本文来自网易云社区
作者:陆秋炜
引言 :很久之前,在做中间件测试的时候,看到开发人员写的代码,有人的代码,看起来总是特别舒服,但有的开发代码,虽然逻辑上没有什么问题,但总给人感觉特别难受。后来成为了一位专职开发人员,渐渐发现,自己的代码也是属于“比较难受”的那种。后来随着代码的增加,编写代码时,总有一些比较乖巧的方式,这就是之前不懂的“设计模式”。之前代码架构比较少(只是写一些测试工具),用不到这些,只有自己慢慢做了一些架构工作后,才用得到,并去主动了解。
但今天想说的,并不是具体的哪一种设计模式的优劣,而是想记录一下,设计模式中存在的一些设计思想。有了这些设计思想,某些设计模式就自然而然的出现了。所以说,所谓的“设计模式”并不是被发明出来的,而是被我们自己“发现”的。
一,设计是一个逐步分解的过程,而不是一个功能合成的过程
之前无论是作为开发还是测试,习惯性的觉得,别人提供了什么功能,就用什么样的功能,这样做天经地义。然而,在自己的架构设计过程中,如果有了这样额思维,很容易让自己的程序设计陷入困境。
打个装修的比喻,我们一定是有设计师设计相关方案(具体的风格),然后分解成对应的家具,然后再购买材料,打造对应的家具。如果我们将这一过程倒过来,先有什么材料,然后看这些材料能打造出什么家具,再把家具组合起来,那么最后的装修效果一定会非常差。
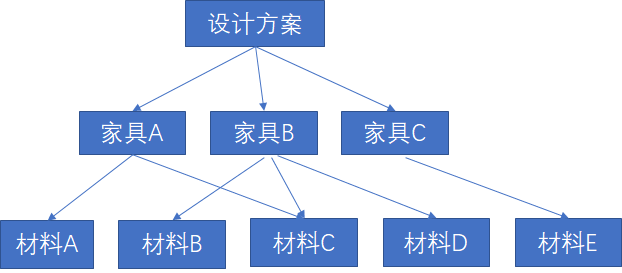
图1 正确的设计方式
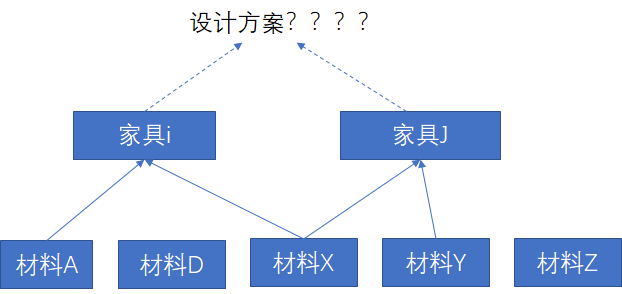
图2 自底向上的设计结果,一定是最后的整合有问题
所以优秀的设计一定是从整体到局部设计出来的。从局部构造整体,不可能得到优秀的设计。
二:对于一个整体的概念性理解,一定是在理解最初的功能(实现目标)为基础的
了解清楚某个功能模块(或者整个功能)具体要干什么事情,我们才能够知道具体要如何做设计。而不是找一个设计方案,能够实现主要功能就行了,其他功能再次基础上修修补补。
再举一个简单的例子:比如说我们要喝水(表面功能/基础目标),那么我们就需要找相关盛水的容器(设计实现)。我们找到了以下容器(可能的实现方案):

图三 各种盛水容器的实现
三种容器都能喝水,但具体要使用哪个呢?如果随便选一个酒杯,但具体实现(或者未来可能的功能)要求能够带到户外去,总不能给酒杯再加个盖子吧;同理,如果我们要品酒,却选了个保温杯的实现,到时候直接设计推倒重来了。所以,要有合适的设计,一定要对产品本身的需求(以及未来可能的需求)做详细的分析和了解,然后确定设计方案。
三:在设计关联关系时,优先使用对象组合,而非继承关系
在学习“面向对象”的语言时,我们首先被教会“封装、继承、多态”。从此,感觉有点关系的都要进行继承,觉得这样能节省好多代码。然后我们的代码中便出现了继承的乱用
正常情况下,这样做没有问题,但问题的起源在于,我们的需求是不断的修改和添加的,如果使用了继承,在超类中的方法改动,会影响到子类,并可能引起引起子类之间出现冗余代码。
举个汽车的例子吧,一辆汽车开行(drive)是一样的,但车标(logo)是不一样的,所以用继承
public abstract class Car { /**
* 驾驶汽车
*/
public void drive(){
System.out.print("drive");
} /**
* 每辆车的车标是不一样的,所以抽象
*/
public abstract void logo() ;
}class BMW extends Car{ @Override
public void logo() {
System.out.print("宝马");
}
}class Benz extends Car{ @Override
public void logo() {
System.out.print("奔驰");
}
}class Tesla extends Car{ @Override
public void logo() {
System.out.print("特斯拉");
}
}
一切看起来解决的很完美。突然加了一个需求,要求有个充电(change)需求,这时候,只有特斯拉(tesla)才有充电方法。但如果使用继承,在父类添加change方法的同时,就需要在BMW和Benz实现无用的change方法,对于子类的影响非常大。但如果使用组合,使用ChangeBehavior,问题就得到了有效解决,
public interface ChargeBehavior { void charge() ;
}public abstract class Car { protected ChargeBehavior chargeBehavior ; /**
* 驾驶汽车
*/
public void drive(){
System.out.print("drive");
} /**
* 每辆车的车标是不一样的,所以抽象
*/
public abstract void logo() ; /**
* 充电
*/
public void change(){ /**
* 不用关心具体充电方式,委托ChargeBehavior子类实现
*/
if (chargeBehavior!=null) {
chargeBehavior.charge();
}
}
}class Benz extends Car{ @Override
public void logo() {
System.out.print("奔驰");
}
}class BMW extends Car{ @Override
public void logo() {
System.out.print("宝马");
}
}class Tesla extends Car{ @Override
public void logo() {
System.out.print("特斯拉");
} public Tesla() { super();
chargeBehavior = new TeslaChargeBehavior() ;
}
}class TeslaChargeBehavior implements ChargeBehavior{ @Override
public void charge() {
System.out.print("charge");
}
}
通过将充电的行为委托给changeBehavior接口,子类如果不需要的话,就可以做到无感知接入。
这样的代码有三个优势
-
1,代码不需要子类中重复实现
-
2,子类不想要的东西,可以无感知实现
-
3,子类运行的行为,可以委托给behavior实现,子类本省本身无需任何改动
四:对于接口和类的再次理解
在刚刚接触面向对象的时候,封装,对我们来说就是类,实例化后就是对象。最基本功能是对于数据进行隐藏,对于行为进行开放(如JavaBean)。慢慢用多了以后渐渐发现,其实我们可以封装跟多东西,比如某些实现的细节(私有方法方法),实例化规则(构造器)等。
1,对于变化本身进行封装
由于我们的代码是分层和分模块的,但我们的需求又是经常要变化的,我们希望修改新功能,对于除了模块本身外,调用方是无感知的。所以,我们的类(或者说是模块吧)变封装了变化本身。对于调用方来说,只需要知道不会变的功能名(方法名)就够了,而不需要了解可能变化的内容。

图四 变化本身进行封装
2,从共性和可变性到抽象类
在一类实现中,我们其实可以分析发现,代码的实现上是有一些共性的,比如说处理的流程(如何调用一些方法的顺序),也有一些完全一致的操作(比如上文提到的car都可以drive,实现一致的方法)。但也有一些可变性:如必须存在(共性),但实现不一致的操作(如上文car里面的logo方法,必须有,但不一致)。这时候,我们就可以对这些实现进行一些简单的抽象,成为抽象类。抽象类就是将共性变为以实现的方法,而将可变性变为抽象方法,让子类予以实现。

图五,共性和抽象类
总结:
代码看多了,写多了,便会发现,看起来舒服的代码,在可维护性,可读性,可扩展性上相对来说都比较高。代码界也有“颜值即战斗力”这一说法,颇有一番玄学的味道。但分析具体的原因,其实可以发现,优秀的编码设计,在其抽象,封装,都有其合理之处,其整体的架构设计上,亦有其独到之处。
网易云大礼包:https://www.163yun.com/gift
本文来自网易云社区,经作者陆秋炜授权发布
相关文章:
【推荐】 流式断言器AssertJ介绍