈在哪里,然后才能合理地拆分(分库还是分表?水平还是垂直?分几个?)。且不可为了分库分表而拆分。
2.选key很重要,既要考虑到拆分均匀,也要考虑到非partition key的查询。
3. 只要能满足需求,拆分规则越简单越好。
三、 数据库规范
适用场景:互联网高并发、高吞吐、海量数据、强一致性要求高、mysql数据库、互联网金融业务。
3.1 数据库设计框架思维
1. 数据库设计第一原则,领域设计 + 恒等式设计 + 数据流转设计
注:这三个思想后面会单独写篇文章来讲,非常非常重要的指导思想
2. 领域驱动表设计,一个领域的属性放在一个表内
注:自行车的归自行车,汽车的归汽车,一个表内不应有不在一个频道的字段
3. 一套表的设计,最基本要满足第三范式
注:第三范式(Third Normal Form,3rd NF)就是指表中的所有数据元素不但要能惟一地被主关键字所标识,而且它们之间还必须相互独立,不存在其他的函数关系。
4. 对于基础服务的表,要满足BC范式的要求
注:基础服务表要求更高,在第三范式基础上,升级为BC范式
5. 对互联网数据库设计,可以增加静态数据冗余
注:互联网都是单表查询,静态数据冗余可以有效防止N+1操作,大大提高性能
6. 数据库引擎必须选择Innodb
注:(1)没的商量,就是这个,如果只给一个原因,就一条,我们是做金融行业,安全、安全、安全
(2) Innodb支持事务,行级锁,并发性能更好,资源利用率更高,数据库崩溃恢复稳定
(3) 支持在线备份,方便运维工作
(4)官方版本致力于优化innodb,后期功能和稳定性会越来越好
(5) 支持行锁,支持mvcc
7. 字符集必须是UTF-8字符集
注:什么国家字符都支持,不乱码,这就够了
8. 严格禁止使用触发器、视图、存储过程
注:(1) 互联网业务瞬息万变,数据库表结构变化频繁,用触发器,存储过程,视图作业做业务,后期的维护成本会高昂的吓死人,如果一个开发走了,都不知道影响到哪些业务,你说吓不吓人
(2) 计算尽量移到应用层来计算,互联网DB是用来存储海量数据的,不是用来做数据计算的,分工明确,而且业务计算逻辑放到业务层,方便业务快速迭代,也可以通过加机器实现计算能力快速提升
9. 每个字段要有注释,每个表名要有注释,字段的取值含义或者范围,枚举值要有注释,这些都要有中文注释
注:有注释后来人才好维护,才好学习,不然都是坑,好的注释看着也舒坦啊
3.2 命名规范
1. 表名:同一个应用(或领域)下的,要有相同的前缀,如:tb_share, tb_posi,tb_valu,风格 t_xxx。
注:这样管理维护成本才低,认知理解成本也低,简单的例子就是统一制服,医生,护士,警察,卖保险等等,是不是听着还有点小兴奋
2. 库名、表名、字段名:要字母小写加下划线风格,长度不能超过32个字符,禁止拼音加英文混合命名
注:超过32个字符看起来太不舒服了,风格统一,不要另类
3. 简洁、见名知意,
注:csm代表渠道结算,全名channel settlement, 用全名会很长,csm简写会方便很多
4. 专业,体现行业标准
注:比如取现用withdraw;持仓用position;份额用share。因为我是做金融行业的,很多词汇都可以对应专业英文词汇,所以我们就不用自己造了。那当没有专业英语词汇时,我们也要尽量专业的去命名。这里,金融专业词汇推荐网站:MBA智库百科
6. 索引命名规范:普通索引 idx_+字段名,主键索引 pk_+字段名,唯一索引 uk_+字段名
注:这个就不用注了,一看就懂
7. 连接数据库统一域名规范,不允许使用IP直连
注: 开发环境:app.xxx.devdb
测试环境:app.xxx.testdb
线上环境:app.xxx.db
一级从库加-s标志, 二级从库加-ss标志,依次递增
一级从库:app.xxx-s.db
二级从库:app.xxx-ss.db
3.3 字段数据类型设计规范
1. 如果需要时分秒时间记录,建议用datetime类型
2. 如果需要的更多是日期的查询,建议用int型,不用DATE, 如20160909等,性能更高,空间更小
3. 如果需要比时分秒更精确的时间记录,建议用long型,用应用生成时间戳,System.currentTimeMillis()进行存储
4. 字符串存储能用varchar不要用text,varchar存储,搜索性能都高于text,text查询是会产生临时磁盘文件,性能差,如果长度超出了varchar长度,进行截取存储
5. 数字类型选择,放弃float和double,全用decimal
6. 放弃用BLOB二进制数据类型,如果涉及大数据存储,进行DB-索引-文件存储系统模式来处理
7. 整数类型的具体选择,下面单独讲解
3.4 整数型字段选择规范
|
类型 |
占用字节 |
范围 |
|
tinyint |
1 |
-128~127 |
|
smallint |
2 |
-32768~32767 |
|
mediumint |
3 |
-8388608~8388607) |
|
int |
4 |
-2147483648~2147483647 |
|
bigint |
8 |
+-9.22*10的18次方 |
1. 不浪费空间, 能用小的数据类型干嘛占用那么多空间
2. 能用int,不影响业务理解,不用char
3. 方便以后扩容,支持以后扩容需求
4. 注意int(1), int(10),没有存储空间上的差别,只是在补0查询是,占位达到的位数,所以空间还是类型的选择
注:direction表示收支方向, 就收,支,平,三个值,直到沧海桑田,海枯石烂也是三个值,所以一定用tinyint(1),省空间,效率高
3.5 根据业务选择字段类型规范、默认值规范
1、一般扩展性有限的常量类型,建议用整形,性能高,占空间少,比如状态字段,初始设置值的时候,建议1,3,5,7这样,方便扩展
2、一般不确定扩展性的类型,建议用字符型,若订单子类型,字符型的好处,可以添加业务规则,一个字段可以同时表示出爷爷,儿子孙子的含义,比如subType=0000 0000 0000 前四个字段代表大类购买类型,中间代表子类购买,最后代表三级购买类型,这样通过一个字段可以做很多事情
3、序列号,id等字段,建议varchar(32)或者bigint
4、如果为了方便查问题,且表的数据量不大,可以用有含义的英文单词表示常量,比如收入IN, 支出OUT, 数据库查下排查问题很方便
5、不要有null值,不要有null值,不要有null值,建表是要default 一个默认值,尽量建表是not null语句,
除了modify_time必须default null以外,其他都是not null
6、varchar长度超过255的时候用text,用varchar就没有意义了,建议varchar不要超过255
3.6 默认建表存在的字段规范
1、一个表必须要有的默认字段,这些字段可以排查问题,做变更记录,方便BI数据统计等
2、注意create_time一定要加索引,真的要加,必须加
`create_time` datetime NOT NULL COMMENT '表创建时间',
`modify_time` datetime DEFAULT NULL COMMENT '表修改时间',
`remark` varchar(64) DEFAULT NULL COMMENT '备注',
3、create_time和modify_time建议在daoimpl层做时间处理,或者在sql层面做默认时间处理,可以完全保证准确没有脏数据,防止被误用
4、对于后台操作的系统,还需要有的字段
operator 操作人 operate_time 操作时间 等
5、对于事务要求强的业务表和一些变更记录表,需要有的字段
version 版本号 seq序列号
3.7 数据加密规范
1、哪些字段需要加密?
注:敏感字段,如姓名,身份证号,银行卡号,邮箱等
2、加密算法选择?对称还是非对称?
注:根据实际业务进行选择,可以MD5,可以RSA,可以AES,具体选择后续,老夫出个介绍算法的
3、字段长度选择?
注:字段长度要根据业务长度加密后长度进行设定,如果过长要选择换加密算法等
3.8 表字段顺序规范
你没有看错,是这个,表的字段顺序很重要
1. 从前到后,按照字段的重要性和使用频率排列。
2. 按字段的分类归集排列:如 金额相关的在一块,文案相关的在一块,时间相关的在一块等
3. create_time,modify_time,remark三个字段在最后
3.9 主键ID规范
1. 每个表都应该设置一个ID主键,最好的是一个INT型,并且设置上自动增加的AUTO_INCREMENT标志,这点其实应该作为设计表结构的第一件必然要做的事!!
2. 个人强烈建议:自增id主键+全局唯一序列号, 全局唯一序列号(必须加唯一索引)
注:100xxxxxx-广东省, 200xxxxxx-黑龙江
同时自增主键ID,对于遍历需求来说很容易实现不重复不漏掉遍历
3. 唯一键设计推荐规范:
(1)全局自增id,通过db步长来做
(2)15位时间戳+业务标志+ip+分库+分表,生成业务含义全局唯一键
(3)分布式全局唯一, UUID或额外系统主键生成系统支持
3.10 索引设计规范
1. 单表索引数目不能超过5个
注:聚簇索引造成的存储和查询成本当索引过多时,性能降低很快
2. 根据业务需求设计索引,如果没有查询需求,干嘛要去建索引呢
3. 一个字段的值范围很小,不要设置索引,索引不生效同事浪费插入性能
注:当索引的值就三五个,范围很小时,数据库进行的基本是全表扫描,没必要建索引
4. 如果有幂等性需求,对需要幂等字段或字段组合,设置数据库唯一索引
5. null值对索引是一大伤害,所以不要让索引的列有null值存在
6. 尽量加索引的字段的数据类型小,也就是能用整数不用varchar能用短的varchar不用长的varchar,不要在text上设置索引
7. 一个索引包含的字段数不能超过3个
8. 尽量在静态数据上建立索引,频繁变动数据建索引,每次db都要考虑是否重建B+树
注:
(1)如账户,userId设置为唯一索引,一个人只能有一个铜板账户,静态数据
(2)收支流水表的userID设置普通索,查询效率高,查询需求
(3)create_time 默认加索引
(4)a,b,c 组合索引,索引构建是用a+b+c进行构建的索引,如果是btree索引,查询的时候 abc|ab|a三种查询条件都会走索引,不需要对a和ab重复创建索引 ,但是 like '%b'|'%bc'|'%c'不会走索引,所以,组合索引,一定使用频率高的放在最左边
3.11 数据库容量设计规范
1. 根据业务发展预估,数据库容量设计要满足支撑未来3--5年数据增加需求,同时设计之初要考虑后续扩容很方便
注:不给后人挖坑,做一个栽树的前人
2. 深入理解业务,根据业务特性来分表扩容,同时根据查询需求来分表
案例:
(1)代金券分表 (季度分)
(2)每日收益分表 (userId取余)
(3)对账分表 (按月分)
(4)微信红包分表 (年度+用户分)
3. 具体分表策略,见前面一篇文章:海量数据存储--分库分表策略详解
3.12 防止全表扫描规范做法
1. 原则:
(1)全表扫描会造成数据库挂掉,OOM,慢查询等可怕事情
(2)索引的值范围很少,索引即使设计了也不会生效,也会全表扫描
(3)删数据时,where后必须有条件,条件走索引,同时加limit限制,防止sql错误,多删数据
2. 会出现全表扫描的情况,如下
(1)未创建索引 例如: select * from tbname where name='?' 如果name字段未创建索引,那么就是全表扫描
(2)隐式转换 例如:select * from tbname where id=1234; 如果id字段是varchar类型,那么就算id字段上建立有索引,也还是会走全表扫描。
(3)索引区分度问题:select * from tbname where status=1 and name=? ,status,sex这类字段的重复值过低,索引区分度超过30以上,
优化器会认为status索引效率低,如果name字段没有索引的话,就会全表扫描
(4)索引字段上使用函数 select * from tbname where date(create_time)=? create_time字段上使用了函数,将不会走索引,可以改成 create_time=date_format(?)这种形式
(5)联合索引字段顺序, a,b字段创建联合索引,select * from tbname where b=? 不符合左前缀原则, 单独使用b字段无法使用索引,可改成 index(b,a);
3. 防止全表扫描的办法
(1)DAOIMPL层面限制不走索引的查询sql
(2) DAOIMPL层面限制索引值少的查询sql
(3) mybatis.xml层面对删除进行限制Delete from tb_position where id=142343 limit 1;
3.13 如何有效遍历
1. 有自增主键的遍历
select * from table_xxx where status = #status and id > #lastQueryId limit 1000;
优点:性能高,不漏数据,遍历数据状态变更不会造成位移,每次取出最后一条ID,进行下一次查询,性能极高
缺点:暂时没发现
2. 带状态更新的遍历
会可能存在位移差,存在漏数据
解决办法:
(1)通过自增ID id>#lastId, limit 100, order没有自增主键
(2)临时表, 存在新增数据的遍历,做临时表,临时表做业务重复判断。
(3)create_time 半开查询 create_time >= egtCreateTime and create_time < ltCreateTime
四、主备架构实现方法
方案一:主备架构,只有主库提供读写服务,备库冗余作故障转移用。主要是用的VIP+Keepalive技术。

jdbc:mysql://vip:3306/xxdb
方案四:双主+主从架构,看似完美的方案
五、双主架构实现方法
方案二:双主架构,两个主库同时提供服务,负载均衡。主要用到VIP+Keepalive+lvs技术。
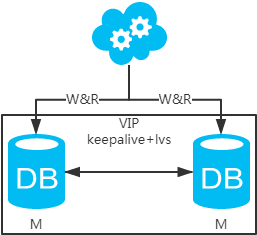
jdbc:mysql://vip:3306/xxdb
六、主从架构实现方法
方案三:主从架构,一主多从,读写分离。数据库读写分离,主从同步。
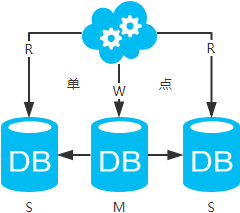
jdbc:mysql://master-ip:3306/xxdb
jdbc:mysql://slave1-ip:3306/xxdb
jdbc:mysql://slave2-ip:3306/xxdb
6.1 MySQL主从架构实现
主从介绍:
Mysql主从又叫Replication、AB复制。简单讲就是A与B两台机器做主从后,在A上写数据,另外一台B也会跟着写数据,实现数据实时同步。mysql主从是基于binlog,主上需开启binlog才能进行主从。
主从过程大概有3个步骤:
1)主将更改操作记录到binlog里
2)从将主的binlog事件(sql语句) 同步本机上并记录在relaylog里
3)从根据relaylog里面的sql语句按顺序执行
主从作用:
1) 实时灾备,用于故障切换
2) 读写分离,提供查询服务
3)备份,避免影响业务
主从形式:

* 一主一从
* 主主复制
* 一主多从---扩展系统读取的性能,因为读是在从库读取的
* 多主一从---5.7版本开始支持
* 联级复制
主从复制原理:
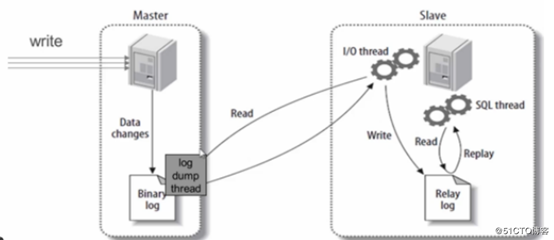
主从复制步骤:
1)主库将所有的写操作记录在binlog日志中,并生成log dump线程,将binlog日志传给从库的I/O线程
3) 从库生成两个线程,一个是I/O线程,另一个是SQL线程
3)I/O线程去请求主库的binlog日志,并将binlog日志中的文件写入relay log(中继日志)中
4) SQL线程会读取relay log中的内容,并解析成具体的操作,来实现主从的操作一致,达到最终数据一致的目的
主从复制配置步骤:
1)确保从数据库与主数据库里的数据一致
2)在主数据库里创建一个同步账户授权给从数据库使用
3)配置主数据库(修改配置文件)
4)配置从数据库(修改配置文件
需求:
搭建两台MYSQL服务器,一台作为主服务器,一台作为从服务器,主服务器进行写操作,从服务器进行读操作
环境说明:
|
数据库角色 |
IP |
应用与系统 |
有无数据 |
|
主数据库 |
192.168.X.X1 |
centos7 mysql-5.7 |
有 |
|
从数据库 |
192.168.X.X2 |
centos7 mysql-5.7 |
无 |
在两台服务器上都安装mysql:
1)mysql主从配置,确保从数据库与主数据库的数据一样先在主数据库创建所需要同步的库和表。
2)备份主库,备份主库时需要另开一个终端,给数据库上读锁,避免在备份期间有其他人在写入导致数据同步的不一致。此锁表的终端必须在备份完成以后才能退出(退出锁表失效)
|
环境准备 关闭防火墙以SELINUX [root@yanyinglai ~]# systemctl stop firewalld [root@yanyinglai ~]# systemctl disable firewalld [root@yanyinglai ~]# sed -ri 's/(SELINUX=).*/\1disabled/g' /etc/selinux/config [root@yanyinglai ~]# setenforce 0
安装mysql 安装依赖包 [root@yanyinglai ~]# yum -y install ncurses-devel openssl-devel openssl cmake mariadb-devel
创建用户和组 [root@yanyinglai ~]# groupadd -r -g 306 mysql [root@yanyinglai ~]# useradd -M -s /sbin/nologin -g 306 -u 306 mysql
下载二进制格式的mysql软件包 [root@yanyinglai ~]# cd /usr/src/ [root@yanyinglai src]#wget https://downloads.mysql.com/archives/get/file/mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz
解压软件至/usr/local/ [root@yanyinglai src]# ls debug kernels mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz [root@yanyinglai src]# tar xf mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz -C /usr/local/ [root@yanyinglai src]# ls /usr/local/ bin etc games include lib lib64 libexec mysql-5.7.22-linux-glibc2.12-x86_64 sbin share src [root@yanyinglai src]# cd /usr/local/ [root@yanyinglai local]# ln -sv mysql-5.7.22-linux-glibc2.12-x86_64/ mysql "mysql" -> "mysql-5.7.22-linux-glibc2.12-x86_64/" [root@yanyinglai local]# ll
总用量 0 drwxr-xr-x. 2 root root 6 11月 5 2016 bin drwxr-xr-x. 2 root root 6 11月 5 2016 etc drwxr-xr-x. 2 root root 6 11月 5 2016 games drwxr-xr-x. 2 root root 6 11月 5 2016 include drwxr-xr-x. 2 root root 6 11月 5 2016 lib drwxr-xr-x. 2 root root 6 11月 5 2016 lib64 drwxr-xr-x. 2 root root 6 11月 5 2016 libexec lrwxrwxrwx. 1 root root 36 9月 7 22:20 mysql -> mysql-5.7.22-linux-glibc2.12-x86_64/ drwxr-xr-x. 9 root root 129 9月 7 22:19 mysql-5.7.22-linux-glibc2.12-x86_64 drwxr-xr-x. 2 root root 6 11月 5 2016 sbin drwxr-xr-x. 5 root root 49 9月 3 23:02 share drwxr-xr-x. 2 root root 6 11月 5 2016 src
修改目录/usr/locaal/mysql的属主属组 [root@yanyinglai local]# chown -R mysql.mysql /usr/local/mysql [root@yanyinglai local]# ll /usr/local/mysql -d lrwxrwxrwx. 1 mysql mysql 36 9月 7 22:20 /usr/local/mysql -> mysql-5.7.22-linux-glibc2.12-x86_64/
添加环境变量 [root@yanyinglai local]# ls /usr/local/mysql bin COPYING docs include lib man README share support-files [root@yanyinglai local]# cd [root@yanyinglai ~]# echo 'export PATH=/usr/local/mysql/bin:$PATH' > /etc/profile.d/mysql.sh [root@yanyinglai ~]# . /etc/profile.d/mysql.sh [root@yanyinglai ~]# echo $PATH /usr/local/mysql/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
建立数据存放目录 [root@yanyinglai ~]# cd /usr/local/mysql [root@yanyinglai mysql]# mkdir /opt/data [root@yanyinglai mysql]# chown -R mysql.mysql /opt/data/ [root@yanyinglai mysql]# ll /opt/ 总用量 0 drwxr-xr-x. 2 mysql mysql 6 9月 7 22:25 data
初始化数据库 [root@yanyinglai mysql]# /usr/local/mysql/bin/mysqld --initialize --user=mysql --datadir=/opt/data/ //这个命令的最后会生成一个临时密码,此处密码是1EbNA-k*BtKo
配置mysql [root@yanyinglai ~]# ln -sv /usr/local/mysql/include/ /usr/local/include/mysql "/usr/local/include/mysql" -> "/usr/local/mysql/include/" [root@yanyinglai ~]# echo '/usr/local/mysql/lib' > /etc/ld.so.conf.d/mysql.conf [root@yanyinglai ~]# ldconfig -v
生成配置文件 [root@yanyinglai ~]# cat > /etc/my.cnf <<EOF > [mysqld] > basedir = /usr/local/mysql > datadir = /opt/data > socket = /tmp/mysql.sock > port = 3306 > pid-file = /opt/data/mysql.pid > user = mysql > skip-name-resolve > EOF
配置服务启动脚本 [root@yanyinglai ~]# cp -a /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld [root@yanyinglai ~]# sed -ri 's#^(basedir=).*#\1/usr/local/mysql#g' /etc/init.d/mysqld [root@yanyinglai ~]# sed -ri 's#^(datadir=).*#\1/opt/data#g' /etc/init.d/mysqld
启动mysql [root@yanyinglai ~]# service mysqld start Starting MySQL.Logging to '/opt/data/yanyinglai.err'. .. SUCCESS! [root@yanyinglai ~]# ps -ef|grep mysql root 4897 1 0 22:38 pts/2 00:00:00 /bin/sh /usr/local/mysql/bin/mysqld_safe --datadir=/opt/data --pid-file=/opt/data/mysql.pid mysql 5075 4897 6 22:38 pts/2 00:00:01 /usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/opt/data --plugin-dir=/usr/local/mysql/lib/plugin --user=mysql --log-error=yanyinglai.err --pid-file=/opt/data/mysql.pid --socket=/tmp/mysql.sock --port=3306 root 5109 4668 0 22:38 pts/2 00:00:00 grep --color=auto mysql [root@yanyinglai ~]# ss -antl State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 *:22 *:* LISTEN 0 100 127.0.0.1:25 *:* LISTEN 0 128 :::22 :::* LISTEN 0 100 ::1:25 :::* LISTEN 0 80 :::3306 :::*
修改密码 使用临时密码修改 [root@yanyinglai ~]# mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.7.22
Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> set password = password('123456'); Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> quit Bye
mysql主从配置 确保从数据库与主数据库的数据一样先在主数据库创建所需要同步的库和表 [root@yanyinglai ~]# mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 4 Server version: 5.7.22 MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle and/or its affiliates. Al
Oracle is a registered trademark of Oracle Corporation and affiliates. Other names may be trademarks of their respect owners.
Type 'help;' or '\h' for help. Type '\c' to clear the curr
mysql> create database yan; Query OK, 1 row affected (0.00 sec)
mysql> create database lisi; Query OK, 1 row affected (0.00 sec)
mysql> create database wangwu; Query OK, 1 row affected (0.00 sec)
mysql> use yan; Database changed mysql> create table tom (id int not null,name varchar(100)not null ,age tinyint); Query OK, 0 rows affected (11.83 sec)
mysql> insert tom (id,name,age) values(1,'zhangshan',20),(2,'wangwu',7),(3,'lisi',23); Query OK, 3 rows affected (0.07 sec) Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from tom; +----+-----------+------+ | id | name | age | +----+-----------+------+ | 1 | zhangshan | 20 | | 2 | wangwu | 7 | | 3 | lisi | 23 | +----+-----------+------+ 3 rows in set (0.00 sec)
备份主库 备份主库时需要另开一个终端,给数据库上读锁,避免在备份期间有其他人在写入导致数据同步的不一致
[root@yanyinglai ~]# mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 5 Server version: 5.7.22 MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> flush tables with read lock; Query OK, 0 rows affected (0.76 sec) //此锁表的终端必须在备份完成以后才能退出(退出锁表失效)
备份主库并将备份文件传送到从库 [root@yanyinglai ~]# mysqldump -uroot -p123456 --all-databases > /opt/all-20180907.sql mysqldump: [Warning] Using a password on the command line interface can be insecure. [root@yanyinglai ~]# ls /opt/ all-20180907.sql data [root@yanyinglai ~]# scp /opt/all-20180907.sql root@192.168.55.129:/opt/ The authenticity of host '192.168.55.129 (192.168.55.129)' can't be established. ECDSA key fingerprint is SHA256:7mLj77SFk7sPkhjpMPfdK3nZ98hOuyP4OKzjXeijSJ0. ECDSA key fingerprint is MD5:a0:1b:eb:7f:f0:b6:7b:73:97:91:4c:f3:b1:89:d8:ea. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '192.168.55.129' (ECDSA) to the list of known hosts. root@192.168.55.129's password: all-20180907.sql 100% 784KB 783.3KB/s 00:01
解除主库的锁表状态,直接退出交互式界面即可
mysql> quit Bye
在从库上恢复主库的备份并查看是否与主库的数据保持一致
[root@yanyinglai ~]# mysql -uroot -p123456 < /opt/all-20180907.sql mysql: [Warning] Using a password on the command line interface can be insecure. [root@yanyinglai ~]# mysql -uroot -p123456 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 4 Server version: 5.7.22 MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | lisi | | mysql | | performance_schema | | sys | | wangwu | | yan | +--------------------+ 7 rows in set (0.18 sec)
mysql> use yan; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A
Database changed mysql> select * from tom; +----+-----------+------+ | id | name | age | +----+-----------+------+ | 1 | zhangshan | 20 | | 2 | wangwu | 7 | | 3 | lisi | 23 | +----+-----------+------+ 3 rows in set (0.06 sec) 在主数据库创建一个同步账户授权给从数据使用 [root@yanyinglai ~]# mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 7 Server version: 5.7.22 MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> create user 'repl'@'192.168.55.129' identified by '123456'; Query OK, 0 rows affected (5.50 sec)
mysql> grant replication slave on *.* to 'repl'@'192.168.55.129'; Query OK, 0 rows affected (0.04 sec)
mysql> flush privileges; Query OK, 0 rows affected (0.09 sec)
配置主数据库编辑配置文件 [root@yanyinglai ~]# vim /etc/my.cnf [root@yanyinglai ~]# cat /etc/my.cnf [mysqld] basedir = /usr/local/mysql datadir = /opt/data socket = /tmp/mysql.sock port = 3306 pid-file = /opt/data/mysql.pid user = mysql skip-name-resolve //添加以下内容 log-bin=mysql-bin //启用binlog日志 server-id=1 //主数据库服务器唯一标识符 主的必须必从大 log-error=/opt/data/mysql.log
重启mysql服务 [root@yanyinglai ~]# service mysqld restart Shutting down MySQL..... SUCCESS! Starting MySQL.Logging to '/opt/data/mysql.log'. ............................... SUCCESS! [root@yanyinglai ~]# ss -antl State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 *:22 *:* LISTEN 0 100 127.0.0.1:25 *:* LISTEN 0 128 :::22 :::* LISTEN 0 100 ::1:25 :::* LISTEN 0 80 :::3306 :::*
查看主库的状态 mysql> show master status; +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000001 | 154 | | | | +------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec) 配置从数据库 编辑配置文件 [root@yanyinglai ~]# cat /etc/my.cnf [mysqld] basedir = /usr/local/mysql datadir = /opt/data socket = /tmp/mysql.sock port = 3306 pid-file = /opt/data/mysql.pid user = mysql skip-name-resolve //添加以下内容: server-id=2 //设置从库的唯一标识符 从的必须比主小 relay-log=mysql-relay-bin //启用中继日志relay log error-log=/opt/data/mysql.log
重启从库的mysql服务
[root@yanyinglai ~]# service mysqld restart Shutting down MySQL.. SUCCESS! Starting MySQL.. SUCCESS! [root@yanyinglai ~]# ss -antl State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 *:22 *:* LISTEN 0 100 127.0.0.1:25 *:* LISTEN 0 128 :::22 :::* LISTEN 0 100 ::1:25 :::* LISTEN 0 80 :::3306 :::*
配置并启动主从复制 mysql> change master to -> master_host='192.168.55.130', -> master_user='repl', -> master_password='123456', -> master_log_file='mysql-bin.000001', -> master_log_pos=154; Query OK, 0 rows affected, 2 warnings (0.28 sec)
查看从服务器状态
mysql> show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.55.130 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 154 Relay_Log_File: mysql-relay-bin.000003 Relay_Log_Pos: 320 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes //此处必须是yes Slave_SQL_Running: Yes //此处必须是yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 154 Relay_Log_Space: 527 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1 Master_UUID: 5abf1791-b2af-11e8-b6ad-000c2980fbb4 Master_Info_File: /opt/data/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version: 1 row in set (0.00 sec)
ERROR: No query specified 测试验证在主服务器的yan库的tom表插入数据: mysql> use yan; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A
Database changed mysql> select * from tom; +----+-----------+------+ | id | name | age | +----+-----------+------+ | 1 | zhangshan | 20 | | 2 | wangwu | 7 | | 3 | lisi | 23 | +----+-----------+------+ 3 rows in set (0.09 sec)
mysql> insert tom(id,name,age) value (4,"yyl",18); Query OK, 1 row affected (0.14 sec)
mysql> select * from tom; +----+-----------+------+ | id | name | age | +----+-----------+------+ | 1 | zhangshan | 20 | | 2 | wangwu | 7 | | 3 | lisi | 23 | | 4 | yyl | 18 | +----+-----------+------+ 4 rows in set (0.00 sec) 在从数据库查看是否数据同步 mysql> use yan; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A
Database changed mysql> select * from tom; +----+-----------+------+ | id | name | age | +----+-----------+------+ | 1 | zhangshan | 20 | | 2 | wangwu | 7 | | 3 | lisi | 23 | | 4 | yyl | 18 | +----+-----------+------+ 4 rows in set (0.00 sec) |
七、双主+主从架构

/images/layermodel.jp)