正则表达式是对字符串操作的逻辑公式,用事先定好的一些特定字符组成一个 "规则字符串 ",在用 "规则字符串 "对字符串进行过滤。
ECMAScript 通过RegEx
正则表达式是对字符串操作的逻辑公式,用事先定好的一些特定字符组成一个"规则字符串",在用"规则字符串"对字符串进行过滤。
ECMAScript 通过RegExp 类型来支持正则表达式
目的: 给定的字符串是否符合正则表达式的过滤逻辑,称为:匹配;
可以通过正则表达式,从字符串中获取我们想要的特定部分,称为:查找;
正则表达式的三个功能:
1、快速匹配制定字符串;
2、替换遵照正则表达式规则的字符串;
3、在目标字符串中筛选指定的字符串
正则表达式的语法:
正则表达式就是由普通字符(例如:a~z)和元字符(特殊字符)组成的文字模式,该模式描述在查找文字主体时待匹配的一个或多个字符串,正则表达式作为一个模版,将某个字符串模式与所搜索的字符串进行匹配。
创建正则表达式对象(正则表达式:regular expression)
var regExp = new RegExp(pattern, attributes);
构造正则表达式对象时使用的构造函数有两个参数
1、参数 pattern 是一个字符串,指定了正则表达式的模式或其他正则表达式;
2、参数 attributes 是一个可选的字符串:共三种模式,这三种模式可以组合使用
i:不区分大小写;
g:全局查找,整个目标字符串范围内;
m:多行查找;
正则表达式的简写形式:字面量形式
双斜杠中包括的就是要被匹配的文字
双斜杠后面是模式组合
var regExp = /a/gi;
正则表达式对象提供的test方法用于检测参数字符串是否有符合表达式模板的文字,如果有就返回true,没有则返回false;
例如:
var str = "love me love my dog";
reg = new RegExp("love","gi");
regExp = /love/gi;
1、如果要匹配目标字符串是否以love开头,需要通过元字符^(脱字符)来匹配,匹配开头是否包含正则表达式模板
regExp = /^love/gi;
2、要匹配结尾通过元字符$来匹配
regExp = /^love$/gi;
3、 \s 是空白符,(s:spance)属于转义字符,类似于\n(换行符);
regExp = /love\s/gi;
4、匹配的目标要能够成单词,可以使用\W(W要大写);
regExp = /love\W/gi;
console.log(reg.test(str));
5、如果要匹配数字,则需要使用到转义字符\d, d:digital 即数字的意思
regExp = /love\d/gi;
regExp = /[a-z].\d+\W/gi;
6、元素中的竖线 |
str = "22334455";
regExp = /22|55/g;
console.log("|元字符:" + regExp.test(str));
7、重复类 设定连续重复次数 {}
str= '211111161';
连续重复次数{}
regExp = /1{7}/g; //设定连续重复7次
最少连续重复次数{2,}
regExp = /1{2,}/g; //设定最少连续重复2次
最少连续重复2次,最多4次{2,4}
regExp = /1{2,4}/g;//设定最少连续重复2次最多4次
8、 元字符 + 的意义为匹配目标至少连续出现一次,等效于{1,};
regExp = /1+/g;
9、元字符?,最多出现一次,等效于{1,0}
regExp = /1?/g;
10、字符类中的[];
regExp = /[1]/g; //匹配方括号内的任意一项
11、连字符- 匹配0到4范围内的任意数字
regExp = /[0-4]/g;
12、^和[]配合还有除外的意思
str = 'aaa123bb123add123';
regExp = /[^123]/g; // 除了123之外的其他项都被匹配
str = "abcFhGlz";
regExp = /[a-z]/gi;
regExp = /[a-zA-Z]/g; // 匹配字母包括大小写
13、匹配字符串中的汉字
str = 'today 是周二';
regExp = /[\u4e00-\u9fa5]+/g;
console.log(str.match(regExp));
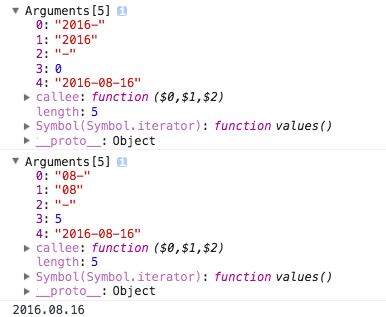
事例:将2016-08-16中的短线替换成点