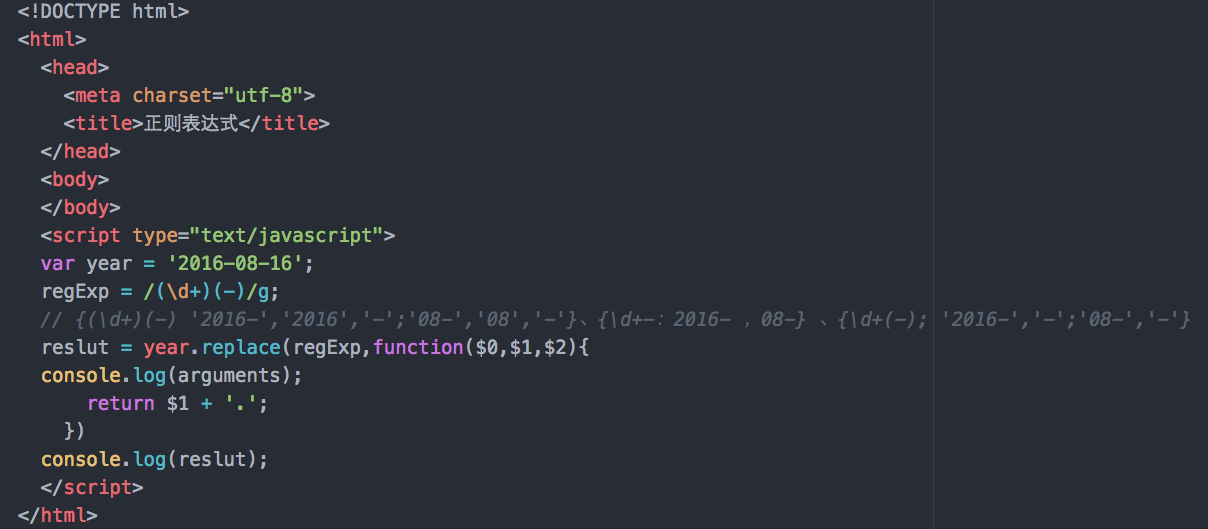
关于正则表达式,和很多前辈聊起这个知识点时,他们的反馈都比聊其他技术谦逊,而和很多刚入门的程序员讨论时甚至会有觉得你看不起他。
的确,正则表达式从通常的应用来看,的确不难,比如电话,邮箱等验证。语法,逻辑都算不上复杂,我之前也认为正则表达式也算不上什么高大上的技术。
但是,改变我看法的是,有一次有个前辈给我出了一个题:
将一串数字从后向前每隔三位打点,例如“100000000000000”;
var str = "100000000000000"; var reg = /(\B)(?=(\d{3})+$)/g; console.log(str.replace(reg,"."));
//输出结果:100.000.000.000.000
后来他跟我说,这个题是百度有一年校招的最后一个题,20分。
有人会说,这个并不是唯一的解法。
不错,这的确不是,但是只有这个解法当年百度给了满分,其他解法就算答案正确,基本上都只给了3~5分。
或许这个事情告诉了我们,结果并不是编程的“结果”,程序的核心价值应该是效率。
正则表达式在基础应用领域的确不难,但是在实际解决问题的时候能用正则表达式化繁为简的不见得有多少人能做得到。
我对正则表达式也只能说是做到了解,写这篇博客的原因是希望能与大家互动学习深入的掌握正则表达式,有什么关于正则表达式的问题大家可以在评论区留言交流,也希望大家多多分享关于正则表达式的实际应用,同时,我也用过这篇文章总结一些关于正则表达式的基础知识点,方便大家查阅和学习交流,有什么地方总结的不正确的地方还希望大家多多指正。
正则表达式的基础知识点:
1.转义字符
2.元字符
3.区间——方括号[]
4.重复限定符(量词)
5.边界与属性
6.分组与子表达式及反向引用
7.条件或
8.捕获与非捕获
9.零宽断言
10.贪婪与非贪婪
以上就是正则表达式的所有知识点,内容之少,但是其分量在编程领域之重不言而喻,所有的编程语言都有正则表达式就说明了这一点。
我的总结没有根据知识点的难易程度来排序,在写这篇博客之前我也参考了别人的博客,甚至我开始学习的时候很大程度也是靠读博客,但是我总感觉有些方式并不是很合适,大部分的正则表达式入门博客都是基于难易程度排序来讲,而且还拆分的很细,有的之间有很大关联的知识点被拆分,中间还隔了几个知识点,理解起来费劲。
这么来讲吧,我看过好几本研究关于记忆和学习的书,它们都有一个共通点,就是讲究知识的关联性,甚至在一些记忆大师的理论里,他们为了强记一些没有关联的信息时都会特意采用一些其他关联性的将其关联起来,来加强记忆,比如很出名的《记忆宫殿》,好了,有点扯远了,我只想告诉大家我这样的总结安排会更加适合理解学习。
1.转义字符:“\”
其实转义字符算不上完全的正则表达式的知识点。
将他放到这里来讲,而且还放到第一个来讲,是考虑到方便刚刚学习正则表达式的同学理解后面的知识点。
通俗的解释转义字符就是,通过“\”来表达我们不能按照正常字符表达方式的字符。
示例,如果在一个字符串中有一个双引号字符:
var mark= "ab\"cd"; console.log(mark); //输出ab"cd
反斜杠“\”在字符串中的作用就是,将它后面的字符变成该字符串的文本,而本身不作为字符串的实际字符。
转义字符,也就是反斜杠"\"在程序逻辑上,作用是清除字符本身自带的语法含义。上一个示例就是利用反斜杠清楚了双引号的语法含义。
//1.本身不作为字符串的实际字符 var mark = "ab\cd"; console.log(mark); //输出结果:abcd //2.如果反斜杠是字符串的一个字符? var backslash ="\\";
console.log(backslash); //输出结果:\ //3.一个字符串中包含了一个反斜杠“\”,恰好后面还跟了一个n或者r又或者0 //会出现什么情况,怎么解决 var n = "ab\ncd"; //输出结果:ab // cd var nn = "ab\\ncd"; //输出结果:ab\ncd var r = "ab\rcd"; //输出结果:abcd var rr = "ab\\rcd"; //输出结果:ab\rcd var zero = "ab\0cd"; //输出结果:ab cd var zeros = "ab\\0cd"; //输出结果:ab\0cd;
转义字符还有一个比较常用的实际开发应用,就是我们遇到一个结构比较复杂的字符,
但是字符串在通常的语法中不能换行,这时我们就可以采用转义字符来解决。
var inhtml = "\ <div>XXXXX</div>\ <ul>\ <li>XXX</li>\ <li>XXX</li>\ </ul>\ ";
关于转义字符暂时就解释到这里,很简单的一个知识点,算是一个前期铺垫吧。
2.元字符
| 元字符 | 说明 |
| . | 匹配除换行(\n)和回车符(\r)以外的任何字符 |
| ^ | 匹配字符串的开始位置。(边界部分详细介绍) |
| $ | 匹配字符串的结束位置。(边界部分详细介绍) |
| \w | 匹配单词字符,即0-9A-z_;(区间部分详细介绍) |
| \W | 匹配非单词字符,即除了\w以外的任何字符(区间部分详细介绍) |
| \d | 匹配数字,即0-9;(区间部分详细介绍) |
| \D | 匹配非数字字符,即除了\d的任何字符(区间部分详细介绍) |
| \s | 匹配空白字符 。(区间部分详细介绍) |
| \S | 匹配非空白字符。(区间部分详细介绍) |
| \b | 匹配单词边界, 即单词的前后两个位置。(边界部分详细介绍) |
| \B | 匹配非单词边界,即不是单词的前后两个位置。(边界部分详细介绍) |
| \0 | 匹配null,在字符串中采用转义形式,\0实现的是一个空格的效果。(根据转义字符,参考\n的详细说明理解) |
| \n |
匹配换行字符。 在字符串中出现了\n如:var str = "ab\ncd";匹配字符串str的正则可以写成/ab\ncd/或者/\w\w\n\w\w/; 如果通过console.log输出的字符串是:ab\ncd,我们可以通过转义字符推导出字符串为"ab\\ncd";相匹配的字符串也要写成/ab\\ncd/; |
| \f | 匹配换页符。(根据转义字符,参考\n的详细说明理解) |
| \r | 匹配回车符。(根据转义字符,参考\n的详细说明理解) |
| \t | 匹配制表符。(根据转义字符,参考\n的详细说明理解);(\t同等于在编辑文本时输入TAB键,但是在字符串中输入TAB会被编译成空格,要想在字符串中获得实际的TBA键入一样的效果就是在字符串中写入\t,所以就有了这个反向字符) |
| \v | 匹配垂直制表符。(根据转义字符,参考\n的详细说明理解) |
| \XXX | 匹配以八进制数XXX规定的字符 。 |
| \Xdd | 匹配以十六进制数dd规定的字符 。 |
| \uXXXX | 匹配以十六进制数XXXX规定的Unicode字符。 |
3.区间——方括号[]
正则表达式提供一个元字符“方括号”(也通常称“中括号”)来表示一个字符的取值范围。
限定一个字符为0~9可以写成[0-9]; -->即为数字字符,也可以用“\d”表示。
限定一个字符为a~z,即为小写字母可以写成[a-z];
限定一个字符为A~Z,即为大写字母可以写成[A-Z];
所以如果一个字符为任意字母和数字可以表示为[a-zA-Z0-9]。
限定一个字符是指定的几个字符中的任意一个可以写成[a%M],即表示这个字符只能是“a”,“%”,"M"其中的一个。
也可以通过[^]的方式反向取值,即表示除了罗列的字符以外的任意字符。
假设一个字符不是"a","b","c"的任意字符可以表示成[^abc]。
在前面的元字符中,很多都拥有类似功能,其实际也是区间的一种表达形式,下面我就用区间的形式解析出来,供大家参考。
1 \w === [0-9A-z_]; 2 \W === [^\w]; 3 \d === [0-9]; 4 \D === [^\d]; 5 \s === [\t\n\r\v\f]; 6 \S === [^\s];
4.重复限定符(量词)
| 语法 | 说明 |
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
在没有重复限定符的情况下,正则表达式就是一个累赘,所以在前面一直没有真正意义的写过示例演示。
有了重复限定符之后,应用一些实例来理解正则表达式:
1 //匹配11位数的手机号码 2 //不使用重复限定符的情况下 3 /^1\d\d\d\d\d\d\d\d\d\d$/ 4 //使用重复限定符 5 /^1\d{10}$/ 6 7 //匹配八位数的QQ号码 8 /^\d{10}$/ 9 10 //匹配银行卡号14至18位的数字 11 /^\d{14,18}$/ 12 13 //匹配任意长度的单词 14 /\b\w+\b/
5.边界与属性
在解析边界与属性之前,我们先要了解一下正则表达式的匹配原则。
正则表达式代表的是一个字符串中的某个片段的规律,
当使用正则表达式的方法对一个特定的字符进行匹配的时候,
正则表达式会对字符的每个字符从前往后逐个匹配。
| 属性 | 说明 |
| g | 全局匹配 |
| i | 忽略字母大小写 |
| m | 多行匹配 |
关于g的全局匹配逻辑我觉得用下面一段代码更容易解释,也更清晰明了。
1 var str = "a1b2c3d"; 2 var reg = /\d/; 3 //匹配到的结果是:1 4 var reg1 = /\w/g; 5 //匹配到的结果是:1,2.3 6 7 var str1 = "a123b456c789d"; 8 var reg2 = /\w+/; 9 //匹配结果是:123; 10 var reg3 = /\w+/g; 11 //匹配到的结果是:123,456,789;
以上的代码说明了g属性可以使字符串中,符合条件的所有片段匹配出来。
这时候有的同学就会说23,56,89也符合\d+的形式,是的,从正则表达式来讲的确符合条件,
但是,匹配原则不会重新匹配已经被匹配的字符。
接下来解释,关于边界内容,先看以下示例:
字符串12345678符合/\d{8}/,如果使用这样的一个正则表达式来验证8位数的字符串是否合理呢?
如果出现字符串123456789,/\d{8}/也符合匹配条件,但是他却不是8位数的字符串。
这时候我们就需要引入边界来解决这个问题:
var str1 = "12345678"; var str2 = "123456789"; var reg = /^\d{8}$/; //字符串str1能被成功匹配 //还可以使用下面的正则表达式进行匹配验证 var reg3 = /\b\d{8}\b/ //实质上\b是表示一连串符合\w的字符的前后位置 //元字符中\w的官方说明就是单词字符,其中包括了[A-z0-9_] //所以我们可以通过以下正则表达式来获取一段英文的所有单词 var reg4 = /\b\w+\b/g;
以上代码说明了:^ 表示字符串的开始位置;$ 表示字符串的结束位置; \b表示单词的开始或结束位置。
关于边界就还剩下两个问题:
a.^在正则表达式中存在多重含义:一种是在区间内作为开头表示非的意思,在边界上表示字符串的起始位置。
b.非单词边界指的是什么?
//有如下字符串 var str = "this is my phone"; //需求:判断这段英文中有没有单词中包含is,但不是独立的一个is单词。 var reg = /\Bis/g; //非单词边界意思就是不是单词的开头和结尾处
关于属性,还有"i"和"m"分别具备什么功能?
//有需求:在一段英文中匹配到is这个单词,并且忽略大小写 var reg = /\b[iI][sS]\b/g; //若采用i属性忽略大小写就可以写成 var regi = /\bis\b/ig; //如果有这样一串字符串 var str = "ab\nacd\naef"; var regs = /^a\w+/g; //匹配结果是:ab var regm = /^a\w+/gm;
//匹配结果是:ab,acd,cef;
i属性忽略字母大小写就不再多做解释了。
m属性可能会有很多朋友不是很清楚,
在这里如果要严格的理解"^"这个符号就是一行字符串开头的意思。
所以,通过m属性匹配上面示例的结果就会有三个。
(其实主要的问题是在于对“^”符号的的理解误区,通常我们在正则表达式内,这个符号在边界的意义都理解为字符串的开头,其实不然,准确的说是一行字符串的开头。)
6.分组与子表达式及反向引用
关于分组对于表达式至关重要,后面的几个知识点都会围绕分组展开。
如果只是分组,它本身是一个非常简单易懂的知识点:
1 var str = "abcdef"; 2 //用正则表达式分组的形式按每组两个字符进行匹配 3 var reg = /(ab)(cd)(ef)/;
以上示例中的正则表达式实际的匹配结果与/abcdef/没有任何区别,都是将整个str字符匹配出来。
但是,本身看似没有任何意义反而成就了他的价值,就想HTML的div标签一样,实际没有任何特性的容器标签却成了HTML中最重要的一个标签。
不扯远了,回到正则分组的本身,正则表达式有了分组,就像碳元素在高温环境下有了氧气;
因为分组,产生了子表达式:
在上面的示例中,正则表达式中的分组产生了三个子表达式:(ab),(cd),(ef)
//子表达式再上一个示例中没有什么价值 //如果有以下字符串(大驼峰命名规则) var str = "AbafdcDfdefGhfdi"; //如果需要用正则表达式来验证的话,正则可以写成 var reg = /^([A-Z][a-z]+)+$/
验证大驼峰命名法的字符串,就是应用了分组的子表达式重复匹配来简化代码。
从这里开始,感觉正则表达式要走上风骚路线了,接下来看看反向引用
1 //查找以下字符串中连续重复出现的单词,并且忽略大小写 2 var str = "Is is the cost of of gasoline going up up?"; 3 var reg = /(\b[a-z]+\b) \1/ig; 4 5 //匹配连续出现的字母组合的字符串片段 6 var str1 = "abcabcabc"; 7 var reg1 = /^(\w{2})\1+$/; 8 9 //匹配一下形式的字母组合的正则表达式 10 var str2 = "aabb"; 11 var reg2 = /(\w)\1(\w)\2/g;
刚接触反向引用事,看到上面的示例,我想每个人都会有这样的疑问:\1和\2是什么意思?
这里的1和2所表示的就是第一个子表达式和第二个子表达式通过匹配获取到的对应的“字符串片段”的引用。
以最后一个示例为例,匹配过程可以将其拆分成两个步骤:
第一个步骤是子表达式匹配获得匹配结果:/(\w)a(\w)b/; ——>子表达式优先匹配,获取匹配到的具体字符串片段,并传给引用自己的引用。
第二个步骤就是将第一个步骤获取到的具体的表达式与字符串匹配。
(提供一个记忆理解的方法:反向引用这个技术名称别只看着高大上,其实本质上已经通过语义化向我们传递了很多信息,数字n表示第几个子表达式,即为引用值。
而反向即为将数字原本在正则表达式中表示的是一个字符,通过转义字符反转为一个引用对象;反向还有的第二层含义就是数字引用的不是子表达式的本身,
而是通过子表达式匹配的对应字符串片段。)
7.条件或 —— |
条件或其实与通常编程中的双竖线“||”是一个意思,只不过在正则表达式中只要写一个竖线“|”。
示例说明:
//我们的手机号码不同的运营商,开头的三个数字都不同,而且每个运营商下都有好几个不同的开头数字。 //例如联通旗下有:130/131/132/155/156/185/186/145/176 //如果业务需求是要匹配所有的联通手机号码。请看下列代码: var reg = /^(130|131|132|155|156|185|186|145|176)\d{8}$/;
很简单的一个知识点,但是要借助分组来表示,所以就留到这里来讲了。
8.捕获与非捕获
在解析捕获与非捕获前,我想先在这里添加一些内容,帮助更好的理解这一部分知识点。
就是基于JavaScript关于正则表达式的一个操作方法:
JavaScript的RegExp对象的exec()方法:
不过在这里暂时不对方法的所有内容进行解析,只解析部分与捕获相关的内容。
1 //还是延用分组的示例,毕竟捕获是基于分组的 2 var str = "abcdef"; 3 //用正则表达式分组的形式按每组两个字符进行匹配 4 var reg = /(ab)(cd)(ef)/; 5 //使用exec()方法获取到匹配结果 6 console.log(reg.exec(str)); 7 //匹配结果是:["abcdef", "ab", "cd", "ef", index: 0, input: "abcdef", groups: undefined]
在这个匹配结果里,类数组的第一个元素就是正则表达式匹配到的内容。
第二个元素:“ab”是第一个子表达式的匹配结果
第三个元素:“cd”是第二个子表达式的匹配结果
第四个元素:“ef”是第三个子表达式的匹配结果
先不讨论,继续看以下示例
//在上面的示例基础上,正则表达式修改成 var reg = /(ab)(?:cd)(ef)/; //使用exec()方法获取到匹配结果 console.log(reg.exec(str)); //匹配的结果是:["abcdef", "ab", "ef", index: 0, input: "abcdef", groups: undefined]
这回的匹配结果发生了一个小小的变化。
第二个子表达式的前面添加了“?:”,让匹配结果中没有出现第二个子表达式的对应元素;
但是整个正则匹配结果,也就是类数组的第一个元素没有受到影响,还是和上一个示例的匹配结果完全一致。
以上示例通过exec()方法展现出来的结果,就是捕获与非捕获的结果。
捕获是正则表达式分组的一个特性,他会将每个分组即子表达式匹配到的结果提取出来,即为捕获。
捕获产生了数据组,我们就可以通过反向引用的方式在正则表达式中,通过捕获数据组的“”键“”引用捕获值。(反向引用实现的底层原理)
而非捕获就是在子表达式前面加上了“?:”,表示该组为非捕获组,非捕获组匹配的结果不会被提取,但是该组的匹配功能依然存在。
看到以上的总结,大家可能视乎懂了捕获与非捕获,但是还是不知道捕获与非捕获有什么用途。
请看以下示例:
var str = "aa11aa11aa11"; var reg1 = /((aa)(11))+/; var reg2 = /(?:(aa)(11))+/; console.log(reg1.exec(str)); //匹配结果是:["aa11aa11aa11", "aa11", "aa", "11", index: 0, input: "aa11aa11aa11", groups: undefined] console.log(reg2.exec(str)); //匹配结果是:["aa11aa11aa11", "aa", "11", index: 0, input: "aa11aa11aa11", groups: undefined]
上面的示例所展示的内容,可以看到一个区别,
而恰恰是一个区别可以帮助我们解决一个巨大的困扰。
在前面的总结中我们可以知道有了捕获数据可以被引用,
但是在上面的这个示例的时候,当分组被嵌套的时候,
“键”所对应的“值”就不会那么好对应了,比如上面示例的第一个匹配结果,如果在正则表达式中需要引用(aa)匹配的值,就是“\2”;
非捕获也就是让被标注为非捕获组的对应匹配值不会出现在捕获数据内。
很多朋友觉得捕获很难,我并不觉得,写了这么一大段我自己反而觉得累赘,看着就累,如果可以我觉得有下面一句话就可以了。
被标注非捕获的分组,所匹配的字符串片段不能反向引用。
9.零宽断言
零宽与断言这一部分,真的不难好吗?
有多少人困在这一部分,点赞举手,我来告诉你们如何不难。
我觉得这部分,难度不在知识点,而是在知识点的专业名称,我看到的和听到了就不下三种。
所以我想先不解释理论和原理,直接看看怎么用,然后再解释原理。
1 //如有需求:找到一个的开桑塔纳的车主(且名字为三个字) 2 var str11 = "李小明开桑塔纳"; 3 var str12 = "王小明开福克斯"; 4 var reg1 = /^.{3}(?=开桑塔纳)/; 5 console.log(str11.match(reg1)); 6 console.log(str12.match(reg1)); 7 //输出结果:[李小明] 8 //输出结果:null 9 10 11 //有需要如:查找电话号码,电话号码前面的字符是“电话:”,但不能匹配该字段。 12 var str21 = "电话:15177775555"; 13 var str22 = "金额:11111111111"; 14 var reg2 = /(?<=电话:)1\d{10}/g; 15 console.log(str21.match(reg2)); 16 console.log(str22.match(reg2)); 17 //输出结果:[15177775555] 18 //输出结果:null 19 20 //全局忽略大小写,查找后买没有all的is 21 var str3 = "Is this all there is"; 22 var reg3 = /is(?! all)/gi; 23 console.log(str3.match(reg3)); 24 //输出结果:["Is", "is"] 25 26 27 //假设有以下两个字符串,需要用正则判断不“美国芯片” 28 var str41 = "美国芯片"; 29 var str42 = "中国芯片"; 30 var reg4 = /(?<!美国)芯片/; 31 console.log(str41.match(reg4)); 32 console.log(str42.match(reg4)); 33 //输出结果:null 34 //输出结果:["芯片", index: 2, input: "中国芯片", groups: undefined]
我现在可以告诉你,零宽断言已经学完了,可能出现的四个特例在上面的实例中全部展示出来了。
下面给大家介绍原理、特例(?=,?!,?<=,?<!)、及专业名词。
在解释原理前,我们先来看看特例:
xx(?=exp)表示查找xx,这个xx的后面必须跟着exp
xx(?!exp)表示查找xx,这个xx的后面不能跟着exp
(?<=exp)xx表示查找xx,这个xx的前面必须是exp
(?<!exp)xx表示查找xx,这个xx的前面不能出现exp
零宽与断言的含义(即这两个专业名词描述了什么东西)
断言:所谓断言,与通俗的表达是一回事,表示肯定什么的意思。这正则表达式内,断言就是表达“xx”字符串片段的前后肯定会出现什么样的情况。
零宽:这个名称也是语义化的一个专业名称,大家发现所有四个特例都是以分组的方式写在正则表达式内,
但是这样的分组不执行正则匹配,它的作用只是一个判断条件。也就是它不占用匹配的字符片段。
说了这么多,出一个小小的题,大家一起熟悉一下零宽断言:用正则表达式匹配获取一个网页的标题名称。


1 var str = "<title>他乡踏雪的主页</title>"; 2 var reg = /(?<=<title>).*(?=<\/title>)/g; 3 console.log(str.match(reg));
接下来,就来解决名称的问题吧。这个问题就是个奇葩!
| 正则表达式零宽断言的特例 | 第一类名称(参考百度百科) | 第二类命名 |
| XX(?=exp) | 零宽度正预测先行断言 | 正向前瞻 |
| XX(?!exp) | 零宽度负预测先行断言 | 负向前瞻 |
| (?<=exp)xx | 零宽度正回顾后发断言 | 正向后瞻 |
| (?<!exp)xx | 零宽度负回顾后发断言 | 负向后瞻 |
最后关于零宽断言,其实我也还有点疑惑,在很多博客和教程上见过说,js的正则不能用(?<=)和(?<!),我使用的是Chrome浏览器:版本 69.0.3452.0做的测试,没毛病,还望路过的大神指点一下,是不是真的有那个浏览器不兼容这两个零宽断言的特例。
10.贪婪与非贪婪
这知识点几乎是正则表达式最冷门的一个,因为在日常开发中非常少用,特性本身也不太好驾驭。
但是别小看它,千万别小看,我最后会给一个示例给大家看,你们就会明白。
那到底什么是贪婪模式和非贪婪模式呢?先看一个示例:
1 var str = "abcaxcd"; 2 var reg = /ab.*c/; 3 var reg1 = /ab.*?c/; 4 console.log(str.match(reg)); 5 //匹配到的结果是:abcaxcd 6 console.log(str.match(reg1)); 7 //匹配到的结果是:abc
看到上面的示例后,两个正则表达式的差别就是在量词星号*的后面多了一个问号?
这也就是贪婪与非贪婪的区别:
贪婪模式就是仅量词的最大值去匹配最多的相符的字符。
非贪婪模式就是不管量词的最大范围有多大,只要是非贪婪模式就尽可能的少匹配字符。
但是,有一种例外:
var str = "abcaxcd"; var reg = /ab.*?d/; console.log(str.match(reg)); //匹配结果是:abcaxcd
这种例外就是,当一个执行非贪婪模式匹配的字符后面,有一个匹配字符可以字符,贪婪模式会延伸,直到后面的字符被匹配到的前面结束匹配。
记住,一定是后面的字符有可能被匹配到的情况下,否则匹配结果为null
接下来干点正事,关于贪婪模式与非贪婪模式的语法是应该正式的介绍一下了:
| 贪婪模式的量词表示 | 非贪婪模式的量词表示 |
| n* | n*? |
| n+ | n+? |
| n? | n?? |
| n{x} | n{x} ? |
| n{x,} | n{x,} ? |
| n{x,y} | n{x,y} ? |
最后兑现承诺,放大招,贪婪和非贪婪组合断言特性,看看以下示例:
1 //有需求是:保留以下HTML文档中的innerText和hr标签 2 var str = "<p><a href='http://www.cnblogs.com/rubylouvre/'>Ruby Louvre</a></p><hr/><p>by <em>司徒正美</em></p>"; 3 var reg = /<(?!hr)(?:.|\s)*?>/ig; 4 console.log(str.replace(reg,"")); 5 //打印结果是:Ruby Louvre<hr/>by 司徒正美
11.正则的一些方法及支持正则的String的方法:
1 //RegExp的方法 2 let str = "Alan Turing's short and extraordinary life has attracted wide interest."; 3 let r = /(?<=^|\b)[\w']+(?=\b|$)/ig; 4 let reg = new RegExp("(?<=^|\\b)[\\w']+(?=\\b|$)",'gi'); 5 let re = /\w+('\w+|)/ig; 6 //检索 7 console.log(str.match(reg)); 8 console.log(str.match(re)); 9 10 //正则示例对象上的方法 11 //compile:将RegExp转换成正则字符串格式,或者将正则表达式转换成字符串格式 12 console.log(r.compile(r)); 13 console.log(r.compile("(?<=^|\\b)[\\w']+(?=\\b|$)",'gi')); 14 15 //exec:检索匹配字符串中符合正则表达式的匹配值,只能匹配第一个,不能匹配全局 16 console.log(r.exec(str)); 17 18 //test:测试一个字符串中是否有匹配正则的内容,如果有则返回true,否则返回true 19 console.log(r.test(str)); 20 21 //toString:将正则对象本身转换成正则表达式的字符串格式 22 console.log(r.toString()); 23 24 //支持正则表达式的String对象的方法 25 //search:检索字符串中指定的子字符串(放回检索到的第一个符合正则的子字符串起始下标) 26 console.log(str.search(r)); 27 28 //match:在字符串内检索指定的值,返回一个数组 29 console.log(str.match(r)); 30 31 //replace:替换字符串内指定的内容,返回替换后的字符串 32 console.log(str.replace(r,"正则")); 33 34 //split:按照指定的内容将字符串分割成一个数组 35 console.log(str.split(r));
推荐相关博客: