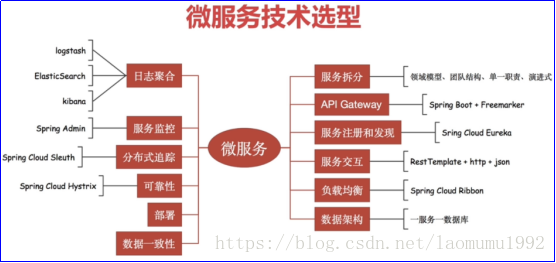
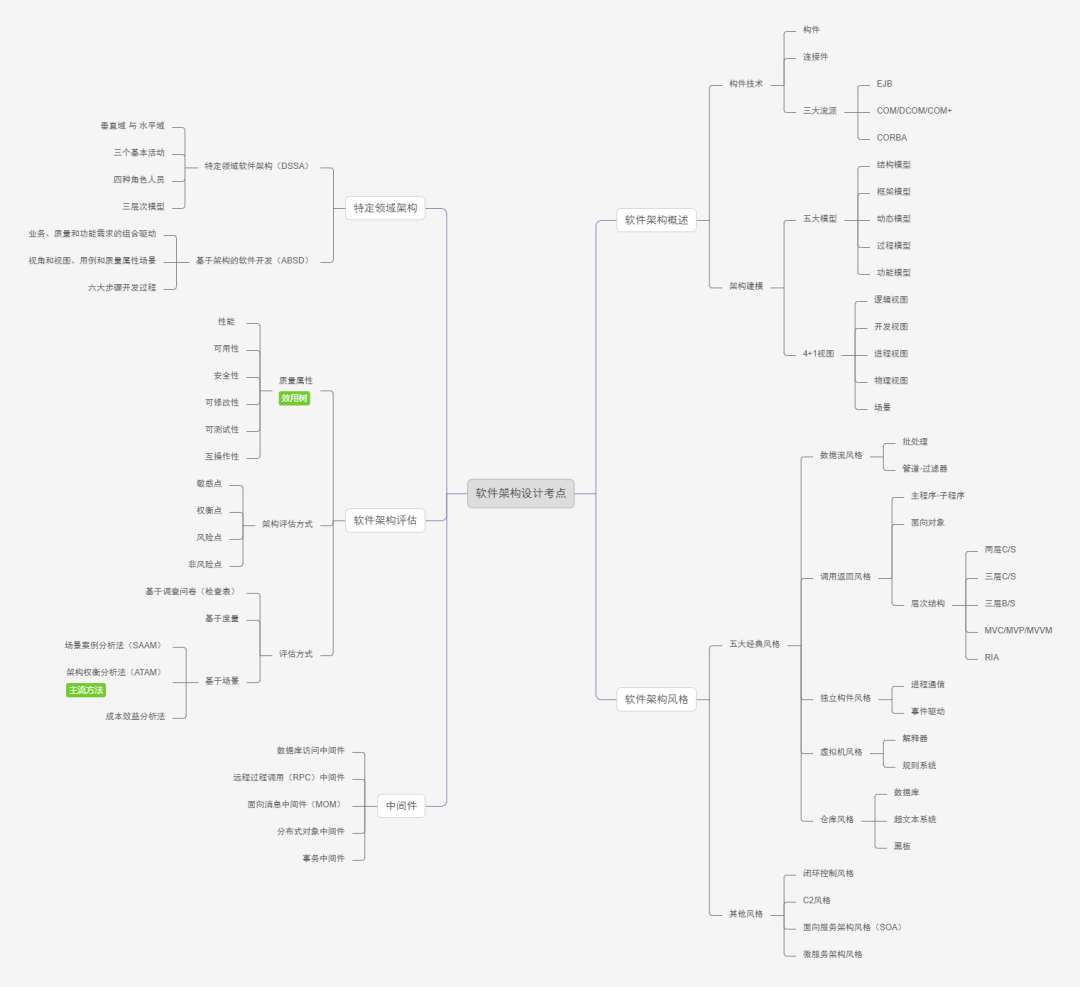
一、设计高扩展架构
1、架构设计复杂度模型
一个架构的复杂度可以分为业务复杂度和质量复杂度。
业务复杂度:指业务本身的复杂度,主要体现在难以理解、难以扩展,例如支付宝、保险、金融等
质量复杂度:指的是系统对于高性能、高可用、高扩展等质量要求。
在做架构时,首先要分析系统的复杂度模型。
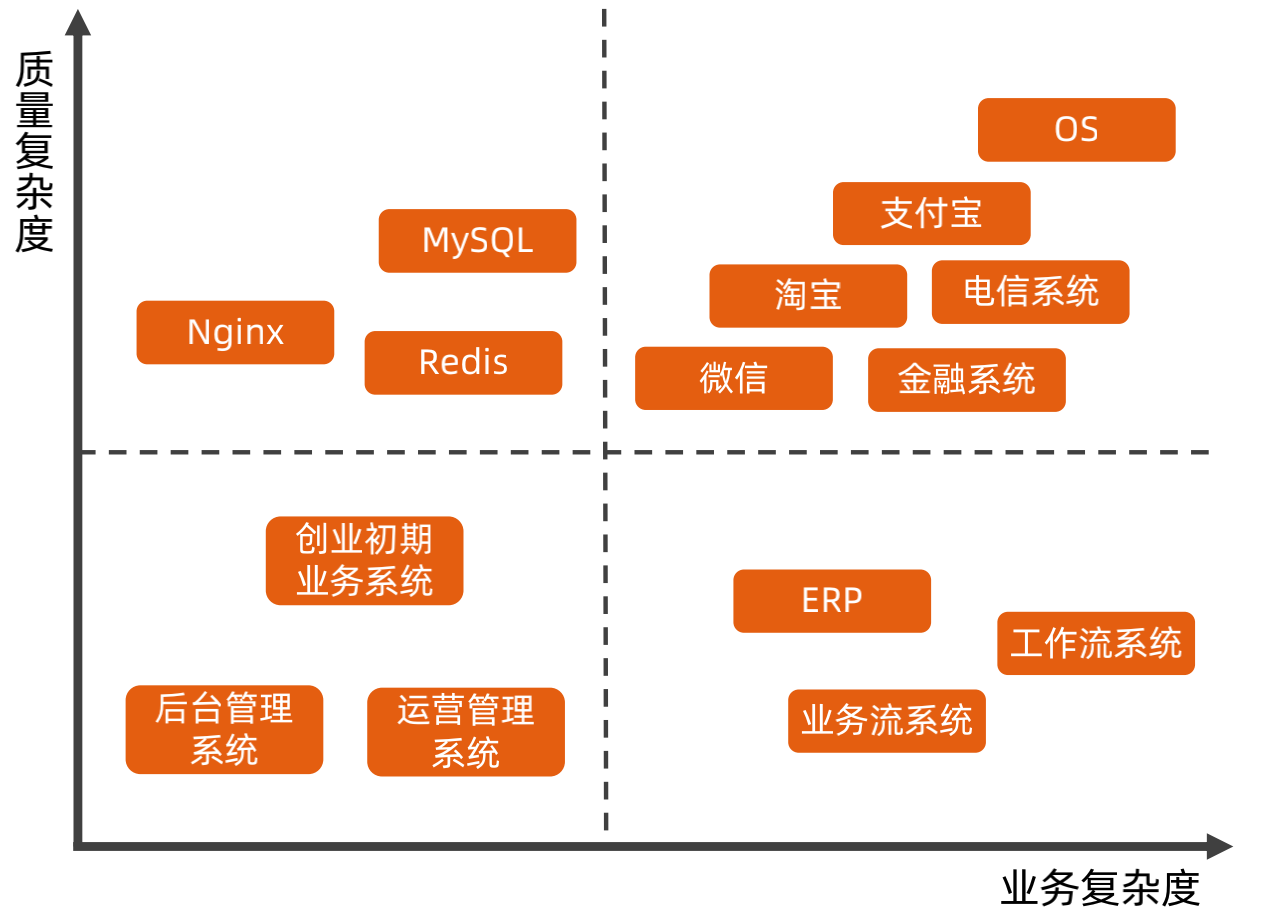
对于架构复杂度,需要根据不同的复杂度采用不同的策略进行实现。

对面面向复杂度的设计环,针对于复杂度的拆解,就是分析系统的业务复杂度和质量复杂度。
2、可扩展复杂度模型
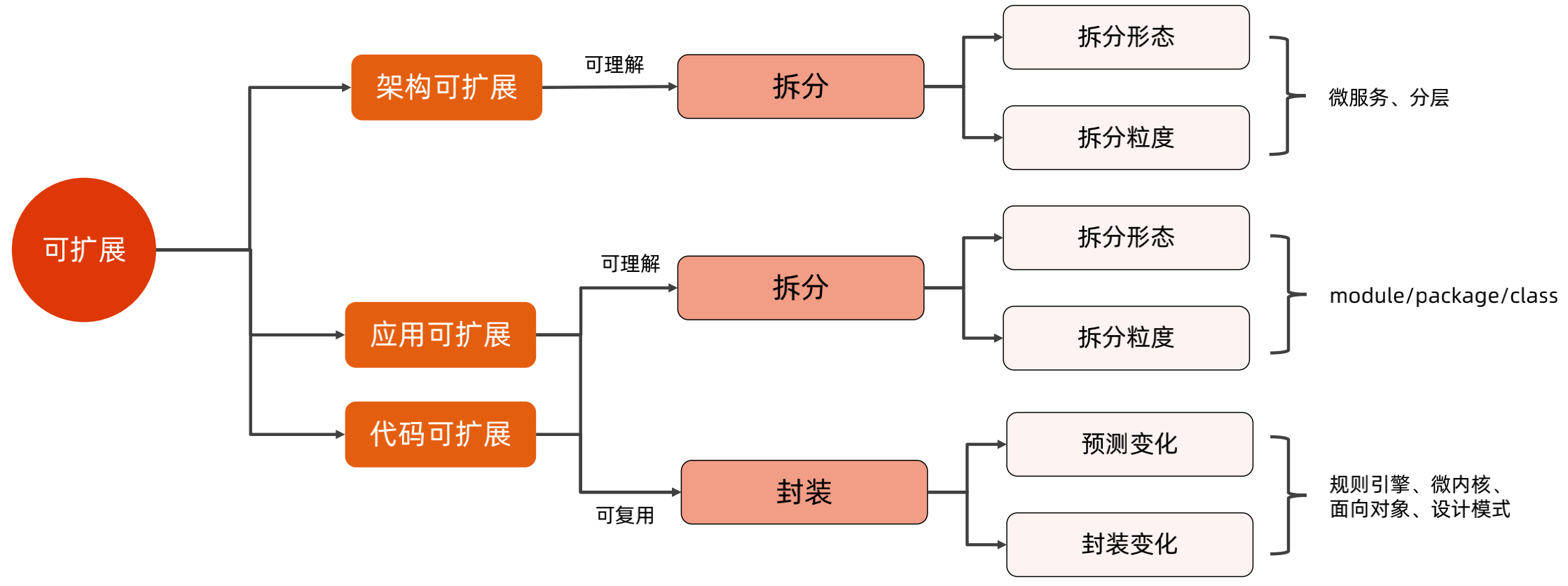
可扩展可以拆分为可扩展和可伸缩,其中的可扩展表示系统的适应能力,包含可理解和可复用两部分;可伸缩表示可以通过增加资源来提升系统性能。
可扩展可以分为:架构可扩展、应用可扩展、代码可扩展三个维度。
架构可扩展,表示为可理解,然后通过拆分形态和拆分力度,将整个系统进行分层和微服务拆分。
应用可扩展和代码可扩展,可以分为可理解和可复用,可理解也是使用拆分形态和拆分力度进行拆分;可复用则使用分装,预测变化和封装变化
3、“拆分”复杂度分析和设计
鸡蛋篮子理论第一法则:拆分法则
从上面可以看到,对于可扩展架构的设计主要使用了拆分和封装,这里先讲拆分。
拆分复杂度模型:
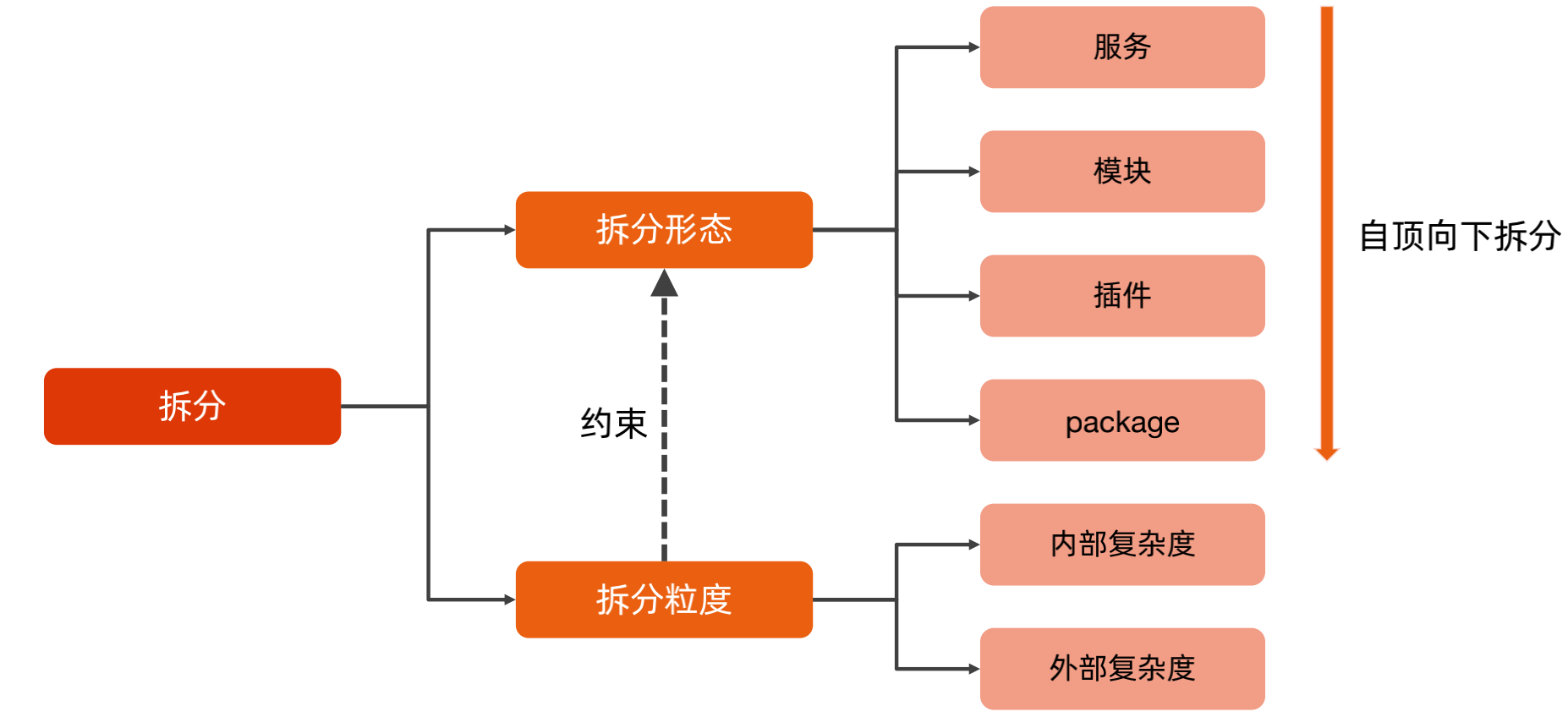
对于拆分来说,主要有拆分形态和拆分力度,拆分形态可以自顶向下进行拆分,首先拆分服务,然后拆分模块,再拆分插件和包;但是不能拆的太粗也不能拆的太细,那么拆分粒度就是用来衡量和约束拆分形态的,主要分为内部复杂度和外部复杂度。
内部复杂度又称为单体复杂度,也就是一个服务的复杂度,可以用开发人数来粗略判断内部复杂度,一般来说3人的开发团队是对合适的,如果20个人在开发一个系统/模块,那么内部复杂度就非常高了。
外部复杂度又称为群体复杂度,指拆分后多个服务直接的复杂度,可以使用整个业务流程有多少服务参与来衡量外部复杂度,一般来说一个请求有5个项目参与是比较合理的,如果需要20个系统参与,那么外部复杂度就太高了。
那么对于拆分来说,要遵循内外平衡和先粗后细两个原则进行拆分。
4、“封装”复杂度分析和设计
封装复杂度主要是预测变化,在预测变化的结果上进行封装。
预测变化主要考虑时间跨度和变化方式,预测最大的挑战就是有可能最终走向和我们预测的不一致,那么进行预测时,需要遵循2年法则和三次法则:
两年法则:一般预测两年内的变化进行封装
三次法则:如果对于预测没有把握,就先不要预测,一写二抄三封装,等到第三个类似的情况再进行封装。
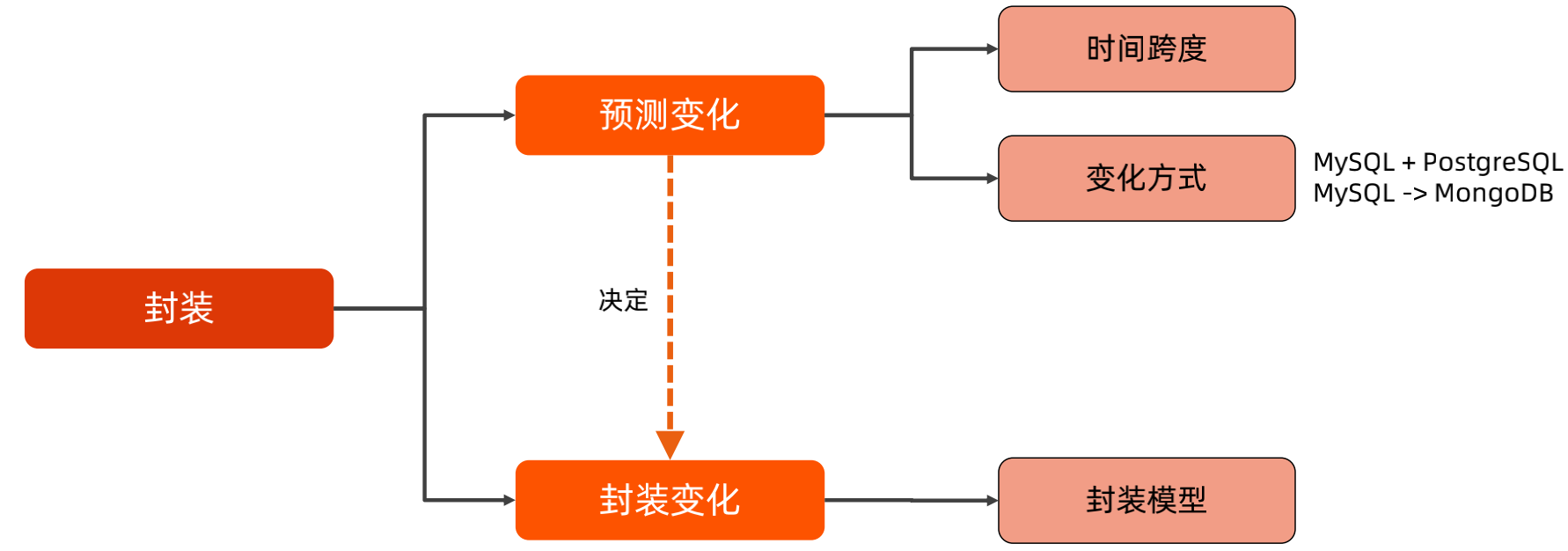
封装的技巧:
封装是封装变化,在封装时要设计封装模型,例如使用规则引擎、微内核、抽象层、设计模式等

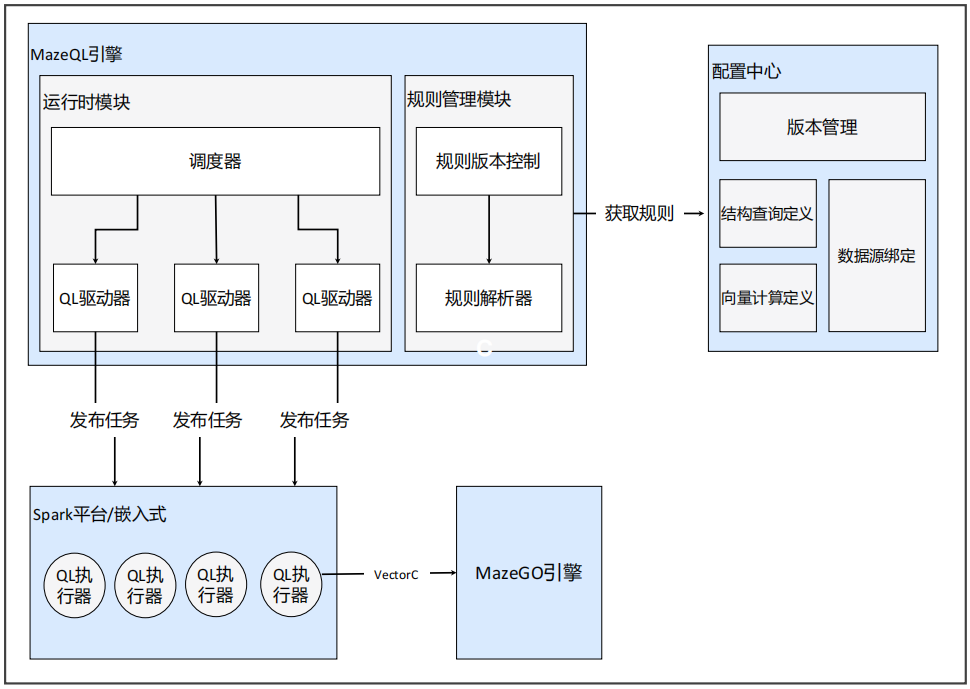
(1)规则引擎:美团MazeGO规则引擎
下图时美团MazeGO规则引擎,配置中心用于提供规则配置视图,规则管理模块用于获取规则和解析规则,运行时模块用于发布和调度任务执行,平台嵌入层负责实际执行规则逻辑。
(2)微内核:OSGI微内核
OSGI 框架从概念上可以分为三层:模块层、生命周期层、服务层;模块层主要涉及包及共享代码,控制单元为Bundle;生命周期层主要涉及Bundle的运行时生命周期管理;服务层主要设计模块之间的交互和通信。

(3)抽象层:Linux VFS抽象层
Linux VFS 对应用层提供一个标准的文件操作接口,对文件系统也提供一个标准的接口,以便于其他操作系统的文件系统可以很好的移植到Linux上。

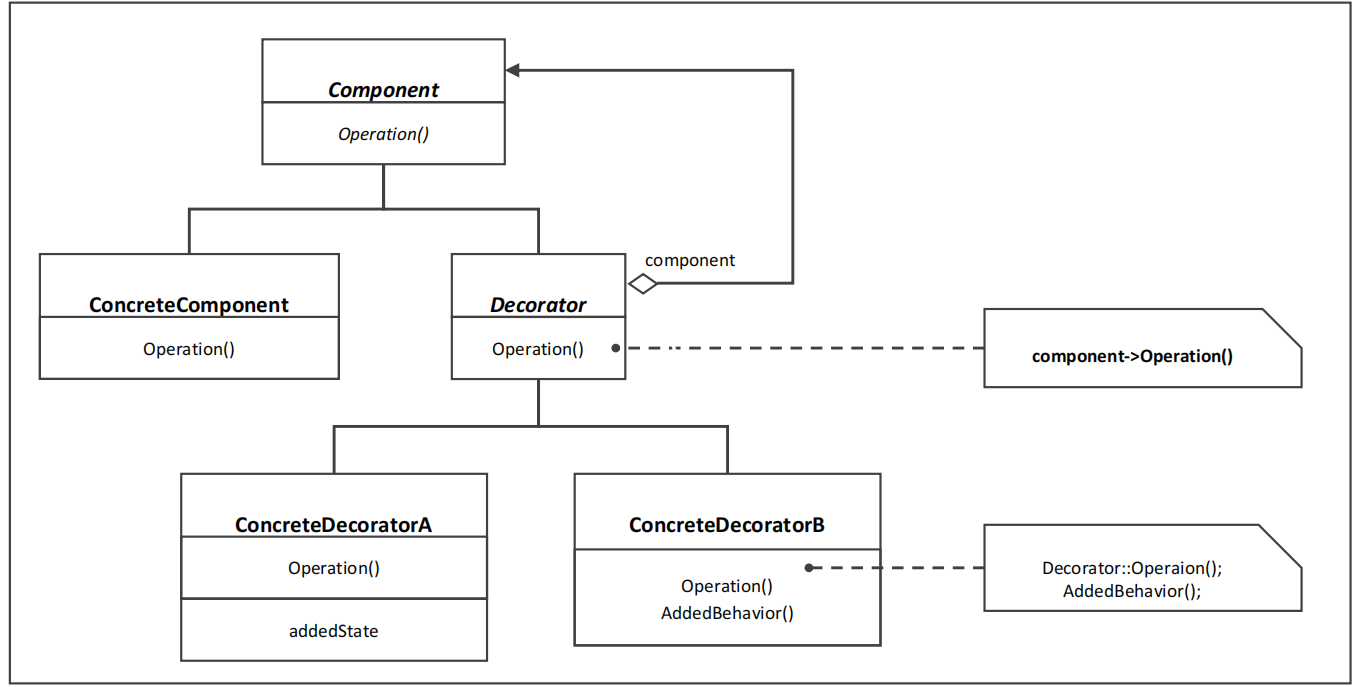
(4)设计模式
二、设计高性能架构
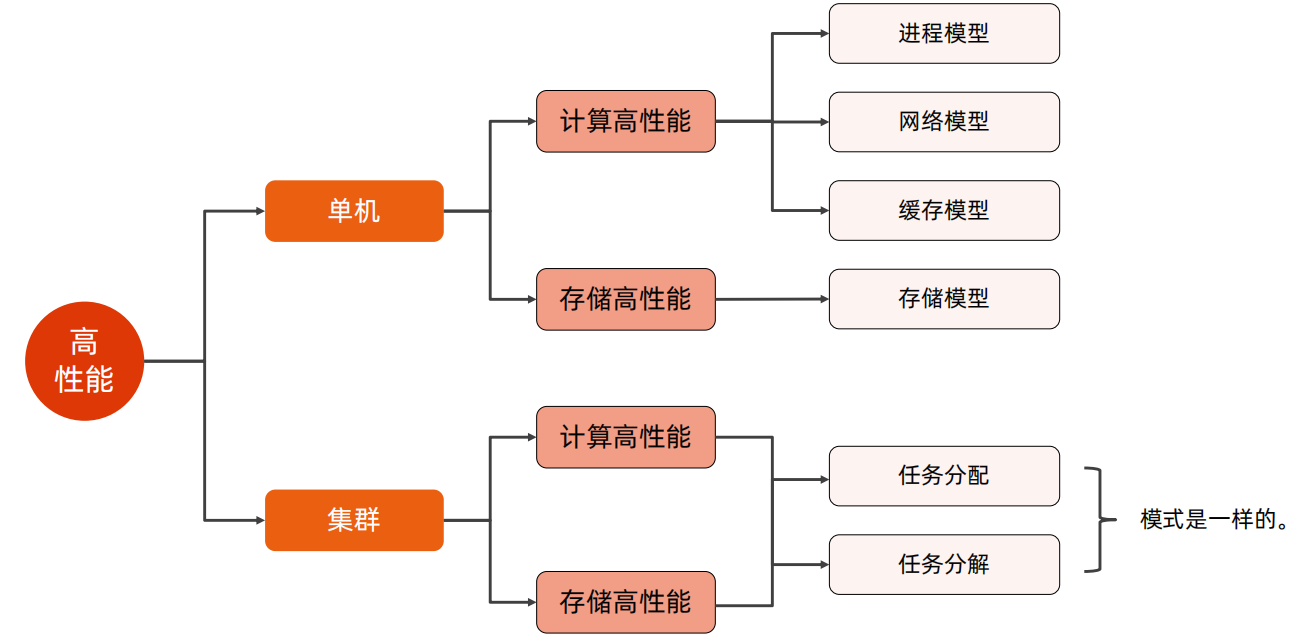
高性能复杂度模型可以分为单机高性能和集群高性能,其都可以分为计算高性能和存储高性能,但是在单机高性能中,计算高性能主要使用进程模型、网络模型、缓存模型来提升、存储高性能使用存储模型来提升,而在集群高性能中,无论是计算高性能还是存储高性能,都是通过任务分配和任务分解进行提升的。
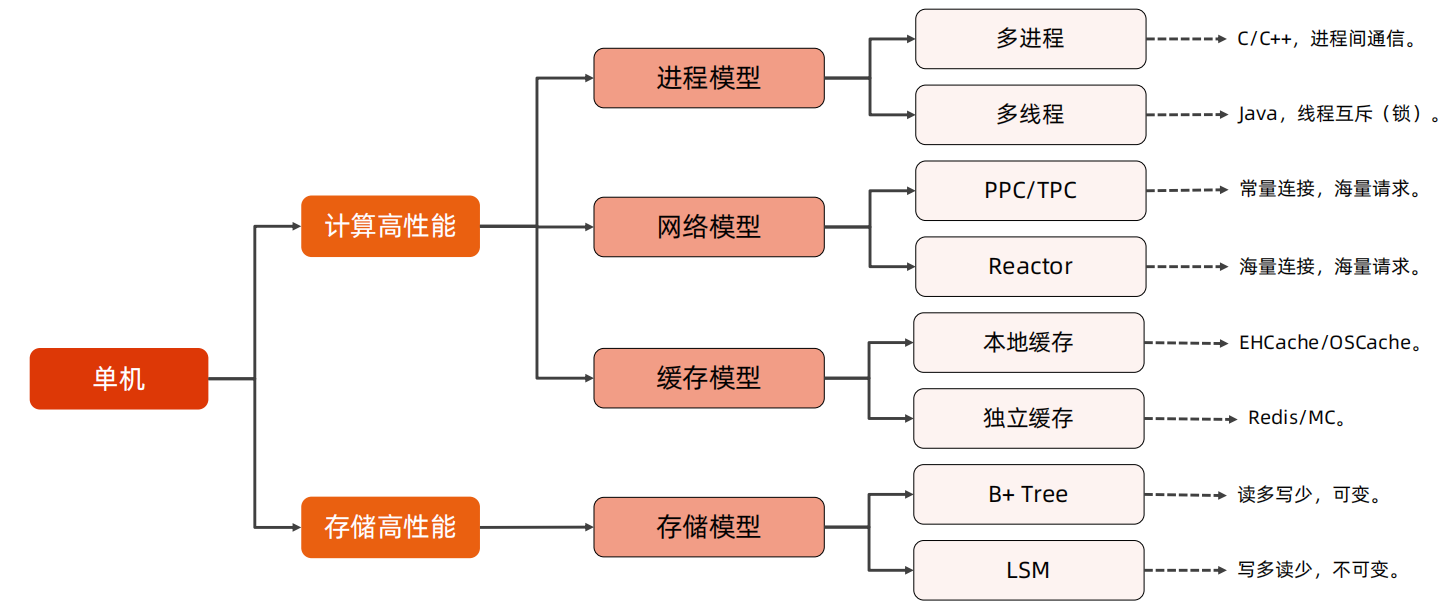
单机高性能:
对于单机高性能,主要是各种编程技巧,其实和架构的关系不太大,例如进程模型可以使用多进程、多线程的方式,网络模型可以采用PPC、TPC、Reactor的方式,缓存模型可以使用本地缓存和独立缓存的方式,存储模型可以使用B+ Tree、LSM的方式
集群高性能:
鸡蛋篮子理论第二法则:叠加法则
(1)任务分配
任务分配即将任务分配给多个服务器执行,对于任务分配的节点,可以使用SDK的方式,也可以使用独立部署的方式;同时任务分配器需要管理所有的服务器,其可以通过配置文件或者配置中心的方式进行管理;同时任务分配器还需要根据不同的需求采用不同的分配算法。
任务分配器应该便面单点,也应该是一个集群,需要更高一层的分配器进行分配。

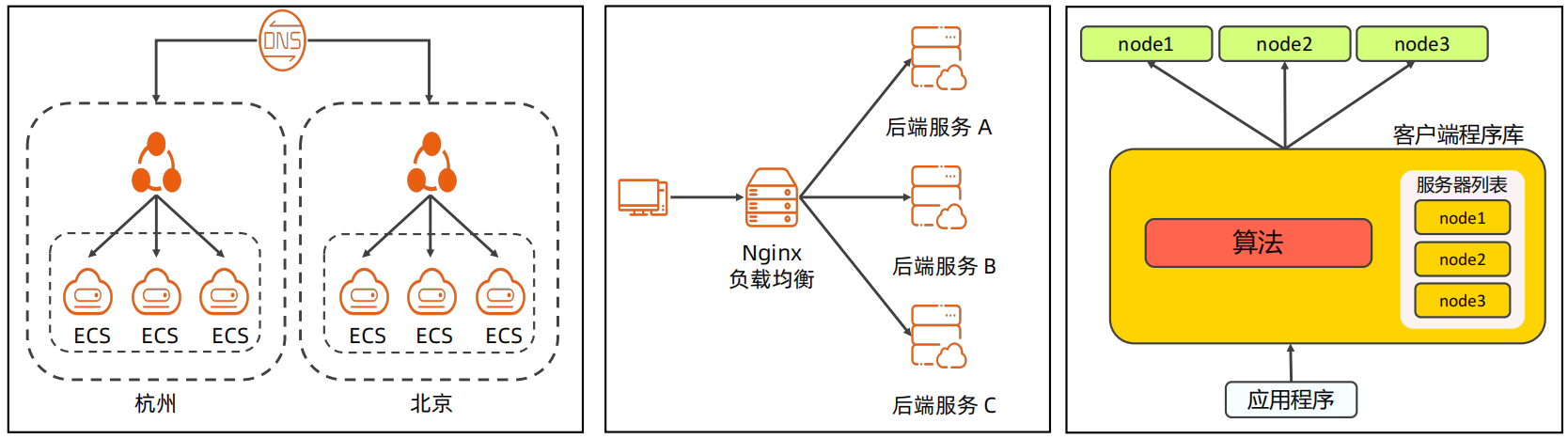
任务分配样例:
下面是三个任务分配的样例,分别是DNS、Nginx、Memcached的分配方案,其中
DNS使用独立部署、配置文件、DNS解析规则的方式进行分配,其主要用于对于机房级别、地理位置级别的任务分配
Nginx使用独立服务器、配置文件、负载均衡算法的方式进行分配,其主要用于服务级别的任务分配
Memcached使用SDK、代码配置、一致性hash的方式进行分配,其主要用于系统内部的任务分配。
(2)任务分解
将任务分解为不同的角色,不同的角色承担不同的任务。
和任务分配一样是需要增加任务分解器,任务分解器可以通过独立部署或者SDK的方式进行任务分解,任务分解器需要管理所有的服务,可以通过配置文件或配置中心的方式进行管理
和任务分配器不同的是,任务分解器需要记录任务和角色的对应关系,同时任务分解器需要根据不同的需求采用不同的算法分配。
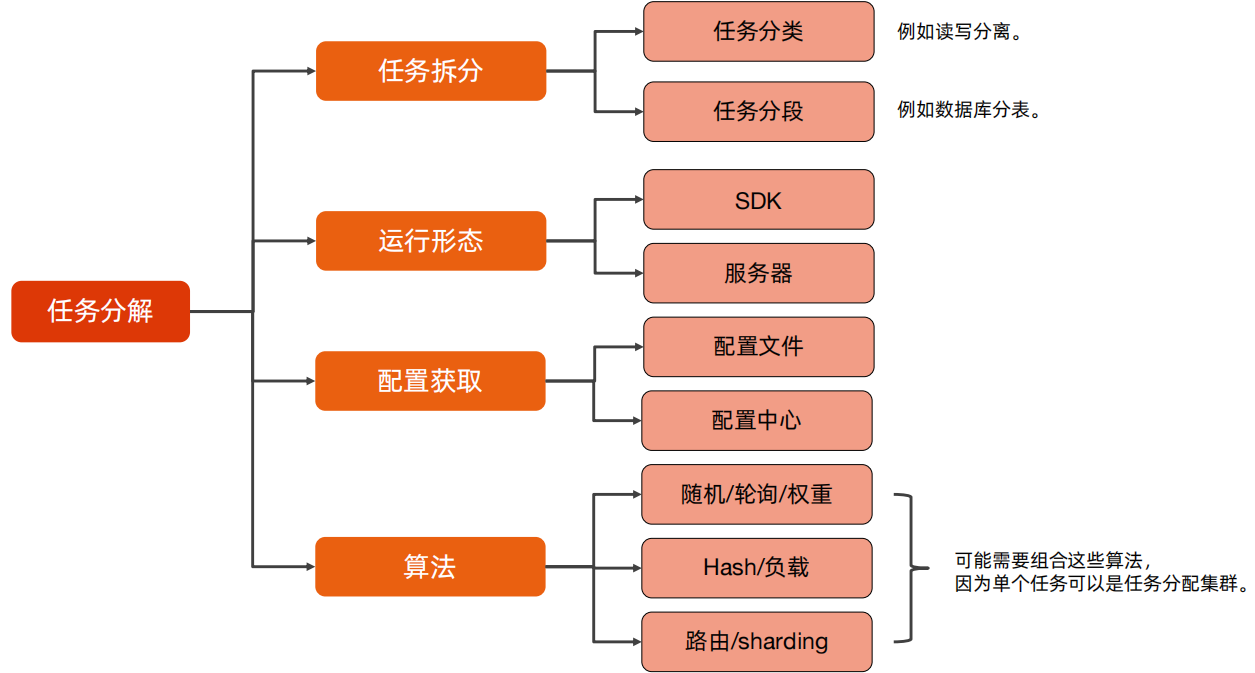
可以看到,任务分解比任务分配多了一个任务拆分,在任务拆分中,可以使用任务分类和任务分段进行拆分,任务分类,例如说读写分离等,任务分段,例如数据库分表等;除了由任务拆分的差异外,在算法上,也新增了路由、sharding的负载均衡算法。
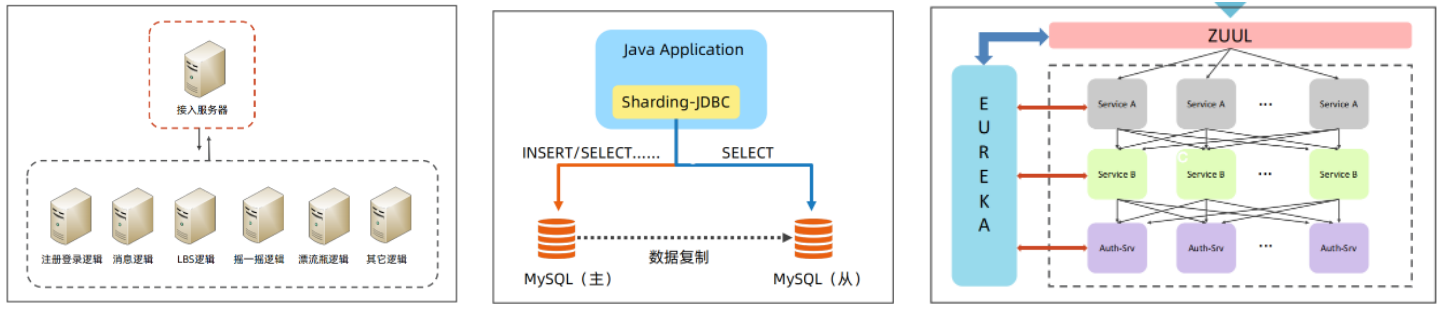
任务分解样例:
下面三个样例:微信服务拆分、数据库读写分离、zuul,微信服务拆分其是按照业务逻辑进行的服务分解,独立接入服务器;数据库读写分离是将任务拆分为了读和写两种,mysql使用主从,使用SDK的方式将任务分解器集成到代码中,并通过配置文件进行配置分解规则;zuul是按照服务拆分,任务分解器独立部署,配置使用Eureka,负载均衡使用Ribbon。
三、设计高可用架构
1、高可用复杂度模型:
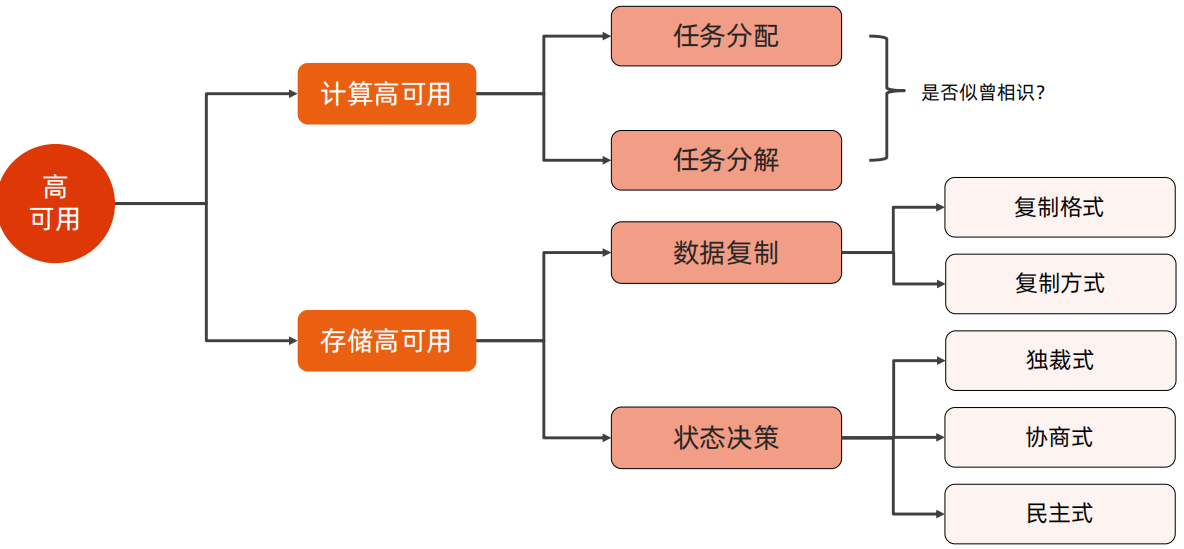
高可用可以分为计算高可用和存储高可用,计算高可用也是通过任务分配和任务分解来实现的,对于存储高可用,主要体现在数据复制和状态决策。
鸡蛋篮子理论第三法则-冗余法则
2、计算高可用
高可用和高性能的任务分配侧重点是不一样的,高性能的侧重点在于正常情况下如何提升性能,高可用侧重点在于故障如何处理,因此在高可用的任务分配设计时,要着重考虑状态检测,如果出现故障,需要及时进行切换。
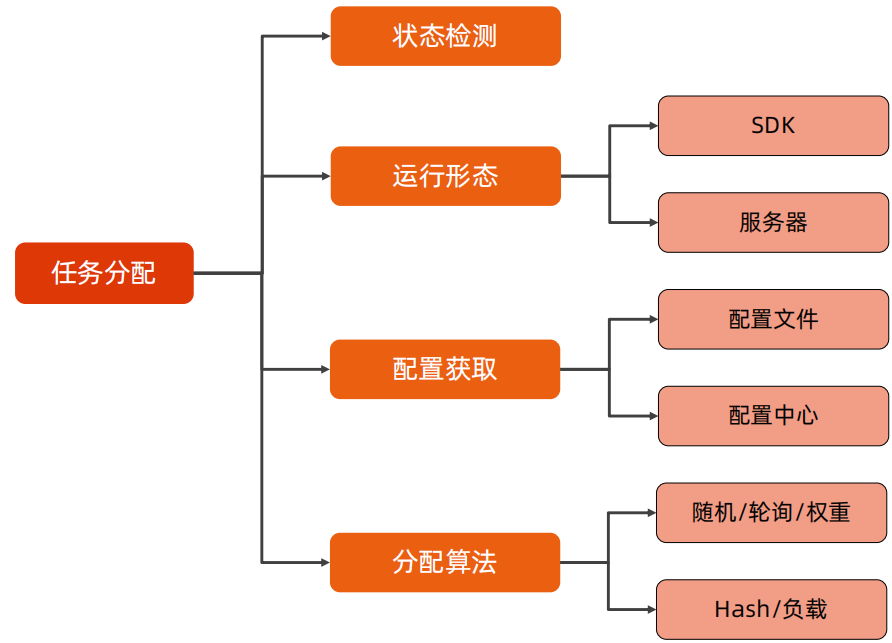
高可用和高性能的任务拆解和任务分配一样,同样是侧重点不一样,因此在高可用的任务分解时,要监控业务服务器状态,如果出现故障,要及时进行切换。
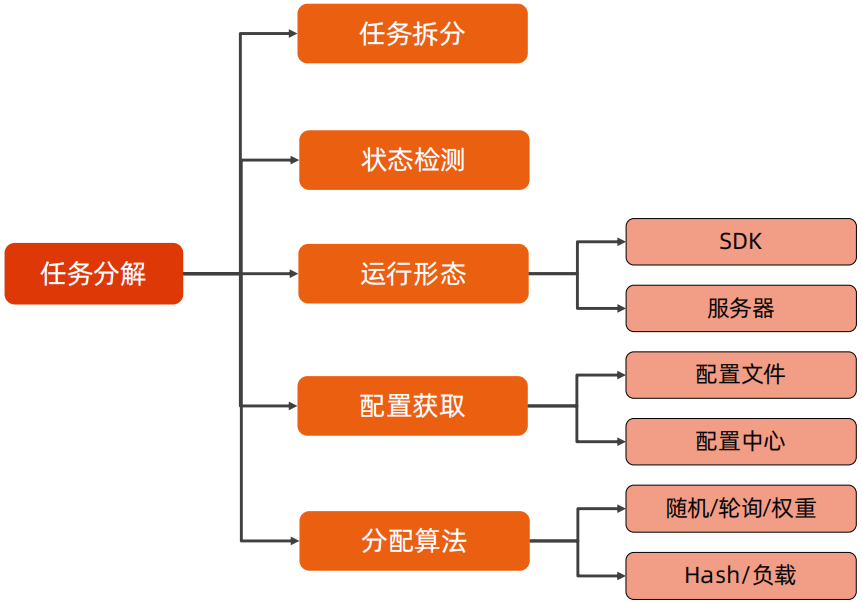
计算高可用样例,仍然使用微信服务拆分的这个例子,按照业务逻辑划分服务器集群,独立接入服务器。
3、存储高可用

存储高可用主要以数据复制和状态角色来保证高可用,数据复制需要从复制格式、复制方式两个维度进行设计,状态决策主要选择以何种方式进行状态切换等。
(1)数据复制
数据复制格式
数据复制格式主要有:复制数据、复制命令、复制文件三种方式。
复制命令:优点是实现简单,复制数据量小,缺点时有可能会造成数据不一致,主要的应用场景是增量复制的场景
数据复制:优点是实现简单,保证数据一致性,缺点是复制流量可能会很大,主要应用场景是增量复制的场景
复制文件:其实现比较复杂,因为在复制的时候数据是在动态变化的,但是其可以保证数据的一致性,但是复制流量可能会很大,主要应用场景是在全量复制的场景。
数据复制方式
数据复制方式主要有:同步复制、异步复制、半同步复制、多数复制四种方式
同步复制:优点是其可以保证强一致性,数据安全性高,但是数据写入的性能比较低,故障容忍度低;主要用应场景是主备或主从架构
异步复制:优点是写入性能高,故障容忍度高,但是容易出现数据不一致的情况;主要应用场景是数据存储集群
半同步复制:其是同步复制和异步复制的这种方案,设置一定数量的复制节点使用同步复制,其余的节点使用异步复制,在数据复制时,有一定数量的复制节点复制成功,即认为成功;主要的应用场景是数据存储集群。
多数复制:其是对于半同步复制的一个特例,就是同步复制的数量是集群节点的一半以上。优点是数据一致性强,可用性高,故障容忍度高,缺点是写入性能不高,实现复杂;应用场景是分布式一致性、分布式协同等,例如ZK、OceanBase等。
高可用存储数据复制样例
以redis和mysql为例,在redis中,数据复制格式使用了 命令(AOF) 和 文件(RDB) 的方式,复制方式采用了 异步复制 和 wait(指定半同步) 方式;在mysql中,数据复制格式采用了命令(statement) 和 数据(row)的方式,数据复制方式采用了异步和半同步的方式。

(2)状态决策
状态角色主要有独裁式、协商式、民主式三种。
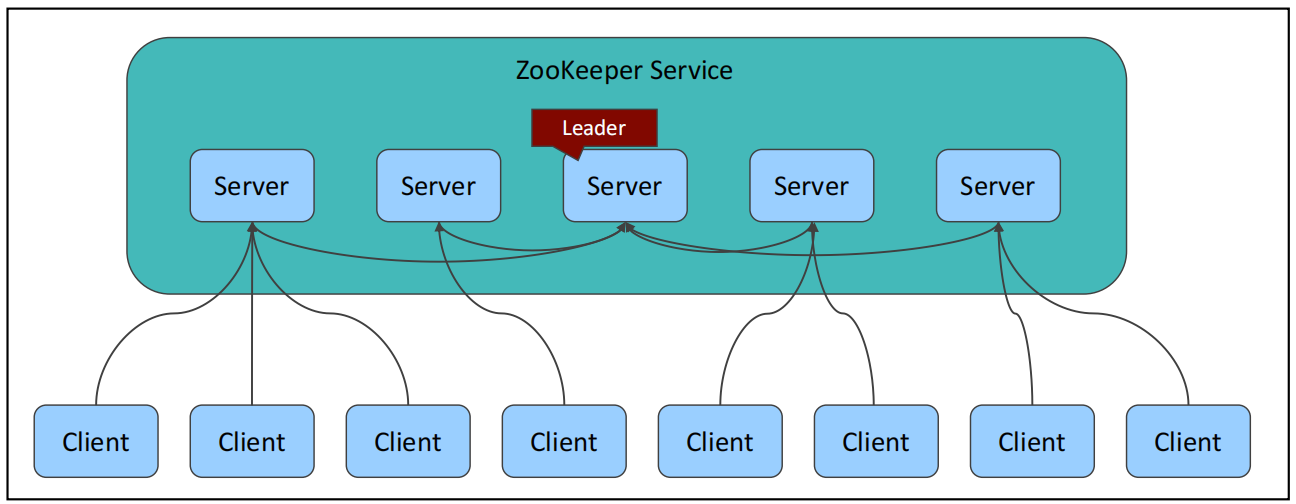
独裁式:独裁式主要是有一个决策者来进行状态判断和故障时服务切换的,其优点是决策逻辑简单,缺点是决策者要做到高可用,整体架构比较复杂,常用zk、Raft、Keeplived来保证决策者的高可用,同时其数据一致性强度中等。这种方案可以用在大多数的场景中。
协商式:协商式是指主备两个节点,通过心跳检测进行决策,其优点是架构实现简单,决策逻辑简单,一般使用心跳检测即可,缺点是链路问题,如果发生了网络故障,可能导致双主的情况,不过这个可以使用双通道来缓解该问题,另外一个问题就是数据一致性较弱;其主要的应用场景是内部系统、网络设备等。
民主式:民主式就是需要通过选举来选举出决策者,优点是可用性高,数据一致性强,缺点是决策过程复杂,决策逻辑复杂,一般需要使用算法解决,例如Raft、ZAB、Paxos等,还可能会出现脑裂问题,不过脑裂问题可以使用quorum来控制。其主要的应用场景是对数据一致性要求很高的场景,例如余额、库存等。
状态决策样例:
独裁式:以redis sentinal和hadoop为例,在redis sentinal中,使用sentinal进行决策,同时采用Sentinal集群来解决决策者的单点问题,sentianl使用Raft算法来进行选举;在Hadoop中,NameNode是集群决策者,同时其使用Zookeeper来解决决策者的单点问题。

民主式:以Zookeeper和Mongo为例,在Zookeeper中,其基于ZAB协议进行选择决策者,在Mongo中,在3.2.0之前使用bully算法,在3.2.0开始使用Raft算法选择决策者。

四、提升架构设计的质量
1、低成本
低成本本质上是对架构的一种约束,与高性能架构是冲突的,在进行架构和成本之间的决策,首先进行架构方案设计,然后再看如何降低成本。
降低成本的方式主要体现在优化和创新:

对于降低成本来说,主要体现在互联网大规模集群和 To B 业务,以互联网业务来说,单机性能增加一点点,就可以节约很大的资源,ToB业务来说,如果节约100W,那么就多了100W的利润。但是对于其他业务来说,增加机器反而是成本最低的架构设计方案,因为优化也需要人力和时间,有可能优化的结果使用的成本要远远高于优化带来的收益。
2、安全性
系统的安全性分为架构安全和业务安全。
架构安全主要采用网络隔离、流量清洗、机房切换的方式进行处理,在互联网场景中,主要使用的是流量清洗和多机房,在企业内部应用场景中,可以部署专业的防火墙进行处理。
业务安全主要有业务漏洞、安全隔离、内鬼破坏等,业务漏洞是需要进行保底限制的,例如每个用户最多买多少,每天最多补多少等;安全漏洞需要使用安全框架来保证,例如使用OWASP等;内鬼破环可以使用权限管理,对不同用户可操作内容进行限制,可以使用Shiro、Spring Secrity等。

但是架构设计只能保证架构安全问题,不能解决业务安全问题,业务安全主要是靠编码和管理方面的措施来处理。
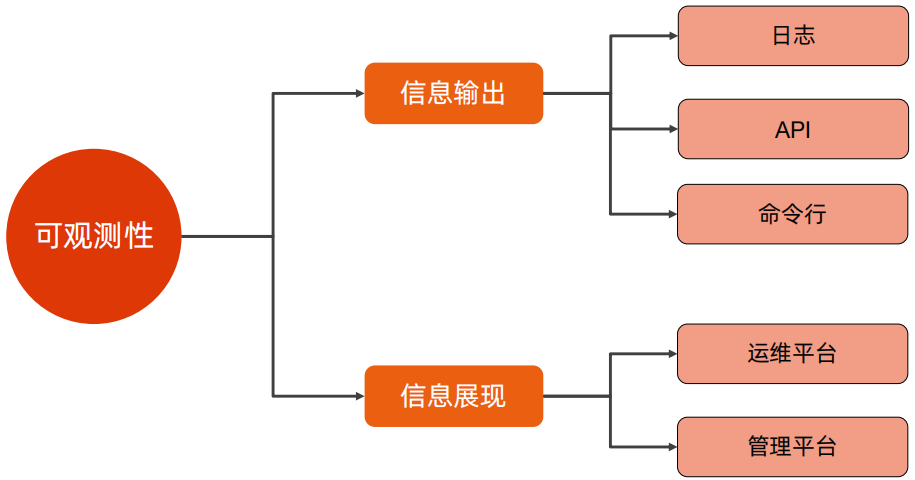
3、可测试性/可维护性/可观测性
可测试性是指软件在测试环境下能否方便的支持测试各种场景的能力;可维护性是指软件支持定位问题、修复问题的能力;可观测性是指软件对外展现内部状态的能力;可观测性是可测试性、可维护性的基础。
可测试性和可维护性都是通过架构和应用两个方面进行支持,在应用方面,可测试和可维护是一致的,都是变量可修改、状态可见、行为可手动修改。但是对于架构来说,可测试主要体现在可以手动的出发架构上设计的点,例如手动切换主备、手动触发选举等,并且可以做全链路压测;但是对于可维护来说,可以进行全链路追踪和对系统的运维,例如降级、下线、切换等。


可观测性主要考虑信息输出和信息展现两个方面,信息输出可以是日志、API、命令行等,信息展示的话,可以使用运维平台和管理平台进行展示。
那么如何设计出一个更好的架构呢?那就是在做好架构后,在成本、安全、可测试性、可维护性、可观测性等方面进行迭代和完善,最终达到一个更好的架构。
五、高性能案例分析:微信红包
以2014年微信团队公布的数据为例,除夕这一天,482万人参与了抢红包,零点时刻,瞬间峰值达到2.5万个红包被拆开,前5分钟内有58.5万人次参与了抢红包,其中12.1万个红包被领取。
系统的性能是用峰值 TPS/QPS 来衡量的,红包业务可以拆分为发红包、拆红包、看红包,从上述描述来看,发红包的TPS在2.5万TPS,假设每个红包有20个人抢,那么拆红包的TPS为50W,假设每个红包有10个人会查看抢红包的记录,那么看红包的TPS为25W。
对于高性能架构来说,主要体现为单机高性能和集群高性能,其都包含计算高性能和存储高性能。
对于高性能架构设计,根据高性能复杂度模型逐个分析即可。
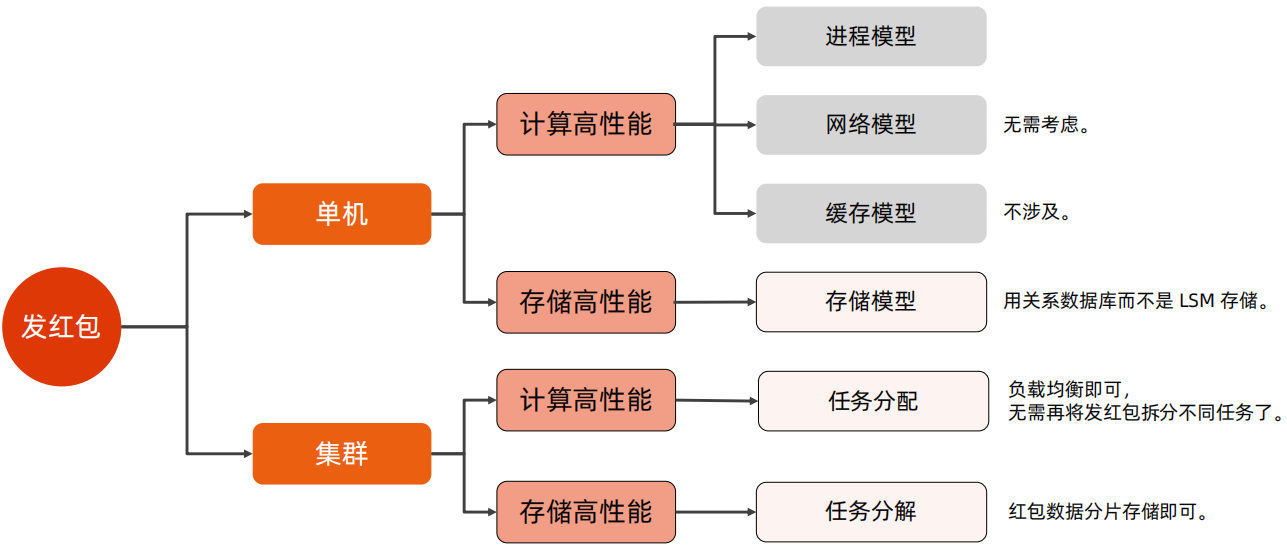
1、发红包
在发红包场景中,无需考虑单机计算高性能,需要考虑单机存储高性能,这里可以是用关系型数据库来进行处理。集群中计算高性能可以使用任务分配,即负载均衡即可;集群存储高性能,将数据分片存储即可。
发红包的高性能解决方案和架构图如下所示:

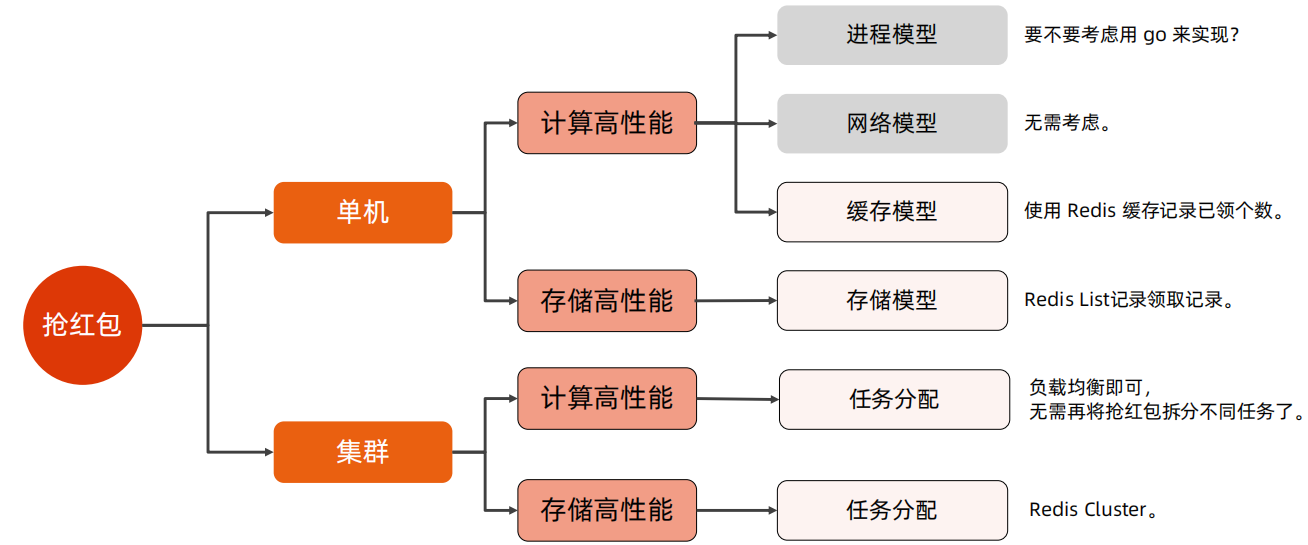
2、抢红包
在抢红包场景中,单机计算高性能,由于要做已领取人数的展示和控制,可以考虑使用redis缓存已领取个数;在单及存储高性能中,可以考虑使用redis记录领取记录,以提高后续的查看性能。由于单及存储使用的是redis,因此在集群存储高可用可以使用Redis Cluster
抢红包的高性能解决方案和架构图如下图所示
3、看红包
一般情况下,QPS的业务很大程度上会依赖TPS的业务,例如看红包,其依赖拆红包时存储的红包领取详情,因此这里只需要考虑任务分配即可,其他的都无需考虑。
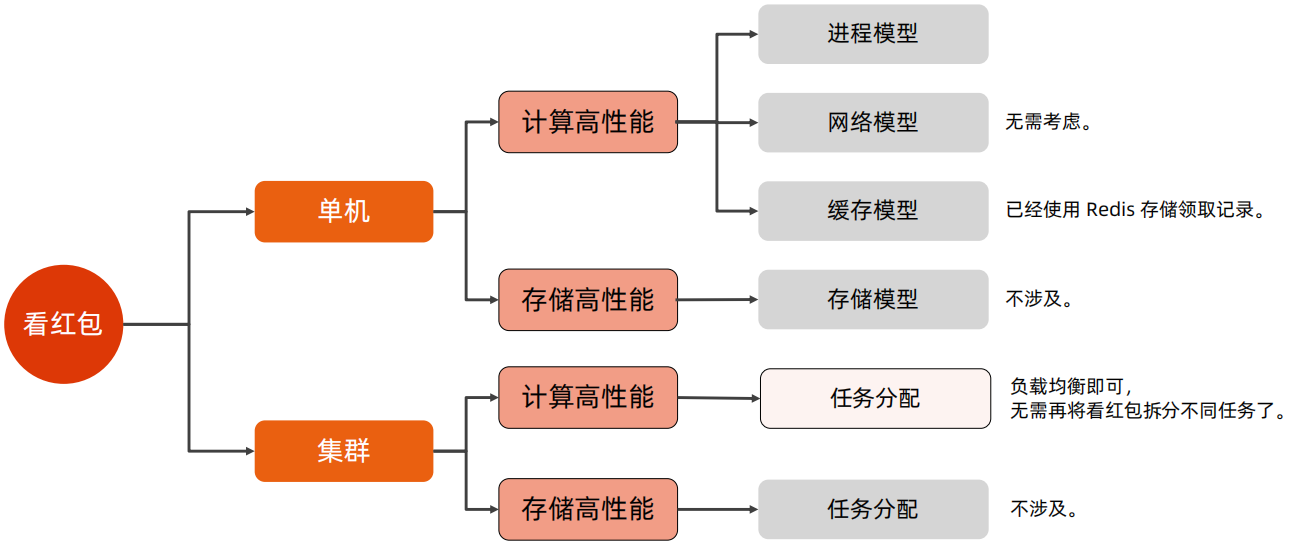
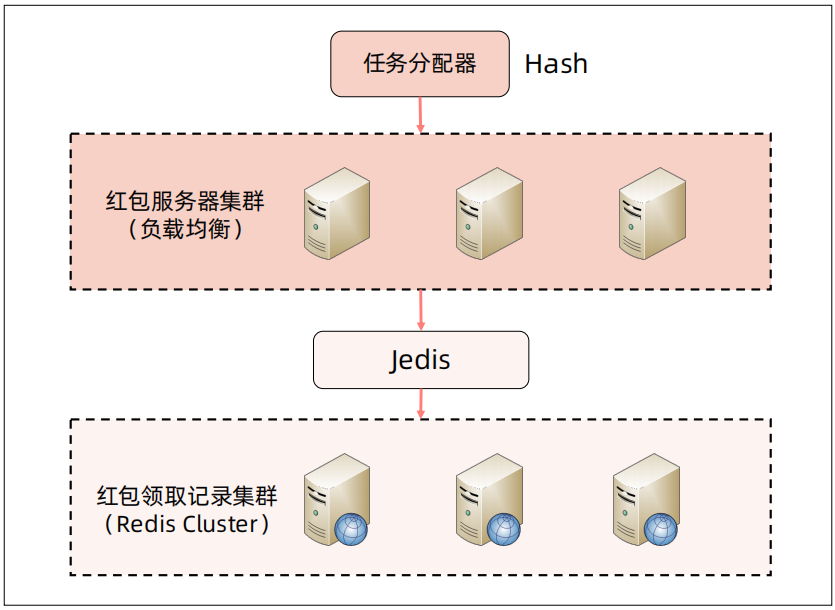
4、微信红包高性能总体架构
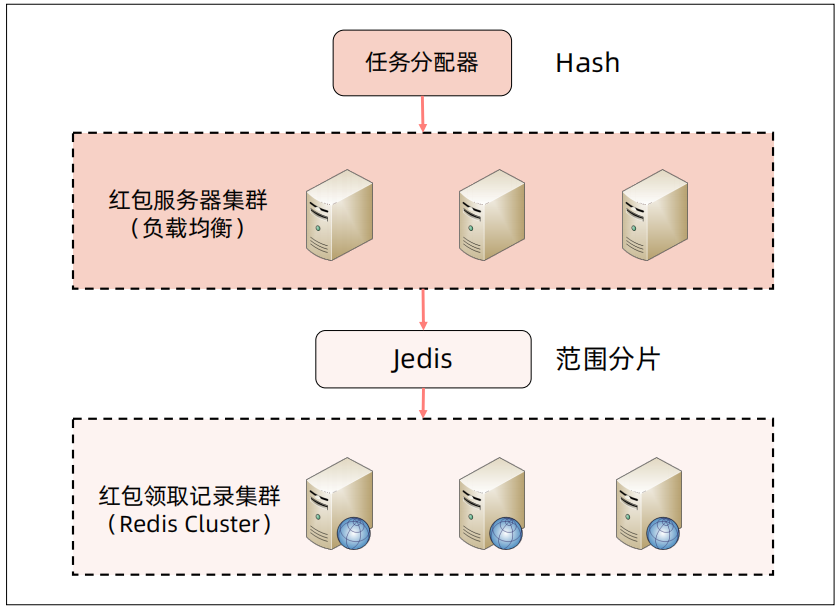
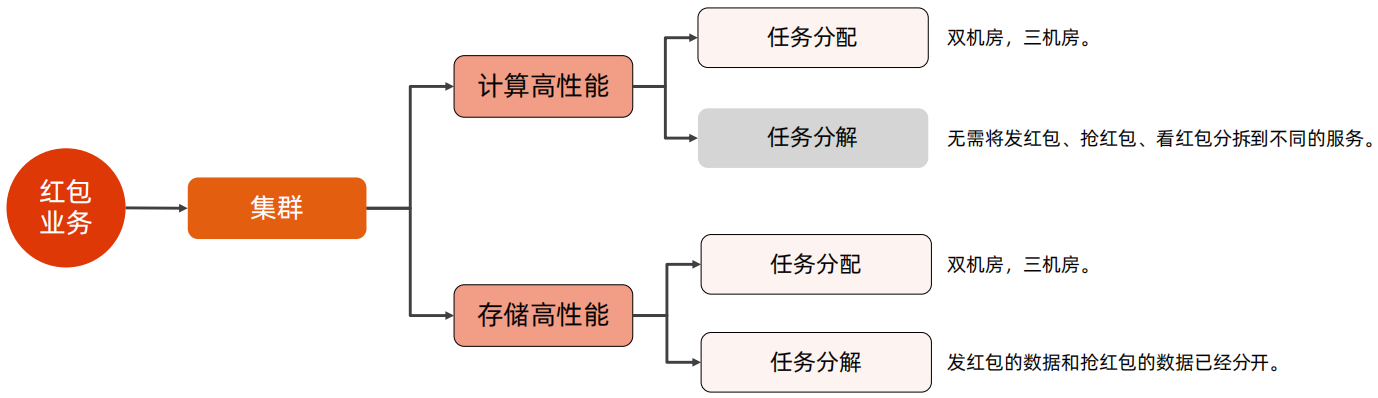
综上分析,红包业务在集群计算高性能主要考虑任务分配,使用双机房或三机房,由于红包业务总体业务比较简单,因此无需进行任务分解;对于集群存储高性能,任务分配上也采用双机房、三机房,在任务分解上,在上面的分析中,已经将发红包和抢红包的数据进行了拆分。
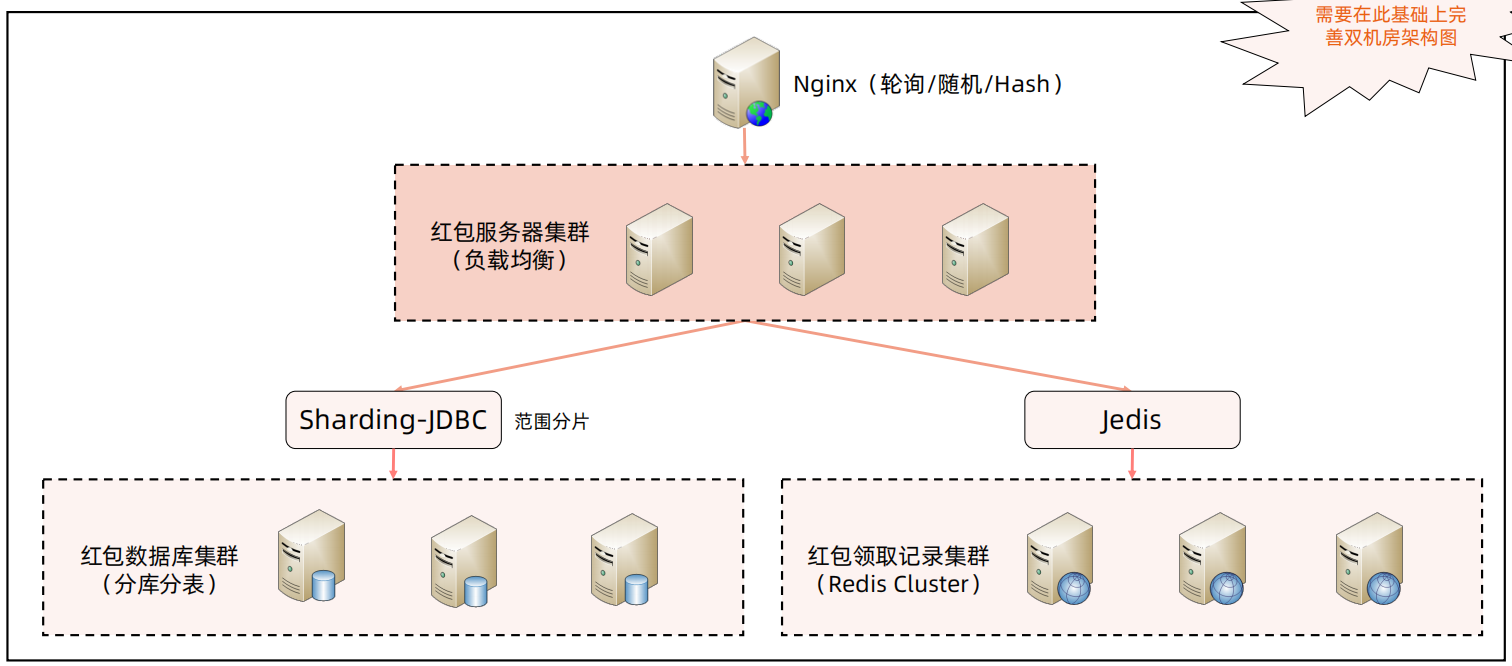
单机房部署如下图所示,可以使用Nginx进行负载均衡,发红包数据使用mysql进行分库分表,使用sharding jdbc进行数据操作,拆红包和看红包使用redis cluster存储数据,使用Jedis进行操作。
5、成本对于红包高性能架构的约束
在解决成本方面,主要有两个方向,一个是提升资源的处理能力,方法是优化和创新,一个是降低资源成本,方法是替换和共享。
提升资源处理能力:
优化:服务器是否可以改为Go语言,提高并发;在发红包的时候进行拆分;红包业务和其他业务共用服务器;
创新:开发红包数据库;弹性扩缩容
降低资源成本:
上面使用了mysql和redis两种存储,可以统一为一种来节约资源。
六、高可用案例分析--香港钱包
在做系统架构时,根据业务需求,需要预测性能指标和推断容忍度,预测的性能指标是我们设计高性能架构的基础,推断的容忍度是我们设计高可用架构的基础。
容忍度是指用户能够接受系统不可用的程度,包括不可用的时间和影响。
影响容忍度的维度有很多,文化、法律、用户、业务等等,都是影响容忍度的因素,比如香港的银行对接AlipayHK,如果晚上出故障,要到第二天9点上班才开始处理;内部运行系统能够接受2小时以内的服务不可用;支付业务可以容忍的时间是分钟级别的;游戏业务可以停服更新,这都是各个因素导致的容忍度不一致,对最终高可用架构设计带来的直观用户体验。
对于容忍度的一个排序: 生命 > 安全 > 金钱 > 付费 > 免费 > 内部
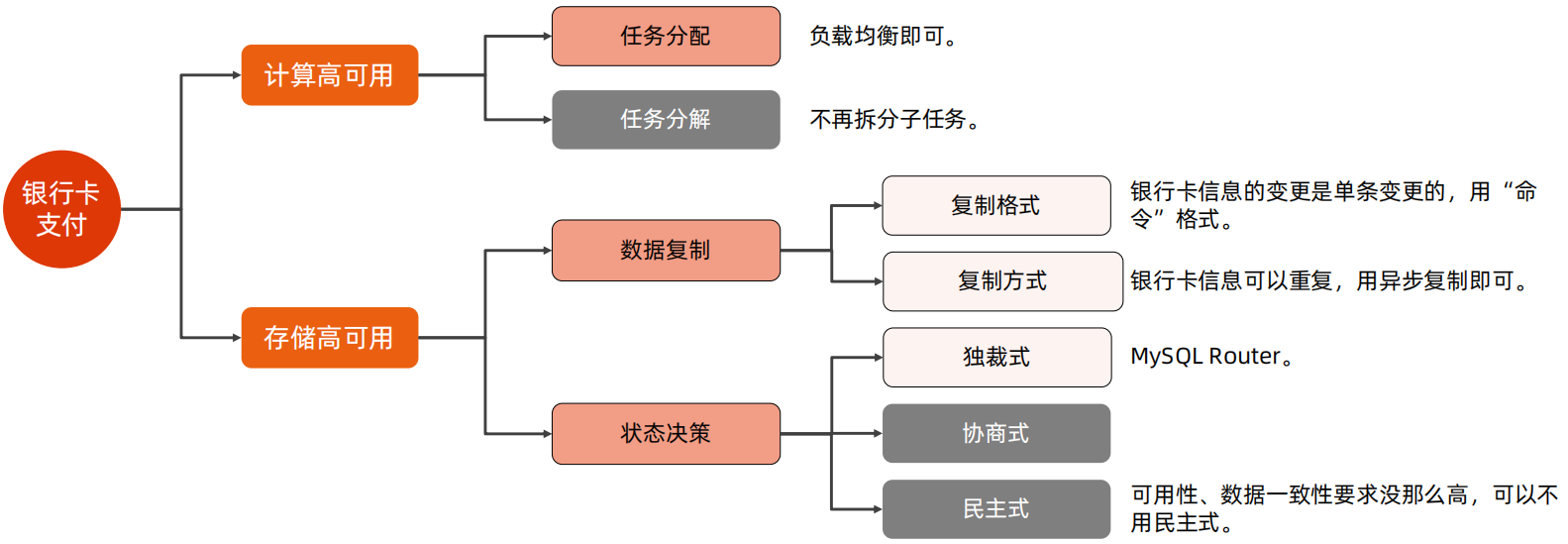
那么对于钱包业务来说,业务上可以分为余额转账、银行卡支付、运行后台等,对于余额转账、可以实时也可以不实时,银行卡支付,这种一般是用户向商家支付,这种是要求实时的,运营后台,内部人员使用,容忍度要低一些。这三个业务的容忍度排序为银行卡支付、余额转账、运营后台。
对于高可用的架构设计来说,按照高可用复杂度模型,逐个分析即可。
1、余额转账
余额转账本身就是一个单独的服务,因此在计算高可用只要考虑任务分配即可,无需考虑任务分解;在存储高可用中,余额的变更是单条变更的,因此复制格式可以使用命令模式,同时余额是强一致性的,因此需要采用半同步或者多数同步的方式进行数据复制;而对于状态决策,可以使用Mysql Router进行独裁式处理,也可以用分布式数据库OceanBase进行民主式处理。
余额转账高性能复杂度分析和架构如下所示:

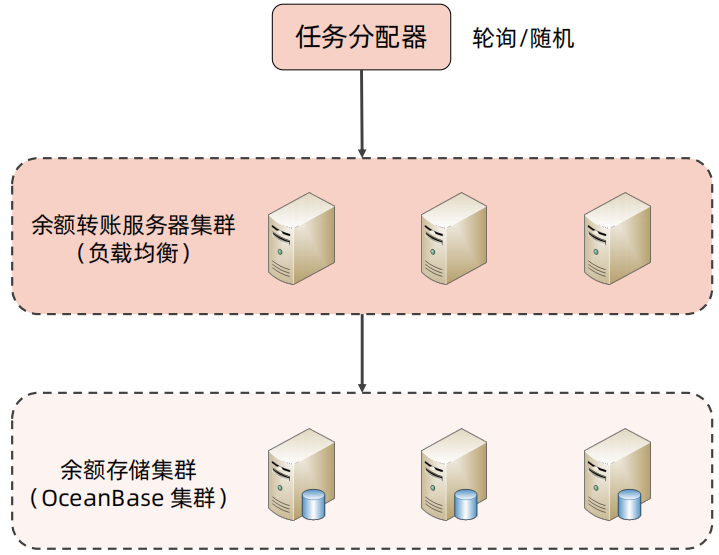
2、银行卡支付
银行卡支付和余额转账的主要区别就是银行卡支付的相关信息可以重复,且可用性和数据一致性要求没有那么高,基于这两个区别,银行卡支付的高可用复杂度中,数据复制方式可以采用异步复制,由于银行卡信息可以新增、删除、修改,并不要求高可用和高一致性,因此可以不选用民主式决策。
已按行卡支付高可用复杂度模型和架构图如下所示:
这里特别说明一点,在高可用复杂度模型中,已经表明不需要使用民主式决策,最终的架构图却选择了OceanBase,这是因为我们在做架构设计的时候,对于技术选型,也有看是否已经有了相关的组件,是否可以复用。在本案例中,余额转账已经使用了OceanBase,那么银行卡支付就不需要在引入单独的Mysql Router了,直接使用OceanBase即可。

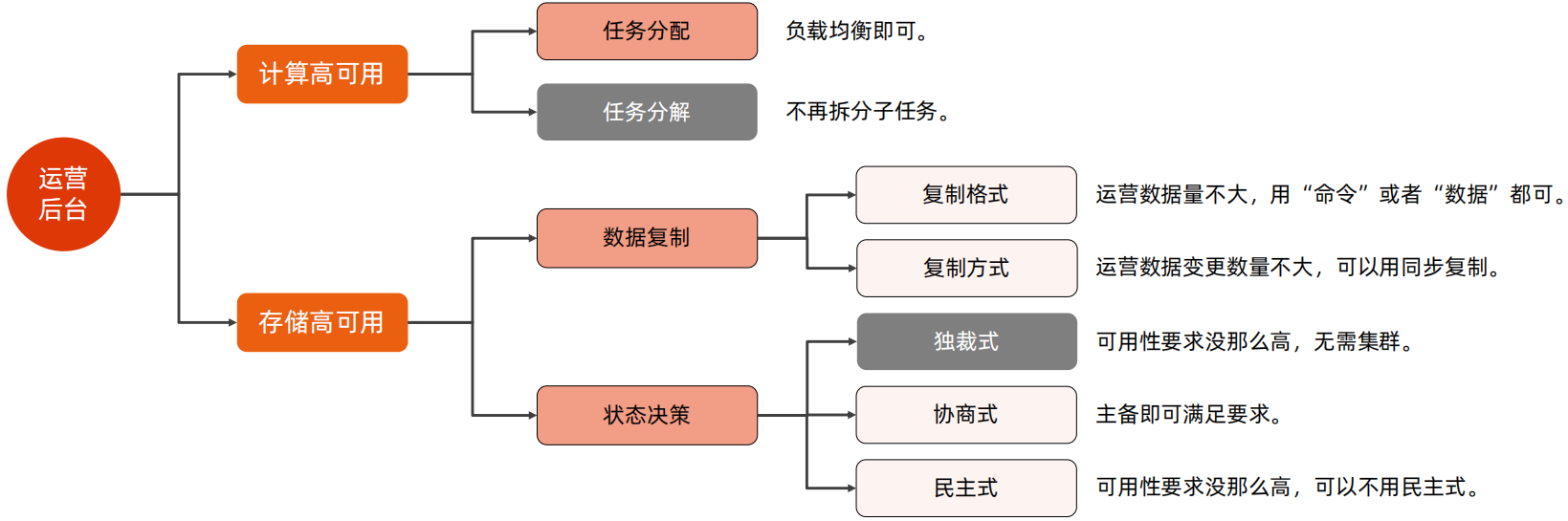
3、运营后台
运营后台和余额转账、银行卡支付最大的区别就是业务量小,兵器对于高性能要求不高,针对于这两点不同,数据复制时,由于数据量不大,因此数据复制格式采用命令或者数据都可以,复制方式也可以采用同步方式;对于状态决策来说,由于对高可用要求并不高,因此采用协商式即可满足需求,无需采用独裁式和民主式。

4、整体高可用架构
对于整体高可用来说,计算高可用中,由于香港面积小、人口少,任务分配可以使用双机房部署即可,无需采用两地三中心的部署方案,任务拆解其实就是将转账、支付、运营后台拆分为不同的服务;存储高可用的任务分配也是使用双机房,任务分解是将不同系统的数据分开存储。
香港钱包高可用复杂度分析和架构如下图所示:

5、成本约束
对于高可用架构的成本优化来说,可以使用成本更低的数据存储方案,例如使用Hadoop,也可以去IOE,上云等方法,但是高可用的本质是冗余,因此高可用架构在选型或优化时,不能使用高可用的资源替换低可用的资源。

那么对于香港钱包这个案例来说,如果老板觉得部署1000台服务器成本太高,如何进行优化?
是否可以使用Raft存储余额,或者去OceanBase,上云等,这些都是可以考虑的方案